Fudgets --
Purely Functional Processes
with applications to
Graphical User Interfaces
Magnus Carlsson
Thomas Hallgren
Department of Computing Science
Chalmers University of Technology
Göteborg University
S-412 96 Göteborg, Sweden
Göteborg 1998
http://www.cs.chalmers.se/~hallgren/Thesis/
Department of Computing Science
Göteborg 1998
The main result of this thesis is a method for writing programs with graphical user interfaces in purely functional languages. The method is based on a new abstraction called the fudget. The method makes good use of key abstraction powers of functional languages, such as higher order functions and parametric polymorphism.
The Fudget concept is defined in terms of the simpler concept of stream processors, which can be seen as a simple, but practically useful incarnation of the process concept. Programs based on fudgets and stream processors are networks of communicating processes that are built hierarchically, using combinators. Communication is type safe. The basic combinators provide serial compositions, parallel compositions, and loops. A key difference between previous work on stream processing functions and our approach is that we deliberately abstract away from the streams. We obtain a system that can be implemented deterministically, entirely within a purely functional language, but which also makes it possible to take advantage of parallel evaluation and indeterminism, where such is available within the functional language. The purely functional approach makes processes first class values and makes it easy to express process cloning and process migration.
The practical viability of the approach is demonstrated by the Fudget library, which is an implementation of a graphical user interface toolkit in the purely functional language Haskell, together with a number of small an large applications that have been implemented on top of the library.
In addition to GUI programming, fudgets are suitable for other forms of concurrent I/O programming. We demonstrate how client/server based applications can be we written, with type safe communication between client and server. We show a web browser as an example where GUI programming and network communication come together.
We view fudgets as one example of a more general combinator-based approach to promote the idea that a functional language together with combinator libraries is a good alternative to using less expressive languages propped by application-specific tools. We describe a set of combinators, reminiscent of parsing combinators, for building syntax-directed editors.
Ideas and implementation work by a number of people have increased the usefulness of the Fudget library. Jan Sparud's space-leak fix in an early version suddenly made it possible to run fudget programs until somebody pulls the plug. Jan also implemented an initial version of the name layout mechanism. Lennart Augustsson's integration of the Xlib interface with HBC's runtime system made fudget programs easier to use and more efficient. John Hughes invented the default parameter simulation, which made fudget programming much more pleasant.
The department of Computing Science has not only provided a wealth of academic stimulus, but also technical and administrative support that has shown a flexibility of unusual quality. Especially, we want to thank Christer Carlsson, Görgen Olofsson, Marie Larsson, Per Lundgren, and Hasse Hellström.
Part of our work has been supported by NUTEK.
But at that time, the three functional programmers were beginning to use graphical workstations instead of simple text terminals. They were unhappy about the fact that they did not have a way to write programs with graphical user interfaces in their functional language.
The two younger of the three functional programmers decided to start working on a solution to this problem. The older of the three was a bit skeptical and said that it would probably not be possible to obtain a solution that was efficient enough to write ``real'' programs with.
The two younger implemented an interface that allowed LML programs to talk to the X Windows system. They also designed an abstraction to be used as the basic building block when constructing graphical user interfaces. This abstraction was later named the Fudget.
The first X Windows interface was implemented as a separate program that the LML program could talk to via ordinary text I/O. The oldest programmer later integrated the interface with the run-time system of the LML compiler, making the interface much more efficient.
Approximately one year later, the two younger functional programmers felt they had a reasonably efficient system and a fairly nice abstraction. They wrote a paper about it and it was accepted at a functional programming conference [CH93b]. One of the younger functional programmers wrote some more about it and turned it into a licentiate thesis [CH93a].
The work continued. A number of improvements to make it easer to write programs were made, and the library was converted into Haskell. Improvements to the layout system allowed layout and plumbing to be specified separately. A lot of distracting extra function arguments could be removed after a parameter passing mechanism with default values was introduced. The resulting version of the Fudget library was presented at the Spring School on Advanced Functional Programming in Båstad in 1995 [HC95].
For programming by combination to be pervasive, it is important not only that we have access to a good library of subprograms, but the programming activity must also deal with forming new subprograms suitable for combination. Otherwise, the variety of programs we can write becomes limited because they get too complex. Therefore, programming by combination is also about forming new levels of subprograms.
One important aspect of programming is, of course, which programming language one uses. Different programming languages vary strongly in the support they give us when we want to program by combination. This is especially true when it comes to forming new subprograms. The authors have found that programming languages which are based on the declarative style are suitable in this respect. Declarative programming languages allow us to write programs in a mathematical style. For example, consider the expression
In a declarative programming language, we might identify a subprogram which we can namef((a + b) / 2,(a + b) / 2)
average.
It is important that the activity of forming subprograms should be as easy as possible for the programmer. If the programmer is required to write many more characters than are shown in the previous example, another programming method might become more attractive, namely programming by copy and paste. This will soon result in programs which are complex to understand and maintain, but unfortunately, it is a too widely practised method.let average = (a + b) / 2 in f(average,average)
The previous example did not actually introduce a subprogram. It could simply be seen as declaring a local variable. However, in declarative programming languages, we can use the same style when we want to form subprograms. The expression
uses a recurring calling pattern to the functionf(a,a+b) + f(a,a+c) + f(a,a+d)
f. This
pattern is easily captured by a subprogram that we can call
f2.
Forming a corresponding subprogram in the popular programming language C, for example, would be more involved. We would first need to declare a new top-level function, then make sure that its name did not collide with some other top-level function in the same source file, and finally, the function would need an extra parameter for the variablelet f2(x) = f(a,a+x) in f2(b) + f2(c) + f2(d)
a. All parameters would need
some type declaration.
As a more advanced example of programming by combination in declarative style, we might consider parsing combinators [Bur75][Wad85] (from now on, we will often talk about combinators when we mean subprograms which are designed for versatile combination). A large number of text parsers can be formed by four combinators:
token(c), which accepts the character c.p ||| q, which forms an alternative: it
either accepts whatever the parser p accepts, or it
accepts whatever the parser q accepts.p >>> q, which forms a sequence: it first
accepts whatever p accepts, and then accepts whatever
q accepts when given the rest of the text.epsilon, which parses the empty string.
withinParentheses(p) = token('(') >>> p >>> token(')')many(p), which
forms a parser which accepts whatever p accepts, zero or
more times in a sequence (this is often written p*):
Note that in most of these combinators, we have used the possibility to parameterise over subprograms, which is another important feature that declarative programming languages naturally support.many(p) = (p >>> many(p)) ||| epsilon
withinParentheses, for example. It is also hard or impossible to
share abstractions between the different tool languages and the
programmer's general programming language, something which adds to
the overall complexity of a software system.
To return to our example, parsing combinators allow us to smoothly integrate parsers in our software without any additional tools, languages or compilers. We only need a library for parsing combinators. More generally, combinator libraries can be seen as defining an embedded language inside our general programming language. This way, the number of concepts a programmer has to learn decreases drastically, since the general programming language's idioms apply directly.
However, it should be noted that combinator libraries often miss features that specialised tools have (like efficiency). It is a challenge for creators of combinator libraries to catch up with this.
There are two widely used styles for dealing with effects in declarative programming languages. We either allow all subprograms to directly have effects on the outer world, or we only allow subprograms to return values that represent effects.
Consider a subprogram in a programming language using direct effects. If the subprogram is a function that returns some value, it is often said that the function can have a side effect while computing its value. The order in which these side effects happen is made precise by defining a computation order for expressions. This is most easily done by saying that all arguments to subprograms should be computed left to right, and then the subprogram is called. Also, an expression which uses a local definition should compute the definition before the expression. Such programming languages are called strict.
Side effects can interact with the programmer's activity of forming new subprograms, or naming subexpressions. For example, it is no longer clear that we could write
instead oflet average = (a + b) / 2 in f(average,average)
because a potential side effect of the subprogram a would be carried out once in the first case, but twice in the second.f((a + b) / 2,(a + b) / 2)
Another problem with combinator programming in strict programming languages is that we must be much more careful when defining combinators in terms of themselves. If we use the definition
formany(p) = (p >>> many(p)) ||| epsilon
many, we end up in an infinite loop, if arguments
are computed strictly.
It is a very desirable feature of a programming language that
subprograms do not have side effects. This feature is used in the
non-strict, purely functional programming languages that we
will use in the rest of this thesis. The term ``purely
functional'' means that it is guaranteed that a function always
return the same value if its arguments have the same value, and
that it does not have any side effect. More generally, if the same
expression occurs in many places (as a above, for example),
it is guaranteed that all those occurrences compute to the same
value. It is only in a purely functional programming language that
we can introduce the variable average in the previous
example, regardless of what a and b are.
In purely functional languages, we use the second way of dealing with effects, where subprograms may return values that represent effects, instead of performing them directly. A representation of an effect can then be combined with other representations of effects, yielding a new representation of an effect. Finally, the effect that our whole program represents is carried out. This means that issues of effects and computations are separated. When defining and combining effects, we do not have to bother about which parts of our program should be computed, how many times they might be computed, and in which order.
Having combinators that return representations of effects opens up the possibility to manipulate these effects before they are carried out. This can be used to adapt the effects of existing combinators to new situations.
In what follows, we will often speak about combinators having various effects, or doing various kind of input/output. At times, it will be convenient to think that the combinators actually perform these effects directly, but it is important to remember that they only define a representation of an effect.
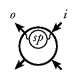
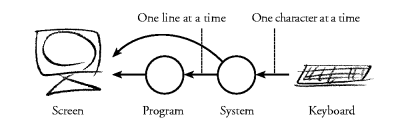
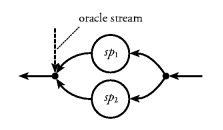
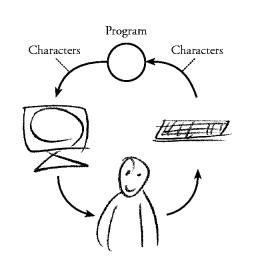
Suppose the outside world is a simple text terminal (see
Figure 1). Then, the interesting effects are: outputting
characters to the terminal screen, and inputting characters from
the terminal keyboard. The behaviour of a program could be
described by a sequence of the basic effects, so it is natural
to use sequential compositions of effects to build programs
with nontrivial behaviour. This is what is provided in the typical
imperative languages. Figure 1. A program and a user interacting via a text terminal.
As an example, consider a program that reads some numbers
separated by white space, and outputs the sum of the numbers.
In an imperative language, it would look something like this:
program = sumNumbers 0
sumNumbers acc =
if end_of_input
then putNumber acc
else do n <- getNumber
sumNumbers (acc+n)
getNumber = ...
putNumber = ...getNumber and
putNumber as reusable components. By taking a step back and
reflecting on what a program is, we can perhaps find ways of
composing programs other than the sequential composition of
effects. Having more versatile ways of composing programs is
likely to give us more opportunities to construct reusable
subprograms.
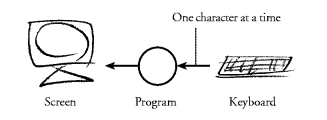
We choose to view programs as defining stream processors,
that is, a program describes some kind of process that consumes an
input stream and produces an output stream. This view goes back to
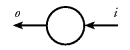
Landin [Lan65]. We use the symbol shown in
Figure 2 to denote a stream processor. Figure 2. A stream processor.![]()
A stream processor can be seen as a function on streams. A program that interacts with a text terminal could be seen as a function from a stream of characters to a stream of characters. When the program is run, the function is applied to the stream of characters received from the keyboard and the resulting stream of characters is output to the screen.
In a lazy functional language, streams can be represented as ordinary lists. A program that interacts with a text terminal can thus be built using ordinary list functions. The typical lazy functional solution to the number-summing problem looks something like this:
The input stream is chopped into words, the words are converted to numbers, the numbers are summed and converted back into characters that can be output to the screen.program = show . sum . map read . words
Let us compare this solution with the imperative one. In both
solutions, subprograms for parsing and printing numbers are reusable. In
the functional solution the number-summing function is reusable as
well. And although we have used a standard function to sum a list of
numbers, the above program can execute in constant space, since in a lazy
language, computations are performed on demand. Likewise, input
from the terminal is read on demand, allowing the computation
of the sum to be interleaved with the reading and parsing of
keyboard input. (If we tried to use the sum function in the
imperative solution, we would first have to read all the numbers
and store them in a list, and then call the sum
function. The program would thus not run in constant space.)
In the functional solution, the program is no longer expressed as a composition of basic effects. Instead, we have built the program from a number of stream processors in a pipe line.
We have now seen two ways of describing stream processors:
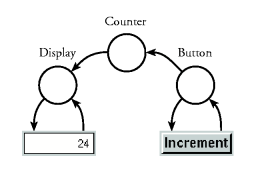
To illustrate what kind of program structure we are looking for,
take a look at the counter example (pun intended). The user
interface should contain two GUI elements: a button and a numeric
display. Each time the button is pressed, the number in the
display is incremented. We would like the program to contain one
stream processor per GUI element, taken from a library (often
called GUI toolkit or widget set), and an
application-specific stream processor that counts the button
presses and outputs numbers to the numeric display. The stream
processors should be connected as in Figure 3. Figure 3. The desired program structure of the counter
example.
The key idea is that stream processors from the library handle
the low-level details of the GUI elements, and the code that the
application programmer writes, communicates with the GUI elements
on a higher level of abstraction.
GUI elements can be seen as a particular kind of I/O device that a program can communicate with. The idea naturally extends to communication with other types of I/O devices, such as other computers on the Internet.
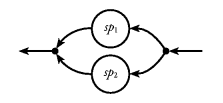
Our solution to building programs with this structure in a
purely functional language, is based on a special kind of stream
processor, the Fudget (see Figure 4. ``Fudget''
is an abbreviation of functional widget, where widget is
an abbreviation of window gadget). Figure 4. The Fudget.
A fudget has both low-level streams and high-level streams. The
low-level streams are always connected to the I/O system,
allowing the fudget to control a GUI element by receiving events
and sending commands to the window system. The high-level streams
can carry arbitrary (usually more abstract) values, and they
connect the fudgets that make up a program in an
application-specific way.
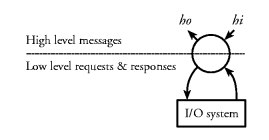
We will write the type of a fudget as
where hi and ho are the types of the messages in the high-level input and output streams, respectively.Fhi ho
The high-level streams between fudgets are connected by the
programmer using combinators. Three basic ways to combine fudgets
(and stream processors in general) are serial composition,
parallel composition and loops, see
Figure 5. Figure 5. Serial composition, parallel
composition, and loop.
The types of these combinators are: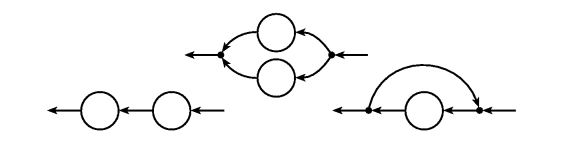
These simple ideas allow programs with graphical user interfaces to be built in a hierarchical way using a declarative style. For example, the counter example can be expressed as
>==< :: F a b -> F c a -> F c b-- serial composition>*< :: F a b -> F a b -> F a b-- parallel compositionloopF :: F a a -> F a a-- loop
that is, a serial composition of three fudgets, wheredisplayF >==< counterF >==< buttonF "Increment"
displayF and buttonF handle the widgets that the user
interacts with, and counterF just counts the button
presses.
Serial composition is closely related to ordinary function composition. With this in mind, one can see that the program has much the same structure as the Landin stream I/O number-summing example shown in Chapter 4. Examples like this one will be explained further in Chapter 9.
The main result of the work behind this thesis is the Fudget library, which is an implementation of the ideas outlined in the previous section. Among other things, it provides
We demonstrate the practical usefulness of the Fudget library by presenting a number of application programs, some of which are quite large. A number of programming styles and methods are presented which can be used when programming with Fudgets.
In the Fudget library, each GUI element is represented as a fudget. The library provides fudgets for many common basic building blocks, like buttons, pop-up menus, text boxes, etc. The library also provides combinators that allow building blocks to be combined into complete user interfaces.
This section introduces the Fudget library by presenting a number of GUI programming examples. They illustrate the basic principles of how to create complete programs from GUI elements and application-specific code. After the examples follows an overview of the library. We show
We believe that the program examples will be readable without detailed knowledge of Haskell--familiarity with some functional language is hopefully sufficient. However, some recurring patterns are perhaps worth explaining:
\ and ->: for
example, \ x -> x is the identity function.. is function composition.$ is just function application, that is
f $ x = f x. It is right
associative and has low precedence, so it can be used to avoid
nested parentheses. We often write expressions like
instead off $ g $ h $ \ x -> x + 1
f (g (h (\x -> x + 1)))
instead off x `ap` y
ap (f x) y
(*) is
equal to \x y -> x * y.
Operators can be partially applied using sections, again using
parentheses. For example, (2/) is the function \x ->
2 / x, and (/2) is the function \x -> x / 2.
(3,False,"fudget") is
(Int,Bool,String), the type of the list [1,2,3] is
[Int] and the type of the function \ x -> x is
a -> a.Either for
disjoint unions, defined as
and the typedata Either a b = Left a | Right b
Maybe for optional values, defined as
data Maybe a = Nothing | Just a
main. This value should be a representation of
the effect (as discussed in Chapter 3) the execution of the
program should have on the outside world. A program can be as
simple as
main = print "Hello, world!"
To allows boolean values to be tested for equality with theclass Eq a where (==) :: a -> a -> Bool
== operator, an instance declaration like the
following can be used:
For some standard type classes, instance declarations can be generated automatically by adding ainstance Eq Bool where True == True = True False == False = True _ == _ = False
deriving clause to the
type definition:
When an overloaded function is used in a new function definition, the overloading may be inherited by the new function. For example, consider the functiondata Bool = False | True deriving Eq
elem that checks if a value occurs
in a list, defined as
The type ofx `elem` [] = False x `elem` (y:ys) = x==y || x `elem` ys
elem is written
where the partelem :: Eq a => a -> [a] -> Bool
Eq a => is called a context. It means that
the type variable a is restricted to range over types that are
instance of the Eq class.
In Haskell 1.3, the class system was generalised to allow classes of
type constructors [Jon93] instead of just classes of base types. Type
variables were extended to range over type constructors. This means
a that type scheme like a Int is allowed. The type variable
a can be instantiated to, for example, Maybe and the
list type constructor, giving the types Maybe Int and
[Int], respectively.
The well known function map,
which is defined for lists in many functional languages, can now be generalised by introducing the classmap :: (a->b) -> [a] -> [b]
Functor,
Instances for the lists and theclass Functor f where map :: (a->b) -> f a -> f b
Maybe type can be defined as
However, the introduction of constructor classes was motivated by the change to monadic I/O (see Section 41.1.3) and a convenient syntax for monadic programming. The classinstance Functor [] where map f [] = [] map f (x:xs) = f x : map f xs instance Functor Maybe where map f Nothing = Nothing map f (Just x) = Just (f x)
Monad is defined as
and the specialclass Monad m where return :: a -> m a (>>=) :: m a -> (a -> m b) -> m b
do syntax for monadic expressions,is defined to mean the same asdo x1 <- m1 x2 <- m2 ... mn
m1 >>= (\ x1 -> m2 >>= (\ x2 -> ... mn))
http://www.cs.chalmers.se/~hallgren/Thesis/For practical details, such as where to get the Fudget library, which platforms are supported, and how to compile programs, see Appendix A.
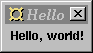 |
Here is the source code:
Note:import Fudgets main = fudlogue (shellF "Hello" (labelF "Hello, world!"))
Fudgets should be imported.fudlogue,
connects the main fudget to Haskell's I/O system, thus starting a dialogue between them. It sets up the communication with the window system, gathers commands sent from all fudgets in the program and sends them to the window system, and distributes events coming from the window system to the appropriate fudgets.fudlogue :: F a b -> IO ()
shellF,
which given a window title and a fudget, creates a shell window containing the graphical user interface defined by the argument fudget. The fudgets for GUI elements, likeshellF :: String -> F a b -> F a b
labelF, can not
be used directly on the top level in a program, but must appear
inside a shell window.labelF,
The argument is the label to be displayed. The label can be a value of any type that is an instance of thelabelF :: (Graphic a) => a -> F b c
Graphic
class. The Fudget library provides instances for many predefined
types, including strings. The Graphic class is discussed
in Section 27.1.
Both the input and output types of labelF are type
variables that do not occur anywhere else. This indicates that
none of the high-level streams are used by labelF.
labelF has only one parameter: the label to be
displayed. Most GUI fudgets come in two versions: a standard
version, like labelF, and a customisable version, for
example labelF', which allows you to change
parameters like fonts and colors, for which the standard version
provides default values. See Chapter 15 for more details.
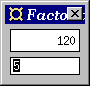 |
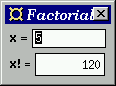
The program shows a numeric entry field at the bottom and a number
display at the top. Whenever the user enters a number in the
entry field and presses the Return key, the factorial of that number
is computed and displayed in the number display.
Here is the source code:
Note:import Fudgets main = fudlogue (shellF "Factorial" facF) facF = intDispF >==< mapF fac >==< intInputF fac 0 = 1 fac n = n * fac (n-1)
facF is structured as a serial composition of
three parts, using the operator >==<. Notice that, as
with ordinary function composition, data flows from right to
left. The parts are:fudlogue and shellF on
the top level as in the previous examples (Section 9.1).
Although this program does something useful (at least compared to the two previous examples), it could be made more user friendly, e.g., by adding some explanatory text to the user interface. The next example shows how to do this.>==< :: F a b -> F c a -> F c b intInputF :: F Int Int mapF :: (a -> b) -> F a b intDispF :: F Int a
 |
We have made the factorial function example from Section 9.2 more self documenting by adding labels to the entry field and the output display. We have also changed the order of the two parts: the entry field is now above the display.
Here is the source code:
import Fudgets
main = fudlogue (shellF "Factorial" facF)
facF = placerF (revP verticalP) (
("x! =" `labLeftOfF` intDispF) >==<
mapF fac >==<
("x =" `labLeftOfF` intInputF))
fac 0 = 1
fac n = n * fac (n-1)labLeftOfF
to put labels to the left of the entry field and the display.
(In Haskell, back quotes can be used to turn any function into an infix
operator, as we have done with labLeftOfF here).placerF can
be applied to a composition of fudgets to specify the relative
placement of the parts. (The layout system automatically picks
some placement if layout is left unspecified.)
The first argument to placerF is a placer, in our case
revP verticalP, where verticalP
causes the parts to be stacked vertically, with the leftmost fudget
in the composition at the top, and revP
reverses the order of the parts.
labLeftOfF :: (Graphic a) => a -> F b c -> F b c placerF :: Placer -> F a b -> F a b revP :: Placer -> Placer verticalP :: Placer
 |
This program has a button and a numeric display. Pressing the button increments the number in the display.
The application-specific code in this example sits between the button and the display. It maintains an internal counter which is incremented and output to the display whenever a click is received from the button.
Here is the source code:
Note:import Fudgets main = fudlogue (shellF "Up Counter" counterF) counterF = intDispF >==< mapstateF count 0 >==< buttonF "Up" count n Click = (n+1,[n+1])
counterF)
is a serial composition of three parts.
At the output end we see the familiar
intDispF.
At the input end of the pipe line is a button created with
buttonF.
It outputs a Click when pressed. The middle component
maintains an internal counter. The counter is incremented and
output to the display when a Click is received
from the button.mapstateF, like mapF, allows messages sent
between fudgets to be processed in an application-specific
way. With mapstateF, an arbitrary number of messages
can be output as response to an input message. In addition, the
output can depend not only on the current input, but also on an
internal state. mapstateF has two arguments: a
state transition function and an initial state. When applied to
the current state and an input message, the state transition
function should produce a new internal state and a list of output
messages.
The function count is the state transition function
in this program.
intDispF
automatically displays 0 when the program starts. The
initial value of the counter happens to be 0 as well. If
the 0 is changed in the definition of counterF,
the display will still show 0 when the program
starts. One way to fix this is to use the customisable version of
intDispF to specify the initial value to display.
This and the previous examples show how serial composition creates a communication channel from one fudget to another. But what if a fudget needs input from more than one source? The next example shows one possible solution.buttonF :: (Graphic a) => a -> F Click Click data Click = Click mapstateF :: (a -> b -> (a, [c])) -> a -> F b c
The two buttons affect the same counter.
Figure 6. The up/down counter.
Here is the source code:
import Fudgets
main = fudlogue (shellF "Up/Down Counter" counterF)
counterF = intDispF >==< mapstateF count 0 >==<
(buttonF filledTriangleUp >+<
buttonF filledTriangleDown)
count n (Left Click) = (n+1,[n+1])
count n (Right Click) = (n-1,[n-1])withbuttonF ...
using the operator(buttonF ... >+< buttonF ...)
>+< for parallel composition.Left and output from the right component is tagged
Right. The constructors Left and Right are
constructors in the datatype Either.count function will now receive Left Click or
Right Click, depending on which button was pressed. It has
been adjusted accordingly. (Note that Left Click and
Right Click have nothing to do with the left and right mouse
buttons!)
>+< :: F a b -> F c d -> F (Either a c) (Either b d) filledTriangleUp :: FlexibleDrawing filledTriangleDown :: FlexibleDrawing
 |
This program extends the counter example with yet another button. The counter can now be incremented, decremented and reset.
Here is the source code:
import Fudgets
main = fudlogue (shellF "Up/Down/Reset Counter" counterF)
counterF = intDispF >==< mapstateF count 0 >==< buttonsF
data Buttons = Up | Down | Reset deriving Eq
buttonsF = listF [(Up, buttonF "Up" ),
(Down, buttonF "Down" ),
(Reset, buttonF "Reset" )]
count n (Up, Click) = (n+1, [n+1])
count n (Down, Click) = (n-1, [n-1])
count n (Reset, Click) = (0, [0])listF than
>+<. The argument to listF is a list of
pairs of addresses and fudgets. The addresses are used when
messages are sent and received from the components in the
composition.Buttons, the elements of which are used as the addresses of
the buttons. The messages received by the count function
are pairs of Buttons values and Clicks.
listF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c)
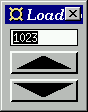
The program extends the up/down counter in Section 9.5 by allowing the user to set the counter to any value by entering it in the display field.
Figure 7. The loadable up/down counter.
Here is the source code:
import Fudgets
main = fudlogue (shellF "Loadable Up/Down Counter" counterF)
counterF = loopThroughRightF (mapstateF count 0) intInputF >==<
(buttonF filledTriangleUp >+< buttonF filledTriangleDown)
count n (Left n') = (n', [])
count n (Right (Left Click)) = (n+1, [Left (n+1)])
count n (Right (Right Click)) = (n-1, [Left (n-1)])
intDispF we have used intInputF,
which not only displays numbers, but also allows the user to enter
numbers.loopThroughRightF to allow
the count function to both receive input from and send
output to intDispF. In the composition
loopThroughRightF fud1 fud2, fud1 handles the communication
with the outside world (the buttons in this example), while fud2
can communicate only with fud1, and is in this sense
encapsulated by fud1. In fud1, messages to/from fud2 are
tagged Left and messages to/from the outside world are
tagged Right.
loopThroughRightF :: F (Either a b) (Either c d) -> F c a -> F b d
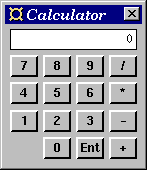
For simplicity, postfix notation is used, i.e., to compute 3+4 you enter
Figure 8. The calculator.
3 Ent 4 +. The source code can be found in Figure 9.
import Fudgets main = fudlogue (shellF "Calculator" calcF) calcF = intDispF >==< mapstateF calc [0] >==< buttonsF data Buttons = Plus | Minus | Times | Div | Enter | Digit Int deriving Eq buttonsF = placerF (matrixP 4) ( listF [d 7, d 8, d 9, op Div, d 4, d 5, d 6, op Times, d 1, d 2, d 3, op Minus, hole, d 0, ent, op Plus]) where d n = (Digit n,buttonF (show n)) ent = op Enter hole = (Enter,holeF) op o = (o,buttonF (opLabel o)) where opLabel Plus = "+" opLabel Minus = "-" opLabel Times = "*" opLabel Div = "/" opLabel Enter = "Ent" calc (n:s) (Digit d,_) = new (n*10+d) s calc s (Enter,_) = (0:s,[]) calc (y:x:s) (Plus,_) = new (x+y) s calc (y:x:s) (Minus,_) = new (x-y) s calc (y:x:s) (Times,_) = new (x*y) s calc (y:x:s) (Div,_) = new (x `div` y) s calc s _ = (s,[]) new n s = (n:s,[n])Figure 9. Source code for the calculator.
Note:
placerF
(as in Section 9.3)
and the placer matrixP
which has the number of columns as an argument.calc) is a stack (represented
as a list) of numbers. The function calc pushes
and pops numbers from the stacks as appropriate. The last
clause in the definition means that nothing happens if
there are too few values on the stack for an operation.buttonF allows you to
specify a keyboard shortcut for the button. It would thus be
relatively easy to make the calculator controllable from the keyboard.
matrixP :: Int -> Placer
Before we introduce the GUI elements, we discuss briefly how
fudget programs are formed using the function fudlogue.
F a b, for some types a and b. The main
program in Haskell should have type IO (), so we need a
glue function to be able to plug in the main fudget. The function
fudlogue is provided for this purpose:
Thefudlogue :: F a b -> IO ()
main program of a fudget program usually
consists just of a call to fudlogue with an argument fudget.
like
However, it is possible to combinemain :: IO () main = fudlogue the_main_fudget
fudlogue with other
monadic I/O operations. For example, to create a program that
starts by reading some configuration file, you could write
main = do config <- readFile config_filename
fudlogue (main_fudget config)shellF:
The typical GUI program has only one shell window, and the main program thus looks something likeshellF :: String -> F a b -> F a b
A program with more than one shell window could for example look something likemain = fudlogue (shellF window_title main_gui_fudget)
The fudgetmain = fudlogue (shellF title1 fud1 >==< shellF title2 fud2)
shellF is not restricted to the top level.
You could write the above example as
and achieve the same result.main = fudlogue (shellF title1 (fud1 >==< shellF title2 fud2))
labelF, which displays static
labels, and intDispF, which displays numbers that can
change dynamically. There
is also displayF,
a more general display for dynamically changing values. It can display values of any type in thedisplayF :: (Graphic a) => F a b
Graphic class. It
could in fact also display numbers, but intDispF has the
advantage that the numbers are displayed right adjusted.buttonF,
in the examples above. It provides command buttons, i.e., buttons trigger some action when pressed. The Fudget library also provides toggle buttons and radio groups (Figure 10). Pressing these buttons causes a change that has a lasting visual effect (and probably also some other lasting effect). A toggle button changes between two states (on and off) each time you press it. A radio group allows you to activate one of several mutually exclusive alternatives. The types of these fudgets arebuttonF :: (Graphic a) => a -> F Click Click
The input messages can be used to change the setting under program control.toggleButtonF :: (Graphic a) => a -> F Bool Bool radioGroupF :: (Graphic b, Eq a) => [(a, b)] -> a -> F a a
Figure 10. Toggle buttons and radio groups.
menuF name alts, whereprovides pull-down menus. name is the constantly visible name you press to activate the menu and alts is the list of menu alternatives.menuF :: (Graphic a, Graphic c) => a -> [(b, c)] -> F b b
The fudget
popupMenuF :: (Graphic b, Eq b) =>
[(a, b)] -> (F c d) -> F (Either [(a, b)] c) (Either a d)popupMenuF
initial_menu fud creates a fudget which behaves like
the fudget fud with the addition that the menu
initial_menu pops up when the user presses the third menu
button. You communicate with the fudget as with a tagged
parallel composition of the menu and the fudget
fud. Messages to/from the menu are tagged Left and
messages to/from fud are tagged Right. You can
replace the initial_menu by sending Left new_menu
to the fudget.
As an example, suppose we wanted a compact version of the
counter in Section 9.6. We could then replace the three
buttons with a pop-up menu attached to the display. The source
code for this and the resulting user interface is shown
Figure 11. We have used the combinator
Figure 11. A compact version of the up/down/reset
counter presented in Section 9.6. Figure 12. Figure 13. serCompLeftToRightF, which turns a parallel composition
into a serial composition (see Section 13.1). 
import Fudgets
main = fudlogue (shellF "Compact Up/Down/Reset Counter" counterF)
counterF =
serCompLeftToRightF
(popupMenuF menu (intDispF >==< mapstateF count 0))
data Buttons = Up | Down | Reset deriving Eq
menu = [(Up, "Up"), (Down, "Down"), (Reset, "Reset")]
count n Up = (n+1, [n+1])
count n Down = (n-1, [n-1])
count n Reset = (0, [0])
pickListF
When the number of alternatives is large, or when they change
dynamically, you can use a scrollable list instead of a
menu. The function
stringInputF
pickListF :: (a -> String) -> F (PickListRequest a)
(InputMsg (Int, a))pickListF is of type InputMsg, which is
explained in Section 10.5.1 below.
The values in the input stream are of type
PickListRequest to allow the list of alternatives to be
modified in various ways. To replace the entire list, you can
use
but there are other functions that let you insert new alternatives at some position in the list,replaceAll:: [a] -> PickListRequest a
or, more generally, replace part of the list with new alternatives,insertText:: Int -> [a] -> PickListRequest a
and so on. The screen will be updated in an efficient way when you do modifications of this kind.replaceText:: Int -> Int -> [a] -> PickListRequest a
for entering strings and integers (see Figure 13). For entering other types of values, you can usestringInputF :: F String String intInputF :: F Int Int
stringInputF and
attach the appropriate printer and parser functions.
stringInputF and intInputF do not
produce any output until the user presses the Enter (or
Return) key to indicate that the input is complete. This
is often a reasonable behaviour, but there are versions of
these fudgets that provide more detailed information:
These fudgets output messages of typestringF :: F String (InputMsg String) intF :: F Int (InputMsg Int)
InputMsg,
which contain the current contents of the entry field and an
indication of whether the value is intermediate or complete.
There are some stream processors that are useful when post processing messages from entry fields:
The first one passes through all messages, so that you will know about all changes to the contents of the entry field. The second one outputs a message when the user indicates that the input is complete and when the input focus leaves the entry field. The last one outputs a message only when the input is indicated as complete.stripInputSP :: SP (InputMsg a) a inputLeaveDoneSP :: SP (InputMsg a) a inputDoneSP :: SP (InputMsg a) a
The fudget stringInputF is defined as
As we saw above, the fudgetstringInputF = absF inputDoneSP >==< stringF
pickListF also produces
output of type InputMsg. In this case, input is considered
to be complete when the user double clicks on an
alternative. Hence you use stripInputSP if a single
click should be enough to make a choice, and inputDoneSP
if a double click should be required.which can display longer text.(Footnote: The names come from the fact that they serve the same purpose as the UNIX programmoreF :: F [String] (InputMsg (Int, String)) moreFileF :: F String (InputMsg (Int, String)) moreFileShellF :: F String (InputMsg (Int, String))
more.) The input to moreF is a list of lines of text to
be displayed. The other two fudgets display the contents of file
names received on the input. In addition, moreFileShellF
appears in its own shell window with a title reflecting the name
of the file being displayed.
There also is a text editor fudget (Figure 14), Figure 14. The text editor fudget
which supports cut/paste editing with the mouse, as well as a
small subset of the keystrokes used in GNU emacs. It also has an
undo/redo mechanism.
editorF.
pickListF, moreF and editorF, have scroll bars
attached by default. There are also combinators to explicitly
add scroll bars:ThescrollF, vScrollF, hScrollF :: F a b -> F a b
v and h versions give only vertical and
horizontal scroll bars, respectively. The argument fudget can be
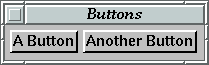
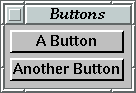
any combination of GUI elements.will get some default layout which might look like Figure 15.shellF "Buttons" (buttonF "A Button" >+< buttonF "Another Button")
But sooner or later, we will want to have control over the layout. The GUI library lets us do this two different ways:
Figure 15. When no layout is specified in the program, the automatic layout system chooses one.
placerF that has appeared in some of the
previous examples. It allows you to attach layout information to
an arbitrary fudget. Usually, you first combine some fudgets
using combinators like >+<, >==<, and listF,
and then apply placerF to the combination to specify a
layout. This is a fairly easy method for adding layout information to
a program. However, the layout possibilities are somewhat
limited by the structure of the program.
shellF.The parameter to
Figure 16. Different placers.
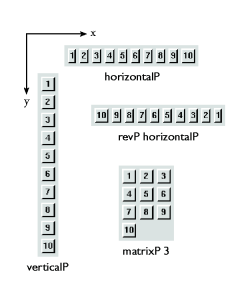
matrixP specifies the number of columns
the matrix should have. The types of the placers areThe placerhorizontalP :: Placer verticalP :: Placer matrixP :: Int -> Placer revP :: Placer -> Placer
revP reverses the list of boxes it is applied
to. Another higher order placer is flipP, which
transforms a placer into a mirror symmetric placer, with respect
to the line x = y (that is, it flips the x and y coordinates):Hence, we can defineflipP :: Placer -> Placer
verticalP asPlacers can be applied to fudgets by means ofverticalP = flipP horizontalP
placerF:It applies the placer to all boxes in the argument fudget. The order of the boxes is left to right, with respect to the combinatorsplacerF :: Placer -> F a b -> F a b
listF, >==< and >+<, etc.
As an example, suppose we want to specify that the two buttons in Figure 15 should have vertical layout. We could then write
shellF "Buttons" (placerF verticalP (buttonF "A Button" >+<
buttonF "Another Button"))
revP
verticalP, horizontalP or revP horizontalP,
respectively. Abstract fudgets do not have a corresponding box in the layout. This means that the presence of
Figure 17. The same GUI elements as in Figure 15, but the program explicitly specifies vertical layout.
mapstateF in the definition of counterF in
Figure 18,
does not leave a hole in the layout of
verticalCounterF. What if we want the display to appear between the two buttons? With the placers we have seen, the two buttons will appear together in the layout, since they appear together in the program structure. One solution is to use a placer operator that allows the order of the boxes to be permuted:
verticalCounterF = placerF verticalP counterF counterF = intDispF >==< mapstateF count 0 >==< (buttonF "Up" >+< buttonF "Down")Figure 18. An up/down counter with vertical layout. Abstract fudgets do not have a corresponding box in the layout.
We can then replacepermuteP :: [Int] -> Placer -> Placer
verticalP with
to get the display in the middle. This kind of solution works, but it will soon become quite complicated to write and understand. A more general solution is to use name layout (Section 11.2).permuteP [2,1,3] verticalP
Placers are used to specify the layout of a group of
boxes. In contrast, spacers are used to wrap a box around a single
box. Spacers can be used to determine how a box should be
aligned if it is given too much space, or to add extra space
around a box. Examples of spacers that deal with alignment can be
seen in Figure 19. Figure 19. Spacers for alignment.
The topmost box (placed with ![]()
horizontalP) must fill up
all the available space. The lower three boxes have been placed
inside a box which consumes the extra space. The spacers used
are derived from the spacer hAlignS, whose argument
states the ratio between the space to the left of the box and
the total available extra space:
There is a corresponding spacer tohAlignS :: Alignment -> Spacer leftS = hAlignS 0 hCenterS = hAlignS 0.5 rightS = hAlignS 1
flipP, namely
flipS. It too flips the x and y coordinates, and
lets us define some useful vertical spacers:WithflipS :: Spacer -> Spacer vAlignS a = flipS (hAlignS a) topS = flipS leftS vCenterS = flipS hCenterS bottomS = flipS rightS
compS, we can compose spacers, and define a spacer that
centers both horizontally and vertically:To add extra space to the left and right of a box, we usecompS :: Spacer -> Spacer -> Spacer centerS = vCenterS `compS` hCenterS
hMarginS left right, whereDistances are given in number of pixels.(Footnote: This is easy to implement, but makes programs somewhat device dependent.) FromhMarginS :: Distance -> Distance -> Spacer type Distance = Int
hMarginS, we can derive marginS, which adds
an equal amount of space on all sides of a box:Spacers can be applied to fudgets by means ofvMarginS above below = flipS (hMarginS above below) marginS s = vMarginS s s `compS` hMarginS s s
spacerF:The fudgetspacerF :: Spacer -> F a b -> F a b
spacerF s f will apply the
spacer s to all boxes in f which are not enclosed
in other boxes. We can also modify a placer by wrapping a spacer
around the box that the placer assembles:For example,spacerP :: Spacer -> Placer -> Placer
spacerP leftS horizontalP gives a horizontal
placer which will left adjust its boxes.nameF:The layout of the boxes that have been named in this way, is specified using the typetype LName = String nameF :: LName -> F a b -> F a b
NameLayout. Here are the basic
functions for constructing NameLayout values:To apply the layout to named boxes, we useleafNL :: LName -> NameLayout placeNL :: Placer -> [NameLayout] -> NameLayout spaceNL :: Spacer -> NameLayout -> NameLayout
nameLayoutF:As an application of name layout, we show how the vertical counter in Figure 18 can be changed, so that the display appears between the up and down buttons (Figure 20):nameLayoutF :: NameLayout -> F a b -> F a b
nlCounterF = nameLayoutF layout counterF
counterF = nameF dispN intDispF
>==< mapstateF count 0
>==< (nameF upN (buttonF filledTriangleUp) >+<
nameF downN (buttonF filledTriangleDown))
-- only layout below
layout = placeNL verticalP (map leafNL [upN, dispN, downN])
upN = "up"
downN = "down"
dispN = "disp"Now, we can control the layout of the two buttons and the display, without changing the rest of the program.
Figure 20. With name layout, the order of the GUI elements in the window does not have to correspond to their order in the program text.
The actual strings used for names are unimportant, as long as they are unique within the part of the fudget structure where they are in scope. So instead we can write
(upN:downN:dispN:_) = map show [1..]
placerF applied to some placer at some selected points in
the fudget hierarchy. This gives the programmer more control
over layout and is still perfectly safe, but there is a
coupling between how the fudgets have been composed and how
they appear on the screen. This is not necessarily bad, but
it limits the freedom in the choice of layout.nameF applied to a layout specification which,
by referring to the names, can achieve a layout of the GUI
elements completely unrelated to how they were composed.
In this solution it is possible to make mistakes, however. For the layout specification to work properly, the name of every named box should occur exactly once in the layout specification. If you forget to mention a box, or if you mention it twice, or if you name a box that does not exist, the layout will not work properly. These mistakes are not detected at compile time, but give rise run-time errors or a weird layout.
The problem with the name layout solution is that it requires a certain consistency between two different parts of the program. Maintaining this consistency during program development is of course an extra burden on the programmer.
Can a type system be used to make name layout safe? It would perhaps be possible to include layout information in some form in the types of GUI fudgets and catch some mistakes with the ordinary Haskell type system. However, the requirement that each name occurs exactly once in the layout specification suggests that you would need a type system with linear types [Hol88] to catch all mistakes.
mapF and mapstateF
for this:
facF = intDispF >==< mapF fac >==< intInputF
The functionscounterF = intDispF >==< mapstateF count 0 >==< buttonF "Up"
mapF and mapstateF create abstract
fudgets, that is, fudgets that do not perform any I/O. They
communicate only via their high-level streams.
A more general way to construct abstract fudgets is provided by
the function absF,
whereabsF :: SP a b -> F a b
SP is the type constructor for plain stream
processors. These have a single input stream and a single output
stream. The function absF creates a fudget by connecting
the streams of a stream processor to the high-level streams of the
fudgets, while leaving the low-level streams disconnected, as
shown in Figure 21.
Figure 21. Turning a stream processor into an abstract fudget.
The functions mapF and mapstateF are in fact
defined in terms of absF:
wheremapF = absF mapSP mapstateF = absF mapstateSP
mapSP and mapstateSP,
are discussed in Section 16.2 and Section 16.3, respectively.mapSP :: (a -> b) -> SP a b mapstateSP :: (a -> b -> (a, [c])) -> a -> SP b c
Although high-level combinators like mapF and
mapstateF are adequate for most fudget application programming,
some programmers may prefer the flexibility of the more basic ways
of creating stream processors. Two examples where abstract fudgets
are defined in terms of absF can be found in
Section 32.4. An extensive discussion of stream processors can
be found in Part III.
The different fudget combinators treat the high-level streams in different ways, while the low-level streams are treated in the same way in all combinators. Figure 22 illustrates serial and parallel composition of fudgets.-- Serial composition:>==<:: F b c -> F a b -> F a c -- Parallel composition:>+<:: F i1 o1 -> F i2 o2 -> F (Either i1 i2) (Either o1 o2)>*<:: F i o -> F i o -> F i olistF:: (Eq t) => [(t, F i o)] -> F (t, i) (t, o) -- Loops:loopF:: F a a -> F a aloopLeftF:: F (Either loop input) (Either loop output) -> F input outputloopThroughRightF:: F (Either oldo newi) (Either oldi newo) -> F oldi oldo -> F newi newo
Apart from the plumbing combinators listed above, the Fudget library contains further combinators that capture common patterns. Some of these combinators are described in the following sections.
Figure 22. Serial and parallel composition of fudgets.
The fudget combinators have corresponding combinators for plain
stream processors, which are discussed in more detail in
Chapter 17. Their names are obtained by replacing the
F suffix with an SP, or substituting -...-
for >...< in the operators.
fud2 >==<
fud1, the output of fud1 is connected to the input of fud2.
Many of the examples in Chapter 9 contain serial compositions of the form
The library provides the following combinators to capture these cases:mapF f >==< fud fud >==< mapF f
(The library versions of>=^< :: F a b -> (c -> a) -> F c b fud >=^< f = fud >==< mapF f >^=< :: (a -> b) -> F c a -> F c b f >^=< fud = mapF f >==< fud
>^=< and >=^< have
more involved definitions to be more efficient.)
Compositions of the form
are also common. The library provides two operators for these special cases:absF sp >==< fud fud >==< absF sp
Some combinators, like>^^=< :: SP b c -> F a b -> F a c sp >^^=< fud = absF sp >==< fud >=^^< :: F b c -> SP a b -> F a c fud >=^^< sp = fud >==< absF sp
popupMenuF (see Section 10.4),
create parallel compositions of fudgets, but sometimes a serial
composition is instead required. This could be accomplished by
using a loop and an abstract fudget to do the necessary routing,
but the library contains two combinators that do this:
The following equations hold:serCompLeftToRightF :: F (Either a b) (Either b c) -> F a c serCompRightToLeftF :: F (Either a b) (Either c a) -> F b c
serCompRightToLeftF (l >+< r)=l >==< r
serCompLeftToRightF (l >+< r)=r >==< l
>+< can become a bit clumsy. It may then be
more convenient to use listF,
which allows any type in thelistF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c)
Eq class to be used as
addresses of the fudgets to be combined. The restriction is that
the fudgets combined must have the same type. (See
Section 40.4 for a discussion of how a language with
dependent types could eliminate this kind of restriction.)
There is also a combinator for untagged parallel composition:
Input to an untagged parallel composition is sent to both argument fudgets.>*<:: F i o -> F i o -> F i o
There is a list version of untagged parallel composition as well,
which can easily be defined usinguntaggedListF :: [F a b] -> F a b
>*<:
whereuntaggedListF = foldr (>*<) nullF
nullF,
is the fudget that ignores all input and never produces any output.nullF :: F a b
The untagged parallel compositions are not as widely used as the tagged ones. The reason is probably that you usually do not want input to be broadcast to all fudgets in a composition.
There are some further combinators that tend to be useful every once in a while. These are various parallel compositions with the identity fudget:
idRightF :: F a b -> F (Either a c) (Either b c) idLeftF :: F a b -> F (Either c a) (Either c b) bypassF :: F a a -> F a a throughF :: F a b -> F a (Either b a) idRightF fud = fud >+< idF idLeftF fud = idF >+< fud bypassF fud = idF >*< fud throughF fud = idRightF fud >==< toBothF toBothF :: F a (Either a a) toBothF = concatMapF (\ x -> [Left x,Right x]) idF :: F a a idF = mapF id
loopF,
In the compositionloopF :: F a a -> F a a
loopF fud, the output from fud is not only
output from the composition, but also sent back to the input of fud.
The most useful loop combinator is probably
loopThroughRightF. An example use was shown in
Section 9.7 and it is discussed further in
Section 18.2.
Some loop combinators that have been useful are:
loopCompThroughRightF :: F (Either (Either a b) c)
(Either (Either c d) a) -> F b d
loopCompThroughLeftF :: F (Either a (Either b c))
(Either b (Either a d)) -> F c d
loopCompThroughRightF (l >+< r)=loopThroughRightF l r
loopCompThroughLeftF (l >+< r)=loopThroughRightF r l
To create dynamically changing parallel compositions of fudgets, the library provides
wheredynListF :: F (Int, DynFMsg a b) (Int, b)
Above we sawdata DynFMsg i o = DynCreate (F i o) | DynDestroy | DynMsg i
listF that creates tagged parallel
compositions that are static. The combinator dynListF can
be seen as a variant of listF with a more elaborate
input message type. When the program starts, dynListF is
an empty parallel composition. A new fudget fud with address
i can be added to the parallel composition by passing the
messageto(i,DynCreate fud)
dynListF. The fudget with address i can be
removed from the parallel composition by passing the messageFinally, one can send a message x to an existing fudget with address i by passing the message(i,DynDestroy)
to(i,DynMsg x)
dynListF.
(The addresses used by dynListF have been restricted to
the type Int for efficiency reasons, but in principle,
more general address types could be supported, as for
listF.)
A simpler combinator that allows fudgets to change dynamically
is dynF:
The fudgetdynF :: F a b -> F (Either (F a b) a) b
dynF fud starts out behaving like fud,
except that messages to fud should be tagged with
Right. The fudget fud can be replaced by another fudget fud'
by passing in the message Left fud'.
The output fromstdinF :: F a String stdoutF :: F String a stderrF :: F String a
stdinF is the characters received from the
program's standard input channel. For efficiency reasons,
you do not get one character at a time, but larger chunks of
characters. If you want the input as a stream of lines, you
can use
which puts together the chunks and splits them at the newlines.inputLinesSP :: SP String String
A simple example is a fudget that copies text from the keyboard to the screen with all letters converted to upper case:
It appliesstdoutF >==< (map toUpper >^=< stdinF)
toUpper to all characters in the strings
output by stdinF and then feeds the result to
stdoutF.
Here is a fudget that reverses lines:
The precedences and associativities of the combinators are such that these fudgets can be written as:(stdoutF>=^<((++"\n").reverse))>==<(inputLinesSP>^^=<stdinF)
stdoutF >==< map toUpper >^=< stdinF stdoutF >=^< (++"\n").reverse >==< inputLinesSP >^^=< stdinF
These can be seen as servers, with a one-to-one correspondence between requests and responses. For convenience, the responses are paired with the file path from the request. The responses contain either an error message or the result of the request. The result is the contents of a file (readFileF :: F FilePath (FilePath,Either IOError String) writeFileF :: F (FilePath,String) (FilePath,Either IOError ()) readDirF :: F FilePath (FilePath,Either IOError [FilePath])
readFile), a
directory listing (readDirF), or () (
writeFileF).
The timer is initially idle. When it receivesdata Tick = Tick timerF :: F (Maybe (Int, Int)) Tick
Just
(i,d) on its input, it begins ticking. The
first tick will be output after d milliseconds. Then,
ticks will appear regularly at i millisecond
intervals, unless i is 0, in which case only one tick
will be output. Sending Nothing to the timer resets it
to the idle state.
As a simple example, here is a fudget that outputs,once a second, the number of seconds that have elapsed since it was activated:
countSP >^^=< timerF >=^^< putSP (Just (1000,1000)) nullSP
where countSP = mapAccumlSP inc 0
inc n Tick = (n+1,n+1)buttonF, and a
customisable version, for example buttonF'. The name of
the customisable version is obtained by appending a ' to the
name of the standard version.
Customisable fudgets have a number of parameters that allow things like fonts, colors, border width, etc., to be specified. All these parameters have default values which are used in the standard version of the fudget.
Rather than having one extra argument for each such parameter, customisable versions of fudgets (or other functions) have one extra argument which is a customiser. The customiser is always the first argument. A customiser is a function that modifies a data structure containing the values of all parameters.
The type of the data structure is abstract. Its name is usually the name of the fudget, with the first letter change to upper case--for example,type Customiser a = a -> a
ButtonF in the case of buttonF'.
buttonF' :: (Graphic a) =>
(Customiser (ButtonF a)) -> a -> F Click Clickstandard,acts as the identity customiser and does not change any parameters. The standard versions of the fudgets are simply the customisable versions applied tostandard :: Customiser a
standard, for example:
buttonF = buttonF' standard
The customisers that are common to many fudgets are overloaded.
Some customiser classes are shown in
Figure 23. Figure 23. Some customiser classes. Figure 24. Some customiser instances.
The table in Figure 24 shows what customisers
are supported by the different customisable fudgets in the
current version of the Fudget library.
class HasBgColorSpec a where setBgColorSpec :: ColorSpec -> Customiser a
class HasFgColorSpec a where setFgColorSpec :: ColorSpec -> Customiser a
class HasFont a where setFont :: FontName -> Customiser a
class HasMargin a where setMargin :: Int -> Customiser a
class HasAlign a where setAlign :: Alignment -> Customiser a
class HasKeys a where setKeys :: [(ModState, KeySym)]
-> Customiser a
...
BgColorSpecFgColorSpecFontMarginAlignKeys
TextFy y y y y n
DisplayFy y y y y n
StringFy y y n n n
ButtonFy y y n n y
ToggleButtonFn n y n n y
RadioGroupFn n y n n n
ShellFn n n y n n
Some fudgets also have non-overloaded customisers, for example:
As an example of the use of customisation, Figure 25 shows a variation of the radio group shown in Figure 10.setInitDisp :: a -> Customiser (DisplayF a) -- changes what is displayed initially setAllowedChar :: (Char -> Bool) -> Customiser StringF -- changes what characters are allowed setPlacer :: Placer -> Customiser RadioGroupF -- changes the placements of the buttons
radioGroupF' (setFont "fixed" . setPlacer (matrixP 2)) [(1,"P1"),(2,"P2"),(3,"P3"),(0,"Off")] 0Figure 25. Custom version of the radio group in Figure 10.
So, we started out thinking of fudgets as the primitive concept, but soon saw them as being derived from a simpler concept, the stream processor, which is a process that communicates with its surroundings through a single input stream and a single output stream.
This part of the thesis is devoted to stream processors.
We have not used stream processors extensively in the examples presented so far, but plain stream processors are interesting for at least these reasons:
We use the following informal definitions:
The restriction may seem severe, but the chosen set of combinators allows streams to be merged and split, so a stream processor with many input/output streams can be represented as one with a single input stream and a single output stream. The advantage is that we can take a combinator-based approach to building networks of communicating stream processors. The combinators are discussed further in Chapter 17. Below we discuss how to write atomic stream processors, that is, stream processors that do not consist of several concurrently running stream processors. Their behaviour is defined by a linear sequence of I/O actions.
Figure 26. A general stream processor and a stream processor with a single input stream and a single output stream.
wheredata SP input output
input and output are the types of the
elements in the input and output streams, respectively
(Figure 27). (The implementation of stream processors in a
lazy functional language are discussed in
Chapter 20.) The library also provides the function
Figure 27. A stream processor of type
SPi o.
which can be used on the top level of a program built with stream processors (see Chapter 19). The functionrunSP :: SP i o -> [i] -> [o]
absF discussed in Chapter 12 can be
used to combine stream processors with fudgets.
As an example of how to use these in recursive definitions of stream processors, consider the identity stream processorputSP :: output -> SP input output -> SP input output getSP :: (input -> SP input output) -> SP input output nullSP :: SP input output
the busy stream processor-- The identity stream processor idSP :: SP a a idSP = getSP $ \ x -> putSP x idSP
and the following stream-processor equivalents of the well known list functions:-- A stream processor that is forever busy computing. busySP :: SP a b busySP = busySP
mapSP :: (a -> b) -> SP a b
mapSP f = getSP $ \ x -> putSP (f x) $ mapSP f
filterSP :: (a -> Bool) -> SP a a
filterSP p = getSP $ \ x -> if p x
then putSP x $ filterSP p
else filterSP pnullSP need actually not be
considered as a primitive. It can be defined as
i.e., it is a stream processor that ignores all input and never produces any output. A practical advantage with an explicitly representednullSP = getSP $ \ x -> nullSP
nullSP is that it allows stream processors
that terminate to be ``garbage collected''.concatMapSP :: (i->[o]) -> SP i o.putListSP that outputs the elements
of a list, one at a time:
AndputListSP :: [o] -> SP i o -> SP i o putListSP [] = id putListSP (x:xs) = putSP x . putListSP xs
concatMapSP itself:
concatMapSP f =
getSP $ \ x ->
putListSP (f x) $
concatMapSP f
mapFilterSP :: (i->Maybe o) -> SP i o.
mapFilterSP f =
getSP $ \ x ->
case f x of
Nothing -> mapFilterSP f
Just y -> putSP y $
mapFilterSP f
sumSP, a stream processor that computes the accumulated
sum of its input stream:
In this case, the internal state is a value of the typesumSP :: Int -> SP Int Int sumSP acc = getSP $ \ n -> putSP (acc+n) $ sumSP (acc+n)
Int, which also happens to be the type of the input
and output streams. In general, the type of the input and output
streams can be different from the type of the internal state,
which can then be completely hidden.
The Fudget library provides two general functions for construction of stream processors with internal state:
(mapAccumlSP :: (s -> i -> (s, o)) -> s -> SP i o concatMapAccumlSP :: (s -> i -> (s, [o])) -> s -> SP i o
concatMapAccumlSP is also known as mapstateSP.)
The first argument to these functions is a state transition
function which given the current state and an input message
should produce a new state and an output message (zero or more
outputs in the case of concatMapAccumlSP). Using mapAccumlSP we
can define sumSP without using explicit recursion:
Representing state information as one or more accumulating arguments is useful when the behaviour of the stream processor is uniform with respect to the state. If a stream processor reacts differently to input depending on its current state, it can be more convenient to use a set of mutually recursive stream processors where each stream processor corresponds to a state in a finite state automaton. As a simple example, consider a stream processor that outputs every other element in its input stream:sumSP :: Int -> SP Int Int sumSP = mapAccumlSP (\ acc n -> (acc+n,acc+n))
It has two states: the ``pass on'' state, where the next input is passed on to the output; and the ``skip'' state, where the next input is skipped.passOnSP = getSP $ \ x -> putSP x $ skipSP skipSP = getSP $ \ x -> passOnSP
The two ways of representing state illustrated above, can of course be combined.
mapAccumlSP and concatMapAccumlSP
using putSP and getSP.
concatMapAccumlSP :: (s -> i -> (s, [o])) -> s -> SP i o
concatMapAccumlSP f s0 =
getSP $ \x ->
let (s, ys) = f s0 x
in putListSP ys $
concatMapAccumlSP f s
mapAccumlSP :: (s -> i -> (s, o)) -> s -> SP i o
mapAccumlSP f s0 =
getSP $ \x ->
let (s, y) = f s0 x
in putSP y $
mapAccumlSP f s
The stream processorseqSP :: SP a b -> SP a b -> SP a b
sp1 `seqSP` sp2 behaves like
sp1 until sp1 becomes nullSP, and then behaves like
sp2. However, the same can also be achieved by making all
procedures end with a call to a continuation stream processor
instead of nullSP; so seqSP does not add any new
power.
We should also note that if this is to work properly, the
operation nullSP must be explicitly represented, and not
just defined as a stream processor that ignores all input and
never produces any output; contrary to what was suggested in
Section 16.2.
Thanks to
Figure 28. The stream-processor monad.
runSPm you can use the combinators for
``plain'' stream processors to construct networks of
stream-processor monads.
For writing complex stream processors, it is of course possible
to combine the stream-processor monad with other monads, e.g., a
state monad. The Fudget library defines the type SPms
for stream processor-monads with state. A closer presentation
and an example of its use can be found as part of
Chapter 31.
It connects the output stream of one stream processor to the input stream of another, as illustrated in Figure 29. Streams flow from right to left, just like values in function compositions,(-==-) :: SP b c -> SP a b -> SP a c
f . g. Serial composition of stream processors is very close to function composition. For example, it obeys the following law:
Figure 29. Serial composition of stream processors.
mapSP f -==- mapSP g=mapSP (f . g)
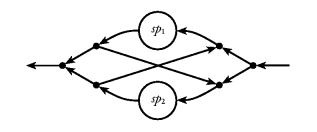
There is however, more than one possible definition of parallel composition. How should values in the input stream be distributed to the two stream processors? How should the output streams be merged? We define two versions:
Figure 30. Parallel composition of stream processors.
sp1 -*- sp2 denote parallel composition where input
values are propagated to both sp1 and sp2, and output is
merged in chronological order. We will call this version
untagged, or broadcasting parallel composition.sp1 -+- sp2 denote parallel composition where the
values of the input and output streams are elements of a
disjoint union. Values in the input stream tagged Left or
Right are untagged and sent to either sp1 or sp2,
respectively. Likewise, the tag of a value in the output
stream indicates which component it came from. We will call
this version tagged parallel composition.
Note that only one of these needs to be considered as primitive. The other can be defined in terms of the primitive one, with the help of serial composition and some simple stream processors like(-*-) :: SP i o -> SP i o -> SP i o (-+-) :: SP i1 o1 -> SP i2 o2 -> SP (Either i1 i2) (Either o1 o2)
mapSP and filterSP.-*- in terms of -+-, and vice
versa.
(-*-) :: SP i o -> SP i o -> SP i o
sp1 -*- sp2 =
mapSP stripEither -==-
(sp1 -+- sp2) -==-
toBothSP
stripEither :: Either a a -> a
stripEither (Left a) = a
stripEither (Right a) = a
toBothSP :: SP a (Either a a)
toBothSP = concatMapSP (\x -> [Left x, Right x])
(-+-) :: SP i1 o1 -> SP i2 o2 -> SP (Either i1 i2) (Either o1 o2)
sp1 -+- sp2 = sp1' -*- sp2'
where
sp1' = mapSP Left -==- sp1 -==- filterLeftSP
sp2' = mapSP Right -==- sp2 -==- filterRightSP
filterLeftSP = mapFilterSP stripLeft
filterRightSP = mapFilterSP stripRight
stripLeft :: Either a b -> Maybe a
stripLeft (Left x) = Just x
stripLeft (Right _) = Nothing
stripRight :: Either a b -> Maybe b
stripRight (Left _) = Nothing
stripRight (Right y) = Just y The simplest possible loop combinator connects the
output of a stream processor to its input, as illustrated in
Figure 31. As with parallel composition, we define two
versions of the loop combinator: Figure 31. A simple loop constructor.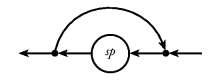
loopSP sp, loopLeftSP sp, Left are looped and values
tagged Right are output. At the input, values from the
loop are tagged Left and values from the outside are
tagged Right.
Each of the two loop combinators can be defined in terms of the other, so only one of them needs to be considered primitive.loopSP:: SP a a -> SP a aloopLeftSP:: SP (Either l i) (Either l o) -> SP i o
Using one of the loop combinators, one can now obtain
bidirectional communication between two stream processors as
shown in Figure 32. Figure 32. Using a loop to obtain bidirectional communication.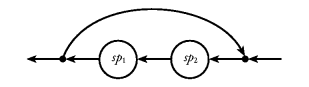
Another example shows that we can use loops and parallel composition to create fully connected networks of stream processors. With an expression like
we get a broadcasting network. By replacingloopSP (sp1 -*- sp2 -*- ... -*- spn)
-*- with
-+- and some tagging/untagging, we get a network with
point-to-point communication.loopSP in terms of loopLeftSP and vice versa.loopSP in terms of loopLeftSP is
relatively easy:
loopSP :: SP a a -> SP a a
loopSP sp =
loopLeftSP
(toBothSP -==- sp -==- mapSP stripEither)
loopLeftSP :: SP (Either l i) (Either l o) -> SP i o
loopLeftSP sp =
mapFilterSP post -==-
loopSP sp' -==-
mapSP Right
where
post (Left (Right x)) = Just x
post _ = Nothing
sp' = mapSP Left -==- sp -==- mapFilterSP pre
where
pre (Right x) = Just (Right x)
pre (Left (Left x)) = Just (Left x)
pre _ = Nothing
Fudgets are composed in the same way as plain stream processors. Therefore, the description of the stream-processor combinators also holds true for the corresponding fudget combinators. The fudget combinators are presented by name, together with some further combinators, in Chapter 13.
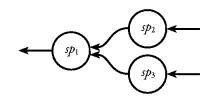
allows sp1 to receive input from both sp2 and sp3. For most practical purposes, sp1 can be regarded as having two input streams, as illustrated in Figure 33. When you usesp1 -==- (sp2 -+- sp3)
getSP in sp1 to read
from the input streams, messages from sp2 and
sp3 will appear tagged with Left and Right,
respectively. You can not directly read selectively from one
of the two input streams, but the Fudget library provides
the combinator
Figure 33. Handling multiple input streams.
which you can use to wait for a selected input. Other input is queued and can be consumed after the selected input has been received. UsingwaitForSP :: (i -> Maybe i') -> (i' -> SP i o) -> SP i o
waitForSP you can define combinators to
read from one of two input streams:
getLeftSP :: (i1 -> SP (Either i1 i2) o) -> SP (Either i1 i2) o getLeftSP = waitForSP stripLeft getRightSP :: (i2 -> SP (Either i1 i2) o) -> SP (Either i1 i2) o getRightSP = waitForSP stripRight
startupSP :: [i] -> SP i o -> SP i o
that prepends some elements to the input stream of a stream
processor.Note: this implementation leaves a serial composition withstartupSP xs sp = sp -==- putListSP xs idSP
idSP behind after the messages xs have been
fed to sp. An efficient implementation that does
not leave any overhead behind can be obtained by making
use of the actual representation of stream processors.waitForSP described above.
waitForSP :: (i -> Maybe i') -> (i' -> SP i o) -> SP i o
waitForSP expected isp =
let contSP pending =
getSP $ \ msg ->
case expected msg of
Just answer -> startupSP (reverse pending) (isp answer)
Nothing -> contSP (msg : pending)
in contSP []
A variation of the loop combinators that has turned out to
be very useful when reusing stream processors is Figure 34. Encapsulation.
loopThroughRightSP, illustrated in Figure 34. The key
difference from loopSP and loopLeftSP is that
the loop does not go directly back from the output to the
input of a single stream processor. Instead it goes through
another stream processor.
A typical situation where 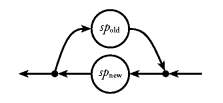
loopThroughRightSP is useful
is when you have a stream processor, spold, that does
almost what you want it to do, but you need it to handle some
new kind of messages. A new stream processor, spnew, can
then be defined. This new stream processor can pass on old
messages directly to spold and handle the new messages in
the appropriate way; on its own, or by translating them to
messages that spold understands. (See also Section 3.1.1 in
[NR94].)
In the composition loopThroughRightSP spnew spold, all
communication with the outside world is handled by
spnew. spold is connected only to spnew, and is in this sense
encapsulated inside spnew.
The type of loopThroughRightSP is:
loopThroughRightSP :: SP (Either oldo newi) (Either oldi newo) ->
SP oldi oldo ->
SP newi newoloopThroughRightSP corresponds to
inheritance in object-oriented programming. The encapsulated
stream processor corresponds to the inherited class.
Overridden methods correspond to message constructors that the
encapsulating stream processor handles itself.loopThroughRightSP using
loopLeftSP together with parallel and serial compositions
as appropriate.
loopThroughRightSP ::
SP (Either oldo i) (Either oldi o) -> SP oldi oldo ->SP i o
loopThroughRightSP spnew spold =
loopLeftSP
(mapSP post -==- (spold -+- spnew)
-==- mapSP pre)
where
pre (Right input) = Right (Right input)
pre (Left (Left newToOld)) = Left newToOld
pre (Left (Right oldToNew)) = Right (Left oldToNew)
post (Right (Right output)) = Right output
post (Right (Left newToOld)) = Left (Left newToOld)
post (Left oldToNew) = Left (Right oldToNew)
(-==-) :: SP b c -> SP a b -> SP a c
sp1 -==- sp2 =
loopThroughRightSP (mapSP route) (sp1 -+- sp2)
where
route (Right a) = Left (Right a)
route (Left (Left c)) = Right c
route (Left (Right b)) = Left (Left b)
loopThroughBothSP,
loopThroughBothSP :: SP (Either l12 i1) (Either l21 o1)
-> SP (Either l21 i2) (Either l12 o2)
-> SP (Either i1 i2) (Either o1 o2)
loopThroughRightSP.
A composition loopThroughBothSP sp1 sp2
allows both sp1 and sp2 to communicate with the outside
world and with each other (see Figure 35).
Figure 35. Circuit diagram for
loopThroughBothSP.
An interesting property of loopThroughBothSP is
that the circuit diagrams of the more basic combinators,
-==-, -+- and loopSP, can be
obtained from the circuit diagram of loopThroughBothSP
by just removing wires. Other combinators are thus easy to
define in terms of loopThroughBothSP.
nullSP, putSP and getSP) and the operators
that are used to build static networks of stream processors
(-==-, -*-, loopSP, etc.). But
there is in fact no reason why networks must be static. By
using combinators like -==- and -*- in a
dynamic way, the number of stream processors can be made to
increase dynamically. The number of stream processors can
also decrease, for example if a component of a parallel
composition dies (since nullSP -*- sp is equivalent to
sp).
A practical application of these ideas is discussed in Section 35.4.
that computes the accumulating sum of a stream of integers. Let us write a complete Haskell program that usessumSP :: Int -> SP Int Int
sumSP to implement a simple adding machine.
Haskell provides the function interact, which allows
functions of type [Char] -> [Char] to be used as programs (as in
Landin's stream I/O model outlined in
Chapter 4). By combining this with the function
runSP,
(from Section 16.1) we can run stream processors of typerunSP :: SP i o -> [i] -> [o]
SP
Char Char:
To be able to usemain = interact (runSP mainSP) mainSP :: SP Char Char mainSP = ...
sumSP we need only add some glue
functions that convert the input stream of characters to a
stream of numbers and conversely for the output stream. This
is done in two stages. First, the stream-processor
equivalents of the standard list functions lines and
unlines are used to process input and output line by line,
instead of character by character:
Now the standard functionsmainSP = unlinesSP -==- adderSP -==- linesSP adderSP :: SP String String adderSP = ...
show and read are
used to convert between strings and numbers,
and the program is complete.adderSP = mapSP show -==- sumSP 0 -==- mapSP read
unlinesSP :: SP String Char.unlinesSP = concatMapSP (\s -> s++"\n")
linesSP :: SP Char String
linesSP = lnSP []
where
lnSP acc =
getSP $ \msg ->
case msg of
'\n' -> putSP (reverse acc) (lnSP [])
c -> lnSP (c : acc)
Assuming a simpler system, where keyboard input is fed directly to the program, and the only characters shown on the screen are those output by the program (raw terminal mode in Unix) (Figure 37), the stream-processor combinator
Figure 36. Line buffered input.
lineBufferSP is now defined to do the job:
Figure 37. Unbuffered input.
It takes a stream processor that expects the input to be line buffered, and returns a stream processor that does the necessary processing of the input: buffering, echoing, etc., so that it can work in an unbuffered environment.lineBufferSP :: SP String Char -> SP Char Char
We implement lineBufferSP using
loopThroughRightSP:
lineBufferSP progsp = loopThroughRightSP bufSP progsp
where
bufSP :: SP (Either Char Char) (Either String Char)
bufSP = ...bufSP
will receive program output and keyboard input on its input
stream and should produce input lines and screen output on its
output stream. The implementation of
Figure 38. Circuit diagram for
lineBufferSP.
bufSP is shown in Figure 39.
bufSP = inputSP "" inputSP line = getSP $ either fromProgsp fromKeyboard where fromProgsp c = putSP (toScreen c) (inputSP line) fromKeyboard c = case c of -- TheEnterkey: '\n' -> putSP (toScreen '\n') $ putSP (toProgsp (reverse line)) $ bufSP -- Thebackspacekey: '\b' -> if null line then inputSP line else putsSP (map toScreen "\b \b") $ inputSP (tail line) -- Printable characters: _ -> putSP (toScreen c) $ inputSP (c:line) toScreen = Right toProgsp = LeftFigure 39.
bufSP- the core oflineBufferSP.
Using lineBufferSP, the adding machine in the previous
section can be adapted to run in raw terminal mode by change
mainSP to:
mainSP = lineBufferSP (unlinesSP -==- adderSP)
A simple implementation ofsplitViewSP :: SP Char Char -> SP Char Char -> SP Char Char
splitViewSP can be structured as
follows:
splitViewSP sp1 sp2 =
mergeSP -==- (sp1 -+- sp2) -==- distrSP
where
distrSP :: SP Char (Either Char Char)
distrSP = ...
mergeSP :: SP (Either Char Char) Char
mergeSP = ...distrSP takes the keyboard input and sends it to one of
the two windows. The user can switch windows by pressing a
designated key.
mergeSP takes the two output streams from the windows
and produces a merged stream, which contains the appropriate
cursor control
sequences to make the text appear in the right places on the
screen. This can be done in different ways depending on the
terminal characteristics. A simple solution, if scrolling is
not required, is to split the processing into two steps: the first
being to interpret the output streams from the two windows
individually to keep track of the current cursor position
using a stream processor like
It takes a character stream containing a mixture of printable characters and cursor control characters, and produces a stream with pairs of cursor positions and printable characters. The next step is to merge the two streams and feed them into a stream processor that generates the appropriate cursor motion commands for the terminal:trackCursorSP :: SP Char ((Int,Int),Char)
Thus we haveencodeCursorMotionSP :: SP ((Int,Int),Char) Char
mergeSP =
encodeCursorMotionSP -==-
mapSP stripEither -==-
(trackCursorSP -+- trackCursorSP)mergeSP, we
get the circuit diagram shown in Figure 40 for
splitViewSP sp1 sp2:
Figure 40. Circuit diagram for
splitViewSP sp1 sp2.
Filling in some details we ignored in the above description,
we get the implementation shown in Figure 41. Figure 41. An implementation of
splitViewSP :: (Int,Int) -> SP Char Char -> SP Char Char -> SP Char Char
splitViewSP (w,h) sp1 sp2 =
mergeSP -==- (sp1 -+- sp2) -==- distrSP Left Right
where
mergeSP = encodeCursorMotionSP -==-
mapSP stripEither -==-
(trackCursorSP (w,h1) -+-
(mapSP movey -==- trackCursorSP (w,h2)))
h1 = (h-1) `div` 2
h2 = h-1-h1
movey ((x,y),c) = ((x,y+h1+1),c)
distrSP dst1 dst2 =
getSP $ \ c ->
case c of
'\t' -> distrSP dst2 dst1
_ -> putSP (dst1 c) $ distrSP dst1 dst2
trackCursorSP :: (Int,Int) -> SP Char ((Int,Int),Char)
trackCursorSP size = mapstateSP winpos (0,0)
where winpos p c = (nextpos p c,[(p,c)])
encodeCursorMotionSP :: SP ((Int,Int),Char) Char
encodeCursorMotionSP = mapstateSP term (-1,-1)
where
term cur@(curx,cury) (p@(x,y),c) =
(nextpos p c,move++[c])
where
move = if p==cur
then ""
else moveTo p
nextpos :: (Int,Int) -> Char -> (Int,Int)
nextpos p c = ... -- cursor position after c has been printed
moveTo :: (Int,Int) -> String
moveTo (x,y) = ... -- generate the appropriate cursor control sequence
splitViewSP.
The automatic layout system in Chapter 23 can be seen as a sub-library of combinators, which is used not only for placing the GUI fudgets, but also to compose graphics.
Two examples of filter fudgets (combinators that modify the effect of fudgets) are presented in Chapter 24. The cache filter makes fudget programs run faster using less memory, and the focus filter modifies the input model of GUI fudgets that use the keyboard.
A distinguishing feature of stream processors and fudgets is that they can be detached from their original position in the program, passed as messages, and attached at another position. Chapter 25 describes how this can be used to program drag-and-drop applications, where GUI fudgets actually move inside the program when dragged.
Chapter 26 shows how the fudget concept can be used for programming client/server applications. Server programs do usually not have any graphical interface, but it is can be advantageous to program servers in a concurrent style so that they can serve many clients simultaneously.
The library contains a class of types that has a graphical
appearance, which can be manipulated by the
user. Chapter 27 presents the Graphic class and
its implementation.
So a stream with elements of type a can be represented as a list with elements of type a. A stream processor can be represented as function from the input stream to the output stream:
We call this the list-based representation. An obvious advantage with this approach is that the list type is a standard type and all operations provided for lists can be reused when defining stream processors.type Stream a = [a] type SP i o = Stream i -> Stream o
Another advantage with this representation is that it clearly shows the close relationship between functions and stream processors. For example, serial composition is simply function composition:
The basic stream processor actions also have very simple definitions:(-==-) :: SP m o -> SP i m -> SP i o sp1 -==- sp2 = sp1 . sp2
nullSP = \ xs -> []
x `putSP` sp = \ xs -> x : sp xs
getSP isp = \ xs -> case xs of
[] -> []
x:xs' -> isp x xs'
sp1 -*- sp2 = \ xs -> merge (sp1 xs) (sp2 xs)
where merge ys zs = ???
that is, sp1 needs some input before it can produce some output, but sp2 can outputsp1 _|_ = _|_ sp2 _|_ = 1:_|_
1 immediately.
Then, the composition should immediately output 1,
But(sp1 -*- sp2) _|_ = 1:_|_
(sp2 -*- sp1) _|_ should also be 1:_|_,
so ??? must be an expression that chooses the one of
ys and zs which happens to be non-bottom. This can
clearly not be done in an ordinary purely functional language.
As a more concrete example, consider what should happen if we apply the stream processor
to [1, 2, 3, 4, ...]. If the input elements appear at a slower rate than they can be processed by eithermap (*100) -*- filter even
map or filter, the
desired output stream would be something like [100, 200, 2, 300,
4, 400, ...], i.e., in this particular case there should be two
elements from the left stream processor for every element from
the right stream processor.
The elements in the two output streams should be merged in the order they become computable as more elements of the input stream become available. However, there is no way of telling in a sequential language which of the two stream processors will be the first one to be able to produce an output. Is seems that the two streams need to be evaluated in parallel, and then elements must be chosen in the order they become available.
The most natural and general solution to this problem is to use parallel evaluation, and we will take a look at this next. But by changing the representation of stream processors it is possible to obtain solutions that work in an ordinary sequential language. We will look at these solutions in Section 20.4.
The operator suggested above is a variant of amb,
McCarthy's ambivalent operator [McC63]. But a
programming language with such an operator is not purely
functional, and thus makes ordinary equational reasoning
unsound. Although such a language may still be useful
[Mor94], there are solutions that allow you to make
indeterministic choices in a purely functional way.
In the following section, we will introduce a variant of
amb which is purely functional.
We call our operator for indeterministic choice choose:
Operationally, the expressionchoose :: Oracle -> a -> b -> Bool
choose o a
b is evaluated by starting the evaluation of a
and b in parallel and then returning True if
a reaches head normal form first, and False if
b does. Denotationally, choose o a
b returns True or False depending only
on the value of the oracle o (which magically happen to
have the ``right'' value). An oracle should only be used once,
since it must always give the same answer. We therefore
distribute an infinite tree of oracles to all stream
processors, as an additional argument:
Using the oracle tree, we can now easily implement parallel composition of stream processors (see also Figure 42):data OracleTree = OracleNode OracleTree Oracle OracleTree type SP i o = OracleTree -> Stream i -> Stream o
sp1 -*- sp2 =
\(OracleNode (OracleNode ot _ ot1) _ ot2) xs ->
merge ot (sp1 ot1 xs) (sp2 ot2 xs)
where merge (OracleNode ot o _) ys zs =
if choose o ys zs
then merge' ot ys zs
else merge' ot zs ys
merge' ot (y:ys) zs = y:merge ot ys zs
merge' ot [] zs = zsmerge, together with the output
streams from the composed stream processors. The function
merge extracts fresh oracles from the tree and uses
choose to see which stream is first to reach head
normal form, It then calls merge', with the second
argument being the stream which has been evaluated.
Figure 42. Parallel composition of stream processors using oracles.
If we impose the restriction that sp1 and sp2 must produce
output at the same rate, then sp1 -*- sp2 can
be defined as:
However, it is awkward to impose such a constraint between the output streams of two different stream processors. Also, this solution does not work well for tagged parallel composition. A more useful constraint relates the input and output stream of a single stream processor.(sp1 -*- sp2) xs = merge (sp1 xs) (sp2 xs) where merge (y:ys) (z:zs) = y:z:merge ys zs
map is an example that satisfies this
constraint, whereas filter is a function that does not.
With this restriction, tagged parallel composition can easily be implemented: the next element in the output stream should be taken from the stream processor that last received an element from the input stream. The following implementation of tagged parallel composition uses this fact by merging the output streams using a stream of synthetic oracles computed from the input stream (see also Figure 43):
(-+-) :: SP a1 b1 -> SP a2 b2 -> SP (Either a1 a2) (Either b1 b2)
(sp1 -+- sp2) xs = merge os (sp1 xs1) (sp2 xs2)
where
xs1 = [ x | Left x <- xs ]
xs2 = [ y | Right y <- xs ]
-- os : a synthetic oracle stream
os = map isLeft xs
merge (True:os) (y:ys) zs =
Left y:merge os ys zs
merge (False:os) ys (z:zs) =
Right z:merge os ys zs
isLeft (Left _) = True
isLeft (Right _) = FalseThis solution has some practical problems, however. As it stands above, there is a potentially serious space-leak problem. Consider the evaluation of an expression like
Figure 43. Parallel composition of stream processors using synthetic oracles.
Here, sp2 will never receive any input. This means that(sp1 -+- sp2) [Left n | n<-[1..]]
merge will never need to evaluate the argument
(sp2 xs2), which holds a reference to the beginning of the
input stream via xs2. This would cause all input
consumed by the composition to be retained in the
heap. However, provided that pattern bindings are implemented
properly [Spa93], this problem can be solved by computing
xs1 and xs2 with a single recursive definition that
returns a pair of lists:
split :: [Either a b] -> ([a],[b])
split [] = ([],[])
split (x:xs) =
case x of
Left x1 -> (x1:xs1,xs2)
Right x2 -> (xs1,x2:xs2)
where
(xs1,xs2) = split xsfilter)? What if it wants to output more than one value?
Obviously, if an implementation with this restriction is given
to a programmer, he will invent various ways to get around
it. It is better to provide a solution from the
beginning.
One way to relieve the restriction is to change the representation of stream processors to
thus allowing a stream processor to output a list of values to put in the output stream for every element in the input stream. Unfortunately, with this representation the standard list functions, liketype SP a b = [a] -> [[b]]
map and filter, can no
longer be used in such a direct way. For example, instead of
map f one must use map (\x->[f x]). Serial
composition is no longer just function composition, rather it
is something more complicated and less efficient. Also, it is
still possible to write stream processors that do not obey the
1-1 restriction, leading to errors that can not be detected by
a compiler. Consequently, it is not a good idea to reveal this
representation to the application programmer, but rather
provide the stream-processor type as an abstract type. And
while we are using an abstract type, we might as well use a
better representation.
We call this the continuation-based representation of stream processors. The type has one constructor for each operation a stream processor can perform. The constructors have arguments that are part of the operations (the value to output indata SP i o = NullSP | PutSP o (SP i o) | GetSP (i -> SP i o)
PutSP), and arguments that determine how the
stream processor continues after the operation has been
performed.
The continuation-based representation avoids the problem with
parallel composition that we ran into when using the
list-based representation, since it makes the consumption of
the input stream observable. With list functions, a stream
processor is applied to the entire input stream once and for
all. The rate at which elements are consumed in this list is
not observable from the outside. With the continuation-based
representation, a stream processor must evaluate to GetSP
sp
each time it wants to read a value from the input stream. This
is what we need to be able to merge the output stream in the
right order in the definition of parallel composition.
An implementation of broadcasting parallel composition is
shown in Figure 44. The implementation of tagged parallel
composition is analogous. Note that we arbitrarily choose to
inspect the left argument sp1 first. This means that even if
sp2 could compute and output a value much faster than
sp1, it will not get the chance to do so. Figure 44. Implementation of parallel composition with
the continuation-based representation. Figure 45. Implementation of serial composition with
the continuation-based representation.
With the continuation-based representation, serial
composition can be implemented as shown in Figure 45.
NullSP -*- sp2 = sp2
sp1 -*- NullSP = sp1
PutSP o sp1' -*- sp2 = PutSP o (sp1' -*- sp2)
sp1 -*- PutSP o sp2' = PutSP o (sp1 -*- sp2')
GetSP xsp1 -*- GetSP xsp2 = GetSP (\i -> xsp1 i -*- xsp2 i)
NullSP -==- sp2 = NullSP
PutSP o sp1' -==- sp2 = PutSP o (sp1' -==- sp2)
GetSP xsp1 -==- NullSP = NullSP
GetSP xsp1 -==- PutSP m sp2' = xsp1 m -==- sp2'
GetSP xsp1 -==- GetSP xsp2 = GetSP (\i -> GetSP xsp1 -==- xsp2 i)
A definition of the loop combinator Figure 46. Implementation of loopSP is shown in
Figure 46.
loopSP sp = loopSP' empty sp
where
loopSP' q NullSP = NullSP
loopSP' q (PutSP o sp') = PutSP o (loopSP' (enter q o) sp')
loopSP' q (GetSP xsp) = case qremove q of
Just (i,q') -> loopSP' q' (xsp i)
Nothing -> GetSP (loopSP . xsp)
-- Fifo queues
data Queue
empty :: Queue a
enter :: Queue a -> a -> Queue a
qremove :: Queue a -> Maybe (a,Queue a)
loopSP with the
continuation-based representation.
runSP :: SP a b -> [a] -> [b].
runSP sp xs =
case sp of
PutSP y sp' -> y : runSP sp' xs
GetSP xsp -> case xs of
x : xs' -> runSP (xsp x) xs'
[] -> []
NullSP -> []
Using list functions works well for parallel implementations. Demand is propagated from the output to the input stream by the normal evaluation mechanism of the functional language. Since streams are represented as lists, the standard list functions can be used directly as stream processors.
For sequential implementations, we saw that representing stream processors as functions from streams to streams prevented us from implementing parallel composition. Here, the continuation-based representation seems more attractive, and is the one that we currently employ in the Fudget library. The continuation-based representation also allows stream processors to be detached, moved, and plugged in somewhere else in the program--something that is used in Chapter 25.
Since our implementation is based on a sequential programming language, we do not get true concurrency. As long as all stream processors quickly react to input to avoid blocking other stream processors in the program, this is acceptable in practice. The reactiveness property is not enforced by the compiler, however.
It would be nice to have a representation that works well for both parallel and sequential implementations. Is perhaps the continuation-based representation useful also for parallel implementations? Consider the composition
The first output from the composition should be either the first output from sp1 or the first output from sp2, whichever happens to be ready first. But the parallel composition must evaluate to either(sp1 -*- idSP) -==- sp2
PutSP ..., or GetSP .... In
the first case we have prematurely committed ourselves to taking
the output from sp1 first. In the second case we will not be
able to deliver the first output until after sp2 has delivered
its first output. It is not clear to us how the desired
behaviour should be achieved.The fudget implementation used in the library is highly influenced by the synchronised stream I/O system used in version 1.2 of Haskell [HPJWe92].
main is
Each request constructor represents a specific effect, and is defined in the datatypetype Dialogue = [Request] -> [Response] main :: Dialogue
Request in Haskell 1.2:
data Request = ReadFile String
| WriteFile String String
| ReachChan Chan
| AppendChan Chan String
...ReadFile f is a request for the I/O
system to read the contents of the file with name
f. WriteFile f s is a request for writing s to
a file with name f. Standard input and output are
instances of so called channels: reading the character stream
from standard input is requested by ReadChan stdin, and
AppendChan stdout s is a request to write
s on standard output.
The type of the response that is generated, when a request is
carried out, depends on the request constructor. All
response types are put in the union type Response:
data Response = Success
| Failure IOError
| Str String
| IntResp Int
...Success response, whereas input
requests generate a value tagged with Str,
IntResp, or some other constructor depending on its type. If
a request fails, an error value tagged Failure is
generated.
A program that uses the synchronised stream I/O model can be viewed as an atomic, sequential stream processor, that explicitly uses lists for representing the streams.
We define a fudget of type F hi ho to be a stream
processor that can input messages of type hi or tagged
responses, and outputs ho messages or tagged requests:
We could have used the standard typetype F hi ho = SP (Message TResponse hi) (Message TRequest ho) data Message low high = Low low | High high
Either, but we
prefer using the equivalent type Message for
clarity.
The low-level streams carry I/O requests and
responses. Fudget combinators like >+< and >==<
merge the requests streams from the two argument fudgets. But
when a fudget outputs a request we must be able to send the
corresponding response back to the same fudget. For this
reason, messages in the low-level streams are tagged with
pointers indicating which fudget they come from or should be
sent to. Since a fudget program can be seen as a tree of
fudgets, where the nodes are fudget combinators and the leaves
are atomic fudgets, we have chosen to use paths that
point to nodes in the tree structure:
The messages output from atomic fudgets contain an empty path,type TResponse = (Path,Response) type TRequest = (Path,Request) type Path = [Turn] data Turn = L | R -- left or right
[]. The binary fudget combinators prepend an L
or an R onto the path in output messages to indicate
whether the message came from the left or the right
subfudget. Combinators that combine more than two fudgets
(such as listF) uses a binary encoding of subfudget
positions. On the input side, the path is inspected to find
out to which subfudget the message should be propagated.
As an example, consider the fudget
When f2 wants to perform an I/O request r, it putsf = f1 >==< (f2 >+< f3)
([],r) in its low-level output stream. The
>+< combinator will prepend an L to the path,
since f2 is the left subfudget. so ([L],r) will
appear in the low-level output of f2 >+<
f3. Analogously, the >==< combinator will prepend
an R, so the low-level output from f will
contain ([R,L],r). When a response later appears in
the input stream of f, it will be tagged with the same
path, [R,L], which will cause the combinators to
propagate it to f2.
As should be apparent, the length of the paths is determined directly by the nesting depth of fudget combinators in the program. For programs that are structured roughly as balanced trees of fudgets, the length of the paths thus grow logarithmically with the number of atomic fudgets in the program. Hence, the overhead of constructing and analysing the paths also grows logarithmically with the number of fudgets. In practice, the maximal path length we have observed varies from 4 for trivial programs (the "Hello, world!" program in Section 9.1), 16 for small programs (the calculator in Section 9.8) and 30 for large programs (the proof assistant Alfa in Chapter 33).
Constructing and analysing the paths of messages is not the only source of overhead in the low-level message passing. Some fudget combinators, most notably the filters (see Chapter 24) treat some commands or events specially. They thus need to inspect all messages that pass through them. When a large number of messages have to be sent, the overhead may become too high. In Section 27.5.3 we present a situation in which we encountered this problem, and give a solution.
An implementation of tagged parallel composition of fudgets is
shown in Figure 47. We have reused tagged parallel
composition of stream processors by adding the appropriate tag
adjusting pre and post processors. The other fudget
combinators can be implemented using similar techniques. Figure 47. Tagged parallel composition of fudgets.
>+< :: F i1 o1 -> F i2 o2 -> F (Either i1 i2) (Either o1 o2)
f1 >+< f2 = mapSP post -==- (f1 -+- f2) -==- mapSP pre
where
post msg =
case msg of
Left (High ho1) -> High (Left ho1)
Right (High ho2) -> High (Right ho2)
Left (Low (path,req)) -> Low (L:path,req)
Right (Low (path,req)) -> Low (R:path,req)
pre msg =
case msg of
High (Left hi1) -> Left (High hi1)
High (Right hi2) -> Right (High hi2)
Low (L:path,resp) -> Left (Low (path,resp))
Low (R:path,resp) -> Right (Low (path,resp))
When a request reaches the top level of a fudget program, the
path should be detached before the request is output to the
I/O system and then attached to the response before it is
sent back into the fudget hierarchy. This is taken care of in
Figure 48. A simple version of fudlogue. A simple version of fudlogue is shown
in Figure 48.
This version will suffice for programs where individual
fudgets do not block in their I/O requests. If we want to
react on input from many sources which comes in an unknown
order (e.g. sockets, standard input, the window system,
timeout events), this implementation will not be enough, so
what should we do? We will discuss this more in
Section 22.2. The short answer is that we can
detect when the main fudget has become idle (that is, it
has evaluated to
fudlogue :: F a b -> Dialogue
fudlogue mainF = runSP (loopThroughRightSP routeSP (lowSP mainF))
routeSP =
getLeftSP $ \ (path,request) ->
putSP (Right request) $
getRightSP $ \ response ->
putSP (Left (path,response)) $
routeSP
lowSP :: SP (Message li hi) (Message lo ho) -> SP li lo
lowSP fud = filterLowSP -==- fud -==- mapSP Low
filterLowSP = mapFilterSP stripLow
stripLow (Low low) = Just low
stripLow (High _ ) = Nothingfudlogue
for synchronised stream I/O. It does not handle
asynchronous input.getSP, and does not wait for a
synchronous response). At this point, we perform a system call
(namely select) to wait for input to happen on any of
our sources of events.
getHighSP and
getLowSP waits for high- and low-level messages,
respectively. They are defined in terms of waitForSP
(Section 18.1).
requestF :: F Request Response
requestF = getHighSP $ \ req ->
putSP (Low ([],req)) $
getLowSP $ \(_,response) ->
putSP (High response) $
requestF
ReadChan stdin, because its response is a lazy list
representing the character streams from the standard input.
Files are usually OK to read, a fudget like readFileF
(Section 14.2) can be implemented as
follows:
readFileF :: F String (Either IOError String)
readFileF = post >^=< requestF >=^< ReadFile
where post (Str s) = Right s
post (Failure f) = Left frequestF in the previous section provides
an interface to the Haskell stream I/O system. To program
a fudget with a particular sequential I/O behaviour, a
combinator like
could be used. The argument stream processor-- Preliminary version streamIoF :: SP (Either Response i) (Either Request o) -> F i o streamIoF sp = loopThroughRightF (absF sp) requestF
sp can
talk to requestF using messages tagged Left and
to other fudgets through messages tagged Right. However,
it seems more appropriate to tag messages with the type
Message introduced above, and let the type of streamIoF
be
where-- Final version streamIoF :: K i o -> F i o
We call stream processors of typetype K i o = SP (Message Response i) (Message Request o)
K i o fudget
kernels. Fudget kernels are thus used when defining new atomic fudgets
with particular I/O behaviours. We define some combinators
for describing I/O behaviours in continuation style:
The first three operations correspond directly to the stream-processor combinatorsputHighK :: o -> K i o -> K i o getHighK :: (i -> K i o) -> K i o nullK :: K i o doStreamIOK :: Request -> (Response -> K i o) -> K i o
putSP, getSP and
nullSP, so fudget kernels can be seen as plain stream
processors with access to the I/O system.
The implementations of the combinators introduced in this
section are shown in Figure 49. Figure 49. Fudget kernel combinators.
type K i o = SP (Message Response i) (Message Request o)
streamIoF :: K i o -> F i o
streamIoF kernel = mapSP post -==- kernel -==- mapSP pre
where
pre (High i) = High i
pre (Low (_,resp)) = Low resp
post (High o) = High o
post (Low req) = Low ([],req)
putHighK :: o -> K i o -> K i o
putHighK = putSP . High
getHighK :: (i -> K i o) -> K i o
getHighK = waitForSP high
where
high (High i) = Just i
high _ = Nothing
nullK :: K i o
nullK = nullSP
doStreamIOK :: Request -> (Response -> K i o) -> K i o
doStreamIOK request contK =
putSP (Low request) $
waitForSP low contK
where
low (Low resp) = Just resp
low _ = Nothing
fudlogue can be defined as follows:
fudIO1 :: F a b -> IO ()
fudIO1 f = case f of
NullSP -> return ()
GetSP _ -> return ()
PutSP (High _) f' -> fudIO1 f'
PutSP (Low (path,req)) f' ->
do resp <- doRequest req
fudIO1 (startupSP [Low (path,resp)] f')
that converts requests to corresponding monadic effects.doRequest :: Request -> IO Response
We can also go one step further by throwing out the request
and response datatypes, and use the IO monad directly
to represent effects. This can be implemented by adding a
constructor to the continuation-based stream-processor type:
data F' i o = PutF o (F' i o)
| GetF (i -> F' i o)
| NullF
| DoIoF (IO (F' i o))DoIoF is used to express I/O
effects. This constructor does not have any explicit
argument for the continuation fudget, which instead is
returned from the I/O computation. To connect fudgets to
the I/O system, we use fudIO2:
fudIO2 :: F' i o -> IO ()
fudIO2 f = case f of
NullF -> return ()
GetF _ -> return ()
PutF _ f' -> fudIO2 f'
DoIoF io -> io >>= fudIO2doIoF for plugging in
monadic I/O operations in a fudget:
The fudget combinators are defined just as the corresponding for stream processors, with extra cases for thedoIoF :: IO a -> (a -> F' i o) -> F' i o doIoF io c = DoIoF (map c io)
DoIoF
constructor. For example, in the case of parallel
composition, these are:
DoIoF io >*< g = DoIoF (map (>*< g) io) f >*< DoIoF io = DoIoF (map (f >*<) io)
Asynchronous I/O is necessary to handle events from many sources such as the X server, standard input, and sockets. The implementation of asynchronous I/O is described in Section 22.2.
The communication between a fudget program and the X server uses the library Xlib [Nye90], which is written in C. Xlib defines a number of data types and calls for creating and maintaining windows, drawing in windows and receiving input events.
There is no standardised foreign-language interface for Haskell, so Haskell programs cannot directly call Xlib. To solve this problem, we have implemented a number of interfaces to Xlib: one of which is compiler independent, and three which are specific for HBC, NHC, and GHC. These interfaces are described in Section 22.3.
In X Windows, an application program creates one or more
shell windows. We have already seen in Chapter 9 how the
fudget shellF is used to create a shell window. These
windows appear on the user's desktop and are decorated with a
title bar by the window manager. The window manager allows the
user to manipulate shell windows in various ways, for example,
they might be resized and moved around on the desktop. A shell
window thus corresponds to the user's concept of a window.
From the point of view of the application programmer, a shell window provides an area which can be filled with graphics, and which can ``react'' to events such as mouse clicks, which the X server can report to the application as events. The window has its own coordinate system which has its origin in the upper left corner, regardless of the window's position on the desktop. The window system also ensures that when the application draws in a shell window, only areas that are visible are updated. This implies a simplification for the application programmer, since he does not have to consider other applications that the user has started.
So far, this story holds for most window systems. X Windows goes one step further, and allows the programmer to create more windows within the shell window. These can in turn contain even more windows. Each window has its own coordinate system, and can be moved and resized (but not directly by the user of the application, as was the case with shell windows). If a window is moved, all windows inside it will follow, keeping their position in the local coordinate system. In addition, each window is associated with an event mask, which allows the programmer to control how ``sensitive'' the application should be to user input when the pointer is in the window.
The simplification that the concept of shell windows brought us as application programmers can be carried over to hierarchical windows. If each GUI element is put in its own subwindow, the application program does not need to know the element's position in the shell window when drawing in it, for example. It is also possible to have a large subwindow inside a smaller window. By moving the large window, we get the effect of scrolling an area.
Since each GUI fudget has its own window (possibly containing subwindows), we have also used the possibility to associate each GUI fudget with its own event mask, something that we use to limit the network traffic of events from the server to the application. This was initially an important aspect in Fudgets (see Section 22.3.1), and is still an advantage when running programs over low-bandwidth links.
Using one window per GUI fudget also simplifies the routing of
events inside the application, which receives one single stream of
events from the X server. The handling of events is not centralised,
instead the GUI fudgets handle events by themselves. When the
X server reports a mouse click, the event contains information
about what subwindow was clicked, and the position uses the local
coordinate system of the subwindow. The window information is used
in fudlogue, which maintains a mapping from window
identifiers to GUI fudget paths.
XRequest and XResponse (which can be seen as extensions
to Request and Response), which allow us to
communicate with the X server.data XRequest = OpenDisplay DisplayName | CreateSimpleWindow Path Rect | CreateRootWindow Rect | CreateGC Drawable GCId GCAttributeList | LoadFont FontName | CreateFontCursor Int ...
The remaining two datatypes aredata XResponse = DisplayOpened Display | WindowCreated Window | GCCreated GCId | FontLoaded FontId | CursorCreated CursorId ...
XCommand, which can be seen as
a set of requests without responses, and XEvent, which
encode events that the X server asynchronously reports to the
application.data XCommand = CloseDisplay Display | DestroyWindow | MapRaised | LowerWindow | UnmapWindow | Draw Drawable GCId DrawCommand | ClearArea Rect Bool | ClearWindow | CreateMyWindow Rect ...
data XEvent
= KeyEvent { time::Time,
pos,rootPos::Point,
state::ModState,
type'::Pressed,
keycode::KeyCode,
keySym::KeySym,
keyLookup::KeyLookup }
| ButtonEvent { time::Time,
pos,rootPos::Point,
state::ModState,
type'::Pressed,
button::Button}
| MotionNotify { time::Time,
pos,rootPos::Point,
state::ModState }
| EnterNotify { time::Time,
pos,rootPos::Point,
detail::Detail,
mode::Mode }
| LeaveNotify { time::Time,
pos,rootPos::Point,
detail::Detail,
mode::Mode }
| Expose { rect::Rect,
count::Int }
...fudlogue (see Section 22.2.2).
A number of auxiliary data types that also correspond more or less
directly to definitions found in the Xlib library are shown in
Figure 50. Figure 50. Some of the auxiliary types used by the
interface to Xlib.
-- Resource identifiers
newtype
Display = Display Int
-- and similarly for Window, PixmapId, FontId, GCId, CursorId,
-- ColormapId, ...
-- Type synonyms for readability:
type FontName = String
type ColorName = String
type Time = Int
type Depth = Int
-- GC and Window attributes:
data WindowAttributes
= CWEventMask [EventMask]
| CWBackingStore BackingStore
| CWSaveUnder Bool
...
type GCAttributeList = [GCAttributes Pixel FontId]
data GCAttributes a b = ... -- See Section 27.4.3
-- Various enumeration types:
data EventMask
= KeyPressMask | KeyReleaseMask | ButtonPressMask | ButtonReleaseMask
| EnterWindowMask | LeaveWindowMask | PointerMotionMask
| ExposureMask
...
data BackingStore = NotUseful | WhenMapped | Always
-- Geometry
data Point = Point{xcoord::Int, ycoord::Int}
data Rect = Rect{rectpos::Point, rectsize::Size} -- upper left corner and size
type Size = Point
data Line = Line Point Point -- coordinates of the two end points
groupF: the primitive window creation fudgetGUI fudgets are created with the group fudget:
The type ofgroupF :: K a b -> F c d -> F (Either a c) (Either b d)
groupF resembles >+<, and indicates
that it puts two stream processors in parallel. It will also
create a window which will be controlled by the first stream
processor, which is a kernel (see Section 21.4). All X
commands that the kernel outputs will go to the group fudget's
window, and the X events from the window will go to the kernel.
As the name indicates, groupF also groups the GUI
fudgets in its second argument, in the following sense. Assume
we have the group g:
All the windows that are created by groups inside f will be created inside the window created byg = groupF k f
g, and thus
grouped. A consequence is that if the kernel k decides to
move its window, all groups inside f will follow.
The atomic GUI fudgets are constructed along the pattern
groupF k nullF, that is, they do not have any internal
fudgets, just a kernel controlling a window. As an example,
consider a group fudget of the form
It will have a window with two subwindows, one of which will have yet another subwindow, as is illustrated in Figure 51.groupF k1 (groupF k2 (groupF k3 nullF) >+< groupF k4 nullF)
Figure 51. Four group fudgets. Each group has a kernel stream processor controlling an X window.
A group fudget starts by outputting the command
CreateMyWindow r, where r is a rectangle
determining the size and position of the window in its parent
window. This is a command that does not correspond to any Xlib
call. Instead, it will be intercepted by the closest containing
group fudget, which will see it as a tagged command of the form
(p,CreateMyWindow r). The containing group
fudget will convert this to the request CreateSimpleWindow
p r. When this request reaches fudlogue,
it will be of the form (q,CreateSimpleWindow
p r). From this information, fudlogue will be
able to deduce in which window the new window should be created,
and new window's path is found by concatenating q and
p (see also the end of section
Section 22.2.2).
The observant reader now asks ``What if there is no containing
group fudget?'' The answer is that shellF also counts as
a kind of group fudget, and we know that a shellF is
always wrapped around GUI fudgets. The main difference between
groupF and shellF is that the latter starts by
outputting CreateRootWindow instead of
CreateMyWindow. The request CreateRootWindow is used to
create shell windows.
The group fudget concept can be used for structuring complex
fudgets. One example is buttonGroupF:
It is used in the Fudget library to program push buttons. The enclosed fudget will get messages which indicate what visual feedback is appropriate to give, and when the user actually has clicked in the window. This is an example of a group fudget which is invisible to the user--it only deals with input.buttonGroupF :: F (Either BMevents a) b -> F a b data BMevents = BMNormal | BMInverted | BMClick
As an example of a group fudget which only deals with output, we
can have a look at buttonBorderF,
which is used to draw the three-dimensional border around push buttons, which can look either pressed or released. The familiar button fudgetbuttonBorderF :: F a b -> F (Either Bool a) b
buttonF is a combination of these two group
fudgets and a labelF.
buttonBorderF always is used
immediately inside a buttonGroupF, but this is not
necessary. A good counter example is toggleButtonF,
in which a buttonGroupF
is wrapped around two fudgets: a buttonBorderF which has a
little onOffDispF in it indicating its state, and a
labelF. The user can control the toggle button by clicking
anywhere in the buttonGroupF, including the label. Note
that the group structure in the toggle button coincides with
Figure 51. Moreover, fudgets must be cooperative when performing I/O
tasks. As we have seen in Chapter 21, the I/O
requests from all fudgets in a program are performed in
fudlogue. We must make sure that these requests are of a
transient nature and can be carried out more or less immediately.
For these reasons, the Fudget library makes a distinction between synchronous and asynchronous I/O. Synchronous I/O, where the whole fudget program must wait for the I/O operation to complete, is only used for transient operations. Its implementation is straightforward, as we saw in Section 21.3. Since synchronous I/O is simple to implement, the Fudget library currently uses it when reading and writing to files, and when writing to sockets, standard output and the X server. (In most cases, but not all, these operations are transient, and a future improvement of Fudgets would be to use asynchronous I/O even for these.) When it comes to reading from standard input or sockets, or waiting for events from the X server, asynchronous I/O is used, since these are operations that are likely to block for arbitrary long periods of time.
timerF (Section 14.3) and
socketTransceiverF (Section 26.1) are examples of
fudgets that must use asynchronous I/O to avoid blocking the
whole program. Both of them create descriptors as a first
step.
data Descriptor = SocketDe Socket
| TimerDe Timer
| DisplayDe Display
...Socket) is returned as a
response to the request OpenSocket h p which
opens a socket connection to the port p on host
h. Similarly, a request CreateTimer i d
results in a timer descriptor associated with interval i
and delay d.
Simply creating a descriptor does not result in any asynchronous I/O. A fudget can use the special request
to signal toSelect :: [Descriptor] -> Request
fudlogue that it is interested in
asynchronous input from a specified set of descriptors.fudloguefudlogue maintains a mapping
between descriptors and paths to fudgets. We have just seen that
fudlogue can receive messages of the form (p,
Select ds), which announce that there is a fudget with
path p which waits for the asynchronous input associated
with the descriptors in ds. The function fudlogue
collects all descriptors received in this way from all fudgets in
the program. When the main fudget evaluates to getSP
without an outstanding request, fudlogue knows that it is
time to wait for some asynchronous event to happen. It emits a
Select request, with all collected descriptors as an
argument. The effects of this request areselect, which will wait
for input to arrive on any of the descriptors, or a
timeout, andAsyncInput:
type AsyncInput = (Descriptor, AEvent)
data AEvent = SocketAccepted Socket Peer
| SocketRead String
| TimerAlarm
| XEvent (WindowId, XEvent)AEvent indicates, the response of
Select is the descriptor which became ready, paired with the
data read.
Using the descriptor table, fudlogue is able to route the
received asynchronous input to the waiting fudget.
In addition, fudlogue performs the following translations
to handle events to the GUI fudgets:
fudlogue has an association from
its path to the identifier of its window, and a display
descriptor (the socket connection to the X server). The group
fudgets are unaware of which window or display they are
associated with, so fudlogue adds this information to
the X related commands and requests from GUI fudgets.fudlogue uses to route events from the X server
to the group fudget associated with the window.Request and Response datatypes with
constructors divided in XRequest, XResponse,
XCommand, and XEvent, that correspond to Xlib calls and X
events. (These data types do not provide a complete interface to
Xlib. We have implemented those calls that we found useful and
extended the interface by need. Also, some parameters have been
omitted from some constructors.) Somewhere, the actual I/O that
these requests and commands represent must be carried out, and
this is done in what we call the interface to Xlib. We have
implemented a number of different such interfaces, and they are
described in what follows.
String->String. The first interface to Xlib was done by
outputting the calls and receiving the return values and events
in text form via the standard output and input channels. The
program was connected by a bidirectional pipe to an external C
program that performed the actual Xlib calls. The type of the
function fudlogue was F i o -> String->String.
The advantage with this method is that it is portable. No changes need to be made to the compiler or its associated run-time system. The same C program can be used with another compiler or even another programming language.
The disadvantage with this method is that it is inefficient because of the parsing and printing of commands, return values and events. By printing them in a simple format, the overhead can be kept down, though. Also, for most user-interface tasks, the throughput need not be very high.
fudlogue was changed to F i o
-> Dialogue.
type Dialogue = [Response] -> [Request] data Request = ReadFile String | WriteFile String String | ... -- Extensions | XCommand (XDisplay,XWId,XCommand) | XRequest (XDisplay,XWId,XRequest) | SocketRequest SocketRequest | Select [Descriptor] | ... data Response = Success | Str String | Failure IOError | ... -- Extensions | GotSelect AsyncInput | SocketResponse SocketResponse | XResponse XResponse | ...Figure 52. Extending the Haskell 1.2 dialogue I/O types with requests for the interface to Xlib
The part of HBC's run-time system that handles dialogue I/O is
implemented in C. The procedure that implements the Figure 53. The C function Figure 54. The C function
Requests was modified to handle the XRequest and
XCommand requests by calling a new procedure doxcall
outlined in Figure 53. As can be seen in
Figure 54, a few lines of C code per supported Xlib
call are needed.
PTR doxcall(t, p)
int t; /* tag of the Request */
PTR p; /* pointer to the argument of the Request */
{
PTR response;
p = evaluate(p);
switch(t) {
case XCommand: /* (Display, Window, XCommand) */
p = evalArgs(p,3);
xdocommand((Display *)INTOF(GET1OF3(p)),
INTOF(GET2OF3(p)),
GET3OF3(p));
response=mkconstr0(RSuccess);
break;
case XRequest: /* (Display, Window, XRequest) */
{
PTR xresp;
p = evalArgs(p,3);
xresp=doxrequest((Display *)INTOF(GET1OF3(p)),
INTOF(GET2OF3(p)),
GET3OF3(p));
response=mkconstr1(XResponse,xresp);
}
break;
default:
fprintf(stderr, "Unknown X I/O request ...", ...);
exit(1);
break;
}
return response;
}
void xdocommand(display, wi, p)
...doxcall was added to
HBC's run-time system to handle the extra requests
XCommand and XRequest.
PTR
doxrequest(display,wi,p)
Display *display;
Window wi;
PTR p;
{
PTR rp;
Window parent;
switch(getcno(p)) {
case XRqOpenDisplay: /* DisplayName */
{
char displayname[BUFSIZE];
Display *display;
evalstring(EARG1(p), displayname, sizeof displayname);
display=XOpenDisplay(displayname[0] ? NULL : displayname);
return MkPtrXResp(XRDisplayOpened,display);
}
break;
case XRqCreateRootWindow: /* Rect */
...
...
}
}doxrequest analyses
the XRequest constructor and carries out the
corresponding call to Xlib.
The Fudget library could be ported to NHC by a relatively small effort:
Request and Response types was added, since
none of these are defined in Haskell 1.3.fudlogue function was modified to look like
fudIO1 in Section 21.5.doRequest in Section 21.5:
The effect of this function is a call to the proceduredoXCall :: Request -> IO Response
doxcall
in Figure 53.The implementation of certain combined profiles, as described in [RR96b], collects the needed information in two passes, that is, the program is run twice. In order to create two identical runs, the return values of all I/O operations must be recorded during the first run and then played back during the second run.
In order to allow fudget programs to take advantage of the
latest heap profiling technology, Niklas Röjemo added the
necessary code for recording and playing back the results of the
Xlib calls and other extended I/O operations used by the
Fudget library. As a typical example, the glue code for the
Xlib procedure Figure 55. Changes to the Xlib glue code for two
pass heap profiling. Figure 56. Macros for two pass heap profiling.XOpenDisplay (which we have already seen
in Figure 54) was changed as shown in
Figure 55.
The macros
case XRqOpenDisplay: /* DisplayName */
{
char displayname[1000];
Display *display;
evalstring(EARG1(p), displayname, sizeof displayname);
REPLAY_ONE_AND_SKIP(display)
display=XOpenDisplay(displayname[0] ? NULL : displayname);
RECORD_ONE(display);
return MkPtrXResp(XRDisplayOpened,display);
}
break;
RECORD_ONE and REPLAY_ONE_AND_SKIP
expand to code that records the result during the first run
and recalls it and skips the actual call during the second
run. Their definitions are shown in Figure 56. The
variables replay, record and inputFILE
are set by NHC's run-time system as appropriate.
#define REPLAY_ONE_AND_SKIP(x) if(replay) { REPLAY(x); } else
#define RECORD_ONE(x) if(record) { RECORD(x); }
#define RECORD(x) fwrite((void *)&(x),sizeof(x),1,inputFILE)
#define REPLAY(x) fread((void *)&(x),sizeof(x),1,inputFILE)
The interface to Xlib in GHC is written in a rather ad hoc style
using _ccall_ and _casm_ statements. Today, a nicer
interface could be created using the foreign-language interface
support of Green Card [JNR97].
The purpose of the automatic layout system is to relieve the application programmer of the task to specify the exact position and size of each GUI fudget. This task has several dynamic aspects. To start with, it depends on factors that are not known until the program has started. For example, the size of a text drawn in a label fudget depends on the the font and size chosen, and can only be determined after the label fudget has communicated with the X server. Individual GUI fudgets can also change their size at any time, and the user might resize a shell window. Both these activities may imply that a number of GUI fudgets must change their position and size.
The layout system also simplifies the implementation of the individual GUI fudget, in that it does not have to worry about the place and position of other GUI fudgets. It must only specify an initial request for a size, and the layout system will allocate a place and actual size.
The implementation of the layout system operates by moving and resizing rectangular units corresponding to the group fudgets (Section 22.1). Remember that a group fudget basically consists of a stream processor controlling an X window, possibly with a number of group fudgets inside it. Each group fudget also contains a piece of the layout system, which is responsible for the placement and sizing of each immediate subgroup fudget. The responsibility is only one level deep: a group fudget does not control any group contained in any of its groups. As an example, the group corresponding to k1 in Figure 51 is responsible for the layout of k2 and k4 (but not k 3).
This division of responsibility is natural, since a group is easily
placed and resized by the single Xlib command (
ConfigureWindow). All subwindows inside the group will follow and
keep their relative positions.
The mechanism of the layout system can be studied by looking at the message traffic between a group fudget and its immediate subgroups.
The group fudget has a filter (other filters are described in
Chapter 24), called autoLayoutF, which listens for layout
messages that are output on the low-level streams from the subgroups.
The subgroups decide what sizes they need, and output a layout request.data LayoutMessage = LayoutRequest LayoutRequest | LayoutName String | LayoutPlacer Placer | LayoutSpacer Spacer ...
data LayoutRequest
= Layout { minsize :: Size,
fixedh, fixedv :: Bool }minsize is the requested size, and fixedh
(fixedv) being true specifies that the size is not
stretchable in the horizontal (vertical) direction. (Some placers
use this information to allocate extra space to stretchable boxes
only.)
The layout filter also receives placers and spacers that the
programmer has wrapped around subgroups. Since all layout messages
are tagged with a path, the layout filter can associate the placers
and spacers with the wrapped subgroups, by analysing the paths. The
constructor LayoutName is used in a similar way to associate
a subgroup with a name.
The placers and spacers are functions that decide the actual layout. A placer operates on a list of layout requests, yielding one single request for space needed for the placement of all the associated subgroups. Looking back at the discussion of boxes in Section 11.1, we will recognise that there will be one layout request corresponding to each box.
In contrast to the placers, a spacer takes a single request as an argument, and the layout filter maps it on all requests corresponding to the enclosed boxes associated with the spacer, yielding the same number of requests.
As can be seen from these types, placers and spacers also return a residual function, which we will describe below.type Placer = [LayoutRequest] -> (LayoutRequest, Rect -> [Rect]) type Spacer = LayoutRequest -> (LayoutRequest, Rect -> Rect)
Having collected layout requests and having applied the layout functions to them, the group fudget must decide on one single layout request to output. Since programs should work even if no layout is specified by the programmer, a default placer is wrapped around the subgroups.
The default placer used is called autoP, which picks a suitable
layout based on the layout requests at hand. In the current
implementation, it simply chooses between verticalP and
horizontalP, based on two preferences:
Having produced a single layout request, the group fudget outputs
it, and it will be handled by the enclosing group, unless the group
is a shell group. In this case, the minsize field in the
request is used to set the size of the shell window.
The XEvent type includes constructors that are used to
report changes in layout to the GUI fudgets:
data XEvent = ...
| LayoutPlace Rect
| LayoutSize SizeConfigureNotify event containing the new size to the shell
group fudget. Note that this event is generated regardless of
whether the resize operation was done by the program (as a result
of a layout request) or the user (via the window manager). Anyhow,
the shell group fudget generates an event of the form
LayoutPlace (Rect 0 s), to the layout filter. This informs
the layout filter that the rectangle from the origin to s is
available for the subgroups. Now, the layout filter applies the
residual placers and spacers to this rectangle in a reversed
pattern. Each residual placer will yield a list of rectangles,
where the elements correspond to the list of requests (and thus to
the boxes) that was fed to the original placer. Similarly, residual
spacers are mapped over rectangles to adjust positions of the
associated subgroups.
When this reversed process is finished, the layout filter outputs
one LayoutPlace message to each subgroup, which will move
itself accordingly, pass the message to its layout filter, and so
the process goes on recursively.
When a group receives a LayoutPlace message, it also sends a
LayoutSize message to the kernel stream processor, so that
it can adjust the graphical content of its window to the new
geometry. Note that the kernel only needs to know the size of its
window, and not its place. This is due to the fact that all window
operations use local coordinates.
Request,
Response and others, opens up the possibility to write what we
will call filters, which alter specific aspects of a fudget's
input/output behaviour. Filters have type F a b -> F a b,
which indicates that they do not tamper with the high-level
messages, they only analyse and modify the low-level messages.
A number of problems can be solved by using filters--for example, swapping the meaning of the left and the right mouse buttons, or swapping the black and white colors in GUI fudgets.
In the following sections, we will see two examples of filters from the Fudget library which alter the behaviour of complex fudgets:
loopThroughRightF, and is called
loopThroughLowF:
loopThroughLowF :: SP (Either TRequest TResponse)
(Either TRequest TResponse)
-> F i o -> F i oloopThroughRightF is often used by application
programmers to encapsulate and modify the behaviour of existing
fudgets, loopThroughLowF is used in filters located in
fudlogue and shellF, and can thus modify certain
aspects of all fudgets in an application. The controlling stream
processor, which is the first argument to loopThroughLowF,
receives as input the stream of all tagged requests that are
output from the encapsulated fudgets, and also all tagged
responses directed to the same fudgets. It can analyse and
manipulate these messages in any manner before outputting them,
after which they will continue their way to the I/O system (in
the case of the requests), or the fudgets (in the case of the
responses). The simplest conceivable filter is
which simply passes through all requests and responses undisturbed, and thus acts as the identity filter.loopThroughLowF idSP
It is the role of the cache filter to support this resource
sharing between fudgets. It is part of fudlogue, which
means that all fudgets in the program benefit from the resource
sharing.
The effect of the cache filter is most notable on slow connections
with high round trip delays, such as dialup connections. To
demonstrate this, we have run Cla, one of the demonstration
programs from the Fudget distribution, over a dial-up connection
using PPP and secure shell (ssh, compression rate 9). The
modem speed was 14400 bits
per second, and the round trip delay 250 milliseconds on average. To
eliminate errors due to different compression rates, the program
was started repeatedly, until the startup time converged. Without
the cache filter, the minimum startup time for Cla was
clocked to 133 seconds. When enabling the cache, the startup time
decreased to 9.6 seconds, a speedup factor of over 13. (As a
comparison, we also ran Cla on this slow connection
without compression: the startup times were 274 seconds
with no cache, and 31 seconds with cache. Compression is a good thing!)
The heap usage is also better when the cache is enabled, the peak decreases from 990 to 470 kilobytes.
These figures should not come as a surprise since the GUI in
Cla consists of one display, and 28 push buttons which can share
the same resources.
Using the cache filter means that there is an overhead in the program. Except for drawing commands, the filter will analyse each request that is output. As a result, the calculator startup time is about 5% longer when the X server runs on the same computer as the calculator. In this case, the connection is fast and has negligible round trip delay.
CreateGC
d tgc al, where d is the drawable in which
the GC will be used, tgc is a template GC, and al is
a list of attributes that the new GC should have. The request is
turned into a call to the Xlib function XCreateGC, which
returns a reference to a new GC. This is sent back as the response
GCCreated gc to the requesting fudget, which brings
it to use. When the GC is not needed anymore, the fudget can
explicitly deallocate it by outputting the X command FreeGC
gc.
The idea of using a cache is of course that if a second fudget wants to create a GC with the same template and attributes, we could reuse the first GC, if it is not yet deallocated. So a GC cache maintains table from template and attributes to graphics contexts and reference counts.
It turns out that most resource (de)allocation follows the same
pattern as our scenario, if we abstract from the specific request
and response constructors. This abstraction is captured in the
type RequestType, which expresses whether a request is an
allocation, a deallocation, or something else:
data RequestType a r = Allocate a
| Free r
| OtherAllocate constructor carries allocation
data that the cache filter uses as search key in the resource
table. Similarly, the Free constructor carries the resource
that should be freed. In the case of graphics contexts, the
allocation data are pairs of template GCs and attribute lists, and
the resources are graphics contexts.
The function gcRequestType determines the type of request
for graphics contexts:
gcRequestType :: Request -> RequestType (GCId,GCAttributeList) GCId
gcRequestType r =
case r of
CreateGC d tgc al -> Allocate (tgc,al)
FreeGC gc -> Free gc
_ -> OthercacheFilter is parameterised over
the function that determines the request type:
cacheFilter :: (Eq a,Eq r) => (Request -> RequestType a r)
-> F i o -> F i o
cacheFilter rtf = loopThroughLowF (cache [])
where cache table = ...table is a list of type
[(a, (r, Int))], where the elements are allocation data with
associated resources and reference counts.
The definition of a cache for graphics contexts is now simple:
The Fudget library defines request type functions likegcCacheFilter :: F i o -> F i o gcCacheFilter = cacheFilter gcRequestType
gcRequestType for a number of resources, and the corresponding
cache filters, using the general cacheFilter. All these
filters are combined into allCacheFilter:
allcacheFilter :: F a b -> F a b
allcacheFilter =
fontCacheFilter .
fontStructCacheFilter .
gcCacheFilter .
colorCacheFilter .
bitmapFileCacheFilter .
fontCursorCacheFilter
fudlogue. One should fear that allcacheFilter would impose
a considerable overhead, since all commands must be inspected in
turn by each of the six filters. In practice, the overhead is not
a big problem.stringF) signals its interest in
focus by configuring its event mask to include KeyPressMask,
EnterWindowMask, and LeaveWindowMask. This means that
the fudget can receive keyboard input, and also events when the
pointer enters or leaves the fudget (crossing events). The
crossing events are used to give visual feedback about which
fudget has the focus.
A potential problem with point-to-type controlled focus, is that the user must move a hand back and forth a lot between the keyboard and the pointing device (assuming that the pointer cannot be controlled from the keyboard), if she wants to fill in data in a form that consists of several input fields. It is also easy to touch the pointing device accidentally so that the pointer jumps a little, which could result in a focus change.
These problems vanish when using a click-to-type focus model. With click-to-type, the tight coupling between the pointer position and focus is removed. Instead, the user clicks in an input field to indicate that it should have the focus. The focus stays there until the user clicks in another input field. In addition, if the keyboard can be used for circulating focus between the input fields in a form, it can be filled in without using the pointing device.
A limited variant of this improved input model has been added to the Fudget library as a filter in the shell fudgets, leaving the various GUI fudgets unmodified. The limitation is that the model is only click-to-type as long as the pointer is inside the shell fudget. When the pointer leaves the shell fudget, focus goes to whatever application window is under it, unless the window manager uses click-to-type.
ffMask is a subset:
A simplified implementation of a focus filter is shown in Figure 57.ffMask = [KeyPressMask, EnterWindowMask, LeaveWindowMask]
The focus filters reside immediately inside the shell fudgets. To get keyboard events, no matter the position of the pointer (as long as it is inside the shell window), a group fudget is created around the inner fudgets with a suitable event mask. This is done with
focusFilter :: F a b -> F a b focusFilter f = loopThroughLowF (focusSP []) (simpleGroupF [KeyPressMask] f) focusSP :: [Path] -> SP (Either TRequest TResponse) (Either TRequest TResponse) focusSP fpaths = getSP (either request response) where request (p,r) = case getEventMask r of Just mask | ffMask `issubset` mask -> putSP (Left (p,setEventMask (mask' r)) $ focusSP (p:fpaths) where mask' = [ButtonPressMask] `union` mask _ -> putSP (Left (p,r)) $ focusSP fpaths response (p,r) = if keyPressed r then (putSP (Right (head fpaths, r)) $ focusSP fpaths) else if leftButtonPressed 1 r && p `elem` fpaths then putSP (Right (p,r)) $ focusSP (aft++bef) else putSP (Right (p,r)) where (bef,aft) = break (==path) fpaths -- Auxiliary functions: simpleGroupF :: [EventMask] -> F a b -> F a b getEventMask :: Request -> Maybe [EventMask] setEventMask :: [EventMask] -> Request -> Request keyPressed :: Request -> Bool leftButtonPressed :: Request -> BoolFigure 57. A focus filter.
simpleGroupF, which acts as
a groupF without a kernel.
The filtering is done in focusSP, whose argument
fpaths accumulates a list of paths to the focus fudgets. This is
done by looking for window configuration commands with matching
event masks. The event masks of the focus fudgets is modified to
mask', so that the windows of focus fudgets
will generate mouse button events.
The head of fpaths is considered to own the focus, and
incoming key events are redirected to it. If the user clicks in
one of the focus fudgets, fpaths is reorganised so that
the path of the clicked fudget comes first.
As noted, Figure 57 shows a simplified focus filter. The filter in the Fudget library is more developed; it also handles crossing events, and focus changes using the keyboard. More complex issues, like dynamic creation and destruction of fudgets, are also handled. Still, it ignores some complications, introduced by the migrating fudgets in Chapter 25.
It should also be noted that the X window model supports special focus change events which should rather be used when controlling focus. This fits better with window managers that implement click-to-type.
XChangeGC) must be avoided in the GUI fudgets.
The implementation of filters often involves that a piece of state
must be associated with each GUI fudget. This means that the state
of some GUI fudgets are spread out in the library, in some
sense. One piece resides in the fudget itself as local state, then
there is non-local state in the focus filter, and in the
fudlogue tables, which are used to route asynchronous events. If
fudget state is distributed like this, there is always a danger
that it becomes inconsistent, for example when fudgets move or
die.
[i] -> [o] (if we only consider functions from one
input stream to one output stream). To get the output stream of
such a stream function, one must apply it to the input
stream. Once that is done, there is no easy way to detach the
stream function from the stream again.
Why would one want to do such a detachment? One reason arises if we want a stream processor to run for a while in one environment, and then move it to some other environment and continue running it there. Remember that stream processors are first class values and may be sent as messages. This, together with the fact that there is no difference (in the type) between a stream processor that has been executing for a while and a ``new'' one, allows us to program a combinator that can catch the ``current continuation'' of an arbitrary stream processor whenever we want.
extractSP :: SP i o -> SP (Either () i) (Either (SP i o) o)
extractSP s = case s of
PutSP o s -> PutSP (Right o) $ extractSP s
NullSP -> NullSP
GetSP is -> GetSP $ \m ->
case m of
Right i -> extractSP (is i)
Left () -> PutSP (Left s) $
NullSPextractSP s accepts messages
of the form Right i, which are fed to
s. Output o from s is output as Right
o. At any time, we can feed the message Left () to it,
and it will output the encapsulated stream processor in its
current state as a message, tagged with Left. Note that in
general, the stream processor that is output in this way is not
equal to the original stream processor s.
So when we demand the continuation, extractSP s
outputs it and dies. But why should it die? It might be useful
to have it carry on as if nothing had happened. This reminds us
of cloning of objects, and forking of processes. The
variant is easily programmed, by modifying the last line of
extractSP.
cloneSP :: SP i o -> SP (Either () i) (Either (SP i o) o)
cloneSP s = case s of
PutSP o s -> PutSP (Right o) $ cloneSP s
NullSP -> NullSP
GetSP is -> GetSP $ \m ->
case m of
Right i -> cloneSP (is i)
Left () -> PutSP (Left s) $
cloneSP s We can promote these ideas to fudgets as well, although the
implementation gets more complicated. In the case of a GUI fudget,
some action must be taken to ensure that it brings its associated
window along when it moves, for example. We can then program
drag and drop for any GUI fudget, as illustrated in
Figure 58. In what follows, we will describe a set of
combinators for supporting drag-and-drop in fudget programs.
Figure 58. Pictures showing a fudget we are about to drag,
while dragging, and after dropping it. After the
fudget was dropped, the user changed its
text. Note that the output from the moved fudget
now goes to Drop area 2. Figure 59. Schematic view of an invisible
drag-and-drop fudget (indicated by the dashed frame) which in
this case contains two rectangular drop areas, each of which
contains a number of draggable fudgets. The dotted arrow
indicates what will happen if a user drags the fudget
f1 from the first to the second area: it will be
extracted as a message from the first drop area and reach the
drag-and-drop-fudget, which will bounce it to the second drop
area.
We call the fudgets that the user can drag and drop drag
fudgets, and the areas in which they live drop areas. The
communication of drag fudgets between the drop areas is mediated
by a single invisible drag-and-drop fudget. A schematic
picture of these fudgets is shown in Figure 59.
About to drag
While dragging
After dropping
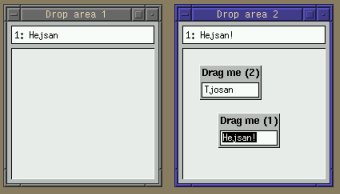
These three types
of fudgets exchange special messages to control the motion of the
drag fudgets. To allow the drag fudgets to communicate with the
rest of the program independently of these control messages, we
pretend for a moment that fudgets have two mid-level
input and output connections.
The typetype SF mi mo hi ho = F (Either mi hi) (Either mo ho)
SF stands for stratified fudget. With this
type, we can think of the message types of stream processors as
stratified in three levels. The drag fudgets are formed by the container dragF:The result type ofdragF :: F a b -> DragF a b type DragF a b = SF DragCmd (DragEvt a b) a b
dragF f is a stratified fudget
in which the high-level streams are connected to f, and
the mid-level streams are used for control, by means of drag
commands and drag events. The drag commands are sent from
the drop area to the drag fudgets during drag. The most
important drag command is DragExtract, and informs the
drag fudget that it has been accepted by another drop area. To
this command, the drag fudget responds with an event containing
itself:
data DragCmd =
DragExtract
| ...
data DragEvt a b =
DragExtracted (DragF a b)
| ...DragEvt. The exact
type of the drag fudget must be visible in the type of drag
events, as well as in other control message types we will
introduce in the following. Thus, the type system ensures that a
dragged fudget cannot be dropped in an area for fudgets of
different type.
The drop area is a stratified variant of dynListF (see
Section 13.4):
The mid-level messages are called the drop commands and drop events, and are used by the drag-and-drop fudget to control the drop areas. Note that both these types are parameterised, because both can carry drag fudgets as messages. As indicated in Figure 59, the drop area contains drag fudgets, which furthermore are tagged. The high-level messages from these are therefore tagged when they enter or leave the drop area.dropAreaF :: SF (DropCmd a b) (DropEvt a b) (Int,a) (Int,b)
There is one drop command that is interesting for the application programmer:
It is used to inject new drag fudgets inside a drop area.dropNew :: DragF a b -> DropCmd a b
Finally, we have the drag-and-drop fudget, which mediates dropped fudgets between drop areas.
The argument todragAndDropF :: SF (t,DropCmd a b) (t,DropEvt a b) c d -> F c d
dragAndDropF is a stratified fudget
whose mid-level messages should be uniquely tagged drop area
messages. The intension is that the stratified fudget contains a
list of drop area fudgets. Such a list can conveniently be created
using a stratified variant of listF:By means oflistSF :: Eq t => [(t,SF a b c d)] -> SF (t,a) (t,b) (t,c) (t,d) listSF sfl = pullEither >^=< listF sfl >=^< pushEither pushEither (Left (t,a)) = (t,Left a) pushEither (Right (t,a)) = (t,Right a) pullEither (t,Left a) = (Left (t,a)) pullEither (t,Right a) = (Right (t,a))
dragF, dropAreaF, and dragAndDropF,
we can program the example (illustrated in Figure 58. As
drag fudgets, we use labelled stringInputF's.
drag :: Show i => DragF String String
drag i = dragF $
labAboveF ("Drag me ("++show i++")") $
((show i++": ")++) >^=< stringInputFi.
We define a drop area with an associated display which shows the output from the drag fudgets in it. We initialise the drop area by creating a drag fudget in it with the same identity as the drop area.
area :: Show i =>
i -> SF (DropCmd String String) (DropEvt String String)
(Int,String) a
area i = vBoxF $
idLeftF (displayF >=^< snd) >==<
startupF [Left $ dropNew $ drag i] dropAreaF
dnd :: F (Int,(Int,String)) (Int,a)
dnd = dragAndDropF $ listSF $
[(t,shellF ("Drop area "++show t) (area t)) | t <- [1..2]]
main = fudlogue dnd
 |
However, we now have timing problem, which can appear if the user moves the pointer quickly and immediately drops the object. There is a delay in the movement of the pointer and the object, since it is the client which is doing the tracking. With a constant delay, the tracking error is proportional to the speed of the pointer, which means that if the speed is large enough, the pointer will not be above the hole anymore. Currently, we do not know if there exists a good solution to this ``drop problem'' in X Windows.
The server is an example of a fudget program which may not have the need for a graphical user interface. However, the server should be capable of handling many clients simultaneously. One way of organising the server is to have a client handler for each connected client. Each client handler communicates with its client via a connection (a socket), but it may also need to interact with other parts of the server. This is a situation where fudgets come in handy. The server will dynamically create fudgets as client handlers for each new client that connects.
We will also see how the type system of Haskell can be used to associate the address (a host name and a port number) of a server with the type of the messages that the server can send and receive. If the client is also written in Haskell, and imports the same specification of the typed address as the server, we know that the client and the server will agree on the types of the messages, or the compiler will catch a type error.
The type of sockets that we consider here are Internet stream sockets. They provide a reliable, two-way connection, similar to Unix pipes, between any two hosts on the Internet. They are used in Unix tools like telnet, ftp, finger, mail, Usenet and also in the World Wide Web.
www.cs.chalmers.se. The
port number distinguishes different servers running on the same
host. Standard services have standard port numbers. For example,
WWW servers are usually located on port 80.
The Fudget library uses the following types:
The fudgettype Host = String type Port = Int
allows a client to connect to a server and communicate with it.(Footnote: The library also provides combinators that give more control over error handling and the opening and closing of connections.) Chunks of characters appear in the output stream as soon as they are received from the server (compare this withsocketTransceiverF :: Host -> Port -> F String String
stdinF in Section 14.1).
The simplest possible client we can write is perhaps a telnet client:
telnetF host port = stdoutF >==<
socketTransceiverF host port >==<
stdinFA simple fudget to create servers is
The server allows clients to connect to the argument port on the host where the server is running. A client is assigned a unique number when it connects to the server. The messages to and fromsimpleSocketServerF :: Port -> F (Int,String) (Int,String)
simpleSocketServerF are strings tagged with such client
numbers. Empty strings in the input and output streams mean that
a connection should be closed or has been closed, respectively.
This simple server fudget does not directly support a program structure with one handler fudget per client. A better combinator is shown in the next section.
String. However, when we write both clients
and severs in Haskell, we may want to use an appropriate data
type for messages sent between clients and server, as we would
do if the client and server were fudgets in the same program. In
this section we show how to abstract away from the actual
representation of messages on the network.
We introduce two abstract types for typed port numbers and typed server addresses. These types will be parameterised on the type of messages that we can transmit and receive on the sockets. First, we have the typed port numbers:
The client program needs to know the typed address of the server:data TPort c s
In these types, c and s stand for the type of messages that the client and server transmit, respectively.data TServerAddress c s
To make a typed port, we apply the function tPort on a port
number:
ThetPort :: (Show c, Read c, Show s, Read s) => Port -> TPort c s
Show and Read contexts in the signature tells
us that not all types can be used as message types. Values will be
converted into text strings before they are transmitted as a
message on the socket. This is clearly not very efficient, but it
is a simple way to implement a machine independent protocol.
Given a typed port, we can form a typed server address by specifying a computer as a host name:
For example, suppose we want to write a server that will run on the hosttServerAddress :: TPort c s -> Host -> TServerAddress c s
animal, listening on port 8888. The clients
transmit integer messages to the server, which in turn sends
strings to the clients. This can be specified byA typed server address can be used in the client program to open a socket to the server by means ofthePort :: TPort Int String thePort = tPort 8888 theServerAddr = tServerAddress thePort "animal"
tSocketTransceiverF:
tSocketTransceiverF :: (Show c, Read s) =>
TServerAddress c s -> F c (Maybe s)Show and Read contexts appear, since
this is where the actual conversion from and to text strings
occurs. The fudget tSocketTransceiverF will output an
incoming message m from the server as Just m,
and if the connection is closed by the other side, it will output
Nothing.
In the server, we will wait for connections, and create client
handlers when new clients connect. This is accomplished with
tSocketServerF:
tSocketServerF :: (Read c, Show s) =>
TPort c s
-> (F s (Maybe c) -> F a (Maybe b))
-> F (Int,a) (Int,Maybe b)tSocketServerF takes two arguments, the first one is
the port number to listen on for new clients. The second
argument is the client handler function. Whenever a new client
connects, a socket transceiver fudget is created and given to
the client handler function, which yields a client handler
fudget. The client handler is then spawned inside
tSocketServerF. From the outside of tSocketServerF, the
different client handlers are distinguished by unique integer
tags. When a client handler emits Nothing,
tSocketServerF will interpret this as the end of a connection,
and kill the handler.
The idea is that the client handler functions should use the
transceiver argument for the communication with the
client. Complex handlers can be written with a
loopThroughRightF around the transceiver, if desired. In many
cases though, the supplied socket transceiver is good enough as a
client handler directly. A simple socket server can therefore be
defined by:
simpleTSocketServerF :: (Read c, Show s) =>
TPort c s -> F (Int,s) (Int,Maybe c)
simpleTSocketServerF port = tSocketServerF port idFirst, we define a typed port to be used by both the client and the server. We put this definition in a module of its own. Suppose that the client sends integers to the server, which in turn can send strings:
We have picked an arbitrary port number. Now, if the client is as follows:module MyPort where myPort :: TPort Int String myPort = tPort 9000
and the servermodule Main where -- Client import MyPort ... main = fudlogue (... tSocketTransceiverF myPort ...)
then the compiler can check that we do not try to send messages of the wrong type. Of course, this is not foolproof. There is always the problem of having inconsistent compiled versions of the client and the server, for example. Or one could use different port declarations in the client and the server.module Main where -- Server import MyPort ... main = fudlogue (... tSocketServerF myPort ... )
Now, what happens if we forget to put a type signature on
myPort? Is it not possible then that we get inconsistent message
types, since the client and the server could instantiate
myPort to different types? The immediate answer is no, and this
is because of a subtle property of Haskell, namely the
monomorphism restriction. A consequence of this restriction is
that the type of myPort cannot contain any type
variables. If we forget the type signature, this would be the
case, and the compiler would complain. It is possible to
circumvent the restriction by explicitly expressing the context in
the type signature, though. If we do this when defining typed
ports, we shoot ourselves in the foot:
We said that this was the immediate answer. The real answer is that if the programmer uses HBC, we might get inconsistent message types, since it is possible to give a compiler flag that turns off the monomorphism restriction, which circumvents our check. This is a feature that we have used a lot (see also Section 40.1).module MyPort where myPort :: (Read a, Show a) => TPort a String -- Wrong! myPort = tPort 9000
Figure 60. The calendar client.
The entries in the calendar can be edited by everyone. When that
happens, all calendar clients should be updated immediately.
The calendar consists of a server maintaining a database, and the clients, running on the workstations.
databaseSP, and a
tSocketServerF, where the output from the stream processor goes
to tSocketServerF, and vice versa
(Figure 61). The program appears in
Figure 62.
Figure 61. The structure of
server. The small fudgets are client handlers created inside the socket server.
The stream processor
module Main where -- Server import Fudgets import MyPort(myPort) main = fudlogue (server myPort) data HandlerMsg a = NewHandler | HandlerMsg a server port = loopF (databaseSP [] [] >^^=< tSocketServerF port clienthandler) clienthandler transceiver = putSP (Just NewHandler) (mapSP (map HandlerMsg)) >^^=< transceiver databaseSP cl db = getSP $ \(i,e) -> let clbuti = filter (/= i) cl in case e of Just handlermsg -> case handlermsg of NewHandler -> -- A new client, send the database to it, -- and add to client list. putsSP [(i,d) | d <- db] $ databaseSP (i:cl) db HandlerMsg s -> -- Tell the other clients, putsSP [(i',s) | i' <- clbuti] $ -- and update database. databaseSP cl (replace s db) Nothing -> -- A client disconnected, remove it from -- the client list. databaseSP clbuti db replace :: (Eq a) => (a,b) -> [(a,b)] -> [(a,b)] replace = ...Figure 62. The calendar server.
databaseSP maintains two values:
the client list cl, which is a list of the tags of the
connected clients, and the simple database db, organised
as a list of (key,value) pairs. This database is sent to newly
connected clients. When a user changes an entry in her client,
it will send that entry to the server, which will update the
database and use the client list to broadcast the new entry to
all the other connected clients. When a client disconnects, it
is removed from the client list. The client handlers (
clienthandler) initially announce themselves with
NewHandler, then they apply HandlerMsg to incoming
messages.The type of the (key,value) pairs in the database is the same
as the type of the messages received and sent, and is defined
in the module MyPort:
module MyPort where
import Fudgets
type SymTPort a = TPort a a
myPort :: SymTPort ((String,Int),String)
-- e.g. (("Torsdag",13),"Doktorandkurs:")
port = tPort 8888Structure editors of various kinds are programs that can make good use of graphics. Examples of such programs are drawing programs, WYSIWYG word processors, file managers, etc. The common characteristic is that they allow you to manipulate a graphical representation of some object on the screen, for example, by selecting a part of the object and performing some editing operation on it (for example, making a word italic in a word processor, or deleting a file in a file manager). The editing operations performed by the user can lead to marginal or radical changes to the structure of the object and its graphical representation. The editor will need to have an efficient mechanism for updating the screen to reflect these changes. The fudget for graphics that we describe in this chapter supports this.
The Fudget library components we have seen so far allow you to build
user interfaces that consist of a number of parts that communicate,
but we have not seen any mechanisms that allow an arbitrary part to
be selected by the user and perhaps replaced by something else, so
we have not seen a general mechanism for building structure
editors. Some basic fudgets, like
toggleButtonF and stringF can be seen as
structure editors for particular structures (booleans and strings,
respectively). The later sections in this chapter present data types
and fudgets that can be used as a starting point when building more
general structure editors. In Chapter 28 we go on and
describe combinators more directly aimed at building structure
editors, or syntax directed editors.
The support for graphics in the Fudget library was prompted by the development of the syntax directed editor Alfa (Chapter 33), and functionality was added to the fudget system as needed for that particular purpose. Some development was also prompted by the work on the web browser described in Chapter 32.
GraphicGraphic many times.
Many of the GUI fudgets
presented in Chapter 9 display graphics. Recall, for example,
buttonF:
It has an argument that determines what is displayed inside the button. In early versions of the Fudget library, the type ofbuttonF :: (Graphic a) => a -> F Click Click
buttonF was
but later, the classbuttonF :: String -> F Click Click
Graphic was introduced and many fudgets
were generalised from displaying only strings to displaying
arbitrary graphical objects. Since the new types are more general
than the old ones, the changes are backwards compatible (old
programs continue to work unmodified).(Footnote: This kind of
change can actually cause ambiguous overloading.)
The Graphic class serves a purpose similar to that of the Show
class: types whose values have graphical representations are made
instances of the Graphic class, just like types whose values have
textual representations are instances of the Show class. As with the
Show class, the methods of Graphic class are not often used
directly, except when defining new instances, and we discuss them in
a later section. The library provides instances in the Graphic class
for many standard types.
Graphic class, we take a look at the low-level interface that
allows a fudget to draw something in its window.
The Fudgets GUI toolkit is built on top of the Xlib [Nye90] library level of the X Windows system [SG86] (as described in Section 22.1). This shines through in the Fudget library support for graphics: the primitive drawing operations available in the fudget library correspond directly to what is provided by Xlib.
An interface to the Xlib library calls for
drawing geometrical shapes and strings is provided through the data
type Figure 63. The type DrawCommand shown in Figure 63.
Apart from the parameters describing the shape to be drawn, the
Xlib calls have some additional parameters that are not present in
the constructors of the
data DrawCommand
= DrawLine Line
| DrawImageString Point String
| DrawString Point String
| DrawRectangle Rect
| FillRectangle Rect
| FillPolygon Shape CoordMode [Point]
| DrawArc Rect Int Int
| FillArc Rect Int Int
| CopyArea Drawable Rect Point
| CopyPlane Drawable Rect Point Int
| DrawPoint Point
| CreatePutImage Rect ImageFormat [Pixel]
| DrawLines CoordMode [Point]
...DrawCommand provides an interface to the Xlib
library calls for drawing geometrical shapes and strings.DrawCommand type. As a typical
example of the relationship between the Xlib calls and the
constructors, consider XDrawLine:
A drawableXDrawLine(display, d, gc, x1, y1, x2, y2) Display *display; Drawable d; GC gc; int x1, y1, x2, y2;
d (a window or a pixmap) and
a graphics context gc are supplied by the
fudget that outputs the drawing command. The type XCommand
(see Section 22.1.1) contains
the following constructor for outputting drawing commands:
The display argument can be determined from the drawable. (The current Fudget library supports only one display connection, so nothing extra is needed for this.)data XCommand = ... | Draw Drawable GCId DrawCommand | ...
BitmapFileDrawCommand, the Fudget library also supports the Xlib
library call XReadBitmapFile for reading images (bitmaps)
from files:
This means that we can easily create a data type that allows us to use images stored in files as graphical objects.data XRequest = ... | ReadBitmapFile FilePath | ... data XResponse = ... | BitmapRead BitmapReturn | ... data BitmapReturn = BitmapBad | BitmapReturn Size (Maybe Point) PixmapId
As you can see in Figure 64, by using the typedata BitmapFile = BitmapFile FilePath instance Graphic BitmapFile where ...
BitmapFile, a program that loads an image from a file and
displays it is as just as simple as the "Hello, world!" program
(see Section 9.1):
Figure 64. The graphical version of the "Hello, world" program is just as simple as the textual version in Section 9.1.
FlexibleDrawing
The first argument of thedata FlexibleDrawing = FlexD Size Bool Bool (Rect -> [DrawCommand]) instance Graphic FlexibleDrawing where ...
FlexD constructor indicates a
nominal size, but the actual size is determined by the fudget
layout system and depends on the context. The next two
arguments indicate the stretchiness, that is, whether the size
should be fixed horizontally and vertically, respectively.
The last argument is a function that should produce drawing commands that draw within the given rectangle. The argument is a rectangle rather than just a size to make flexible drawings more efficient to use as parts of structured graphical objects. Although the drawing function could draw completely different things for different rectangle position and sizes, changing the position is expected to have no other effect than a translation, that is,
wheref (Rect pos size)=moveDrawCommands (f (Rect origin size)) pos
moveDrawCommands,
moves (translates) drawing commands. Changing the size is expected make the function adjust the drawing to fill the available space, typically by stretching it.moveDrawCommands :: [DrawCommand] -> Point -> [DrawCommand]
As an example, here are flexible drawings for filled rectangles, horizontal lines and vertical lines:
A sample usage can be seen in Figure 66.filledRect, hFiller, vFiller :: Int -> FlexibleDrawing filledRect = filler False False hFiller = filler False True vFiller = filler True False filler fh fv d = FlexD (Point d d) fh fv (\r->[FillRectangle r])
FlexibleDrawing, we can easily
define a function for creating graphical objects of a fixed
size:
The arguments are a list of drawing commands to draw the desired shape and a size. The commands are expected to draw within a rectangle of the indicated size, with the origin as the upper left corner.(Footnote: Instead of leaving it to the user to indicate the size of the drawing, it would be possible to compute a bounding rectangle by inspecting the drawing commands, but doing it accurately in the general case is rather involved and would be less efficient.)fixedD :: Size -> [DrawCommand] -> FlexibleDrawing fixedD size dcmds = FlexD size True True drawit where drawit (Rect pos _) = moveDrawCommands dcmds pos
Notice that depending on how you define your
FlexibleDrawing value, you may get very different operational
behaviour. Using fixedD, you will get a value containing
a reference to a list of drawing commands that will be retained
in the heap and translated to the appropriate position (by
moveDrawCommands) each time the drawing is used. For
FlexibleDrawings created like filler above, the drawing
commands may be recomputed and thrown away each time the drawing
is used. So, although the result on the screen will be the same,
how much recomputation that occurs and how much memory is used
depends on details in how the program is written and what kind
of lambda lifting the compiler does (whether it supports full
laziness [Kar92]).
Drawing to take care of these
needs.
So, composite drawings are trees. The leaves (built with the constructordata Drawing label leaf = AtomicD leaf | LabelD label (Drawing label leaf) | AttribD GCSpec (Drawing label leaf) | SpacedD Spacer (Drawing label leaf) | PlacedD Placer (Drawing label leaf) | ComposedD [Drawing label leaf] instance Graphic leaf => Graphic (Drawing label leaf) where ... placedD :: Placer -> [Drawing l a] -> Drawing l a placedD p ds = PlacedD p (ComposedD ds)
AtomicD) can contain values of any type, but as seen
from the instance declaration above, the drawing can be
displayed only if the leaf type is an instance of the Graphic
class. The internal nodes can contain:AttribD) that are in effect
in the subtree of the node. These are discussed further below.SpacedD and PlacedD) from the
ordinary fudget layout system (Chapter 11).LabelD). These have no graphical effect.ComposedD).
Most of the time when drawings
are composed, it is useful to also specify a layout, so rather than
using the constructor ComposedD directly, you use the function
placedD.Drawing type is an instance of the Graphic
class, drawings can be displayed by GUI fudgets that create labels,
buttons, menus, displays and so on. There is also a fudget that makes
use of the properties of the Drawing type:
hyperGraphicsF :: (Eq lbl, Graphic gfx) =>
Drawing lbl gfx -> F (lbl, Drawing lbl gfx) lblhyperGraphicsF can thus be the starting point for simple
graphical browsers and editors.
DPath identify parts of drawings.
Figure 65. Some functions for manipulating parts of drawings.
Drawing, all the leaves must have the same type.
Although you could
draw anything using only leaves of type FlexibleDrawing,
it would be more convenient to be able to mix
different types of leaves. For this purpose, the Fudget library
provides the following type that makes use of existentially
quantified types [LO92]:
In the definition ofdata Gfx = (Graphic ?a) => G ?a instance Graphic Gfx where ... -- trivial g :: Graphic a => Drawing lbl Gfx g = AtomicD . G
Gfx, ?a is an existentially
quantified type variable. The context (Graphics ?a) =>
limits the domain of the variable to the types in the Graphic
class. The result is that the constructor G can be
applied to a value of any type in the Graphic class, yielding
a value of type Gfx. When you later use pattern matching
to extract the argument of G, you will not know what type
it has, but you will know that the type is in the Graphic
class, so you can apply the methods of that class on it. So,
making Gfx an instance of the Graphic class becomes
trivial. (The instance declaration is shown in
Figure 71).
An example where strings and a Figure 66. A sample drawing with leaves of
different types.FlexibleDrawing are mixed in a
Drawing is shown in Figure 66.
placedD verticalP [SpacedD centerS (g "1"),
g (hFiller 1),
g "x+y"]
![]()
The use of existential types gives us a way of packaging data with the methods that operate on it and abstract away from the concrete representation of the data. This is reminiscent of how data abstraction is achieved in object-oriented programming. (The reader is referred to [CW85] for a fuller discussion of the relation between existential types, data abstraction and object-oriented programming.)
Fonts can be specified by font names, but before they can be used, they have to be converted to font identifiers. Also, if you want to know how much space the text you draw will take up, you need obtain a data structure containing metric information on the font.
The data types provided by the
Fudget library for specify drawing attributes are shown below.
The types ColorSpec and FontSpec
are described further in the next section.
To include drawing attributes in adata GCSpec = SoftGC [GCAttributes ColorSpec FontSpec] | HardGC GCtx data ColorSpec -- see below data FontSpec -- see below data GCAttributes color font = GCFunction GCFunction | GCForeground color | GCBackground color | GCLineWidth Width | GCLineStyle GCLineStyle | GCFont font | GCCapStyle GCCapStyle | GCFillStyle GCFillStyle | GCTile PixmapId | GCStipple PixmapId ... data GCtx = GC GCId FontStruct data FontStruct -- abstract type for font metric info data GCId -- An Xlib GC type Width = Int dataGCFunction= GXclear | GXand | GXandReverse | GXcopy | ... | GXset data GCLineStyle = LineSolid | LineDoubleDash | LineOnOffDash data GCCapStyle = CapNotLast | CapButt | CapRound | CapProjecting data GCFillStyle = FillSolid | FillTiled | FillStippled | FillOpaqueStippled
Drawing
(defined above), you use the constructor AttribD
applied to a GCSpec, which usually is the constructor
SoftGC applied
to a list of attributes containing high-level specifications of
fonts and colors. However, before the drawing can be displayed, this
high-level specification must be converted into a GC. In addition, to
be able to automatically determine the size of text, the metric
information for the specified font is required. The high-level
drawing attributes are therefore converted into a value of type
GCtx
by fudgets that display drawings. This conversion may require calls
to Xlib library functions like XLoadQueryFont,
XAllocNamedColor and XCreateGC.
For drawings that are to be displayed many times, making
these calls every time can cause a noticeable performance
degradation, so the library provides a way to create
GCtx values in
advance. These can then be included in drawings using
GCSpecs with
the constructor HardGC. The drawing can then be displayed without
making any calls except for the necessary drawing commands. The
reason for choosing the names SoftGC and HardGC is that the
subdrawings of a node setting the drawing attributes using the
SoftGC alternative, inherit the attributes not present in the
GCAttributes list from the parent drawing, whereas with
the HardGC
alternative, all attributes are taken from the given GCtx.
The following types are instances of theclass ColorGen a where ... data ColorSpec -- an abstract type colorSpec :: ColorGen a => a -> ColorSpec class FontGen a where ... data FontSpec -- an abstract type fontSpec :: FontGen a => a -> FontSpec
ColorGen class and can be used to specify
colors:
Values of the RGB type specifies the intensities of the primary colors red, green and blue, using 16-bit integers.type ColorName = String -- color names, as used by Xlib data RGB = RGB Int Int Int -- RGB values, as used by Xlib data Pixel -- previously obtained pixel values
RGB 0 0 0 is black, and RGB 65535
65535 65535 is white.
The following types are instances of the FontGen class and
can be used to specify fonts:
The canonical way of including font and color specifications in a drawing is to do something like this:type FontName = String -- font names as used by Xlib data FontStruct -- a previously obtained FontStruct
blueHelloMsg =
AttribD (SoftGC [GCForeground (colorSpec "blue"),
GCFont (fontSpec "-*-times-*-r-*-18-*")]),
(g "Hello, world!")
bgD, fgD :: ColorGen color =>
color -> Drawing lbl leaf -> Drawing lbl leaf
fontD :: FontGen font =>
font -> Drawing lbl leaf -> Drawing lbl leaf
blueHelloMsg = fgD "blue" $ fontD "-*-times-*-r-*-18-*" $
g "Hello, world!"GCtx values in the drawings you construct. For this
purpose, the Fudget library provides the following:
wCreateGCtx :: (FontGen b, ColorGen a) =>
GCtx -> [GCAttributes a b] -> (GCtx -> F c d) -> F c d
rootGCtx :: GCtxwCreateGCtx allows you to
create GCtx values, by modifying a template GCtx.
You can start from
rootGCtx which contains the default settings for all attributes.
Drawings be implemented? Drawings are
trees, composed from leaves containing simple graphical objects,
using placers and spacers from the ordinary fudget layout system. A
natural solution thus seems to be to implement new fudgets for
displaying simple graphical objects and then display composed
drawings by composing fudgets that display the leaves. While this at
first seems like a simple and elegant solution that gives us maximal
reuse of existing Fudget library components, remember that we not
only want to display drawings: to build structure editors we also
need a mechanism that lets the user select and manipulate parts of a
structure. We would need to set up a structure where every node in a
Drawing is represented by a fudget, and a communication structure
which allows us to communicate which each node fudget. Further, in
order to be able to replace arbitrary nodes with new drawings, we
would have to use the combinator dynF (Section 13.4)
at each node.
We tried this approach, but when taking all requirements into account, this seemingly natural solution became rather tricky. It also turned out to be rather inefficient and there are several possible reasons for this:dynF :: F a b -> F (Either (F a b) a) b
graphicsF, to display complete
drawings in one window.
This has proved to be reasonably efficient. It has allowed
us to implement usable, non-trivial applications, the syntax directed
editor Alfa (Chapter 33)
and the web browser WWWBrowser (Chapter 32) being the largest. A
drawback is that some functionality (most notably hit detection
and clipping) that in principle could be
handled by the window system (and it was in the ``natural'' solution)
had to be duplicated in the implementation of
graphicsF. The fudget graphicsF
could actually be seen as an implementation of a simple window
system!
graphicsFgraphicsF is intended to satisfy all the needs for
displaying graphics within the Fudget library, and also be the
ground on which applications like syntax directed editors and
web browsers can be built, it has been made fairly general. In
addition to just displaying graphics, graphicsFgraphicsF only accepted complete drawings
as input, either the entire window would have to be redrawn
after each change, or expensive computations would be needed
to calculate the difference between the new and the old
drawing.graphicsF
indicates which part of a
drawing a mouse click occurred in.graphicsF is:
The definitions of the message typesgraphicsF :: (Graphic a) => F (GfxCommand a) GfxEvent
GfxCommand and
GfxEvent are show in Figure 67. The constructor
ChangeGfx creates messages that allow you to replace or modify
the graphical object being displayed. The argument is a list of
changes. Each change has the form
where path selects which part of the object should be changed, hilite switches on or off highlighting and opt_repl is an optional replacement for the selected part.(path,(hilite,opt_repl))
graphicsF is actually a simplification of
graphicsGroupF,
graphicsGroupF :: (Graphic gfx) =>
(F a b) -> F (Either (GfxCommand gfx) a)
(Either GfxEvent b)groupF, discussed in Section 22.1.2, can
contain subfudgets. The fudget activeGraphicsF (discussed
in Section 32.3) for
displaying drawing with active parts (for example forms in a web
browser) is built on top of graphicsGroupF.
There are also customisable versions of these fudgets, allowing
you to change parameters like the event mask, border width and
resizing policy. Figure 67. The message types used by
data GfxCommand gfx
= ChangeGfx [(DPath,(Bool,Maybe gfx))]
| ChangeGfxBg ColorSpec
| ChangeGfxBgPixmap PixmapId Bool -- True = free pixmap
| ShowGfx DPath (Maybe Alignment,Maybe Alignment)
-- makes the selected part visible
| BellGfx Int -- sound the bell
| GetGfxPlaces [DPath] -- ask for rectangles of listed paths
data GfxEvent
= GfxButtonEvent { gfxState :: ModState,
gfxType :: Pressed,
gfxButton:: Button,
gfxPaths :: [(DPath,(Point,Rect))] }
| GfxMotionEvent { gfxState :: ModState,
gfxPaths :: [(DPath,(Point,Rect))] }
| GfxKeyEvent { gfxState::ModState,
gfxKeySym::KeySym,
gfxKeyLookup::KeyLookup }
| GfxPlaces [Rect] -- response to GetGfxPlaces
| GfxResized Size
graphicsF.
graphicsFgraphicsGroupF is implemented using
groupF:
The behaviour of the fudget is thus implemented in the fudget kernelgraphicsGroupF subfudgets = groupF graphicsK subfudgets graphicsK = ...
graphicsK. Here is roughly what graphicsK does in
the course of displaying a graphical object.
graphicsK through the appropriate low-level messages.
The result is a value of type MeasuredGraphics
(Figure 68),
containing leaves of known sizes (i.e., with known
LayoutRequests), GCtxs and placers/spacers. The conversion from an arbitrary graphical object to a value of type
Figure 68. The type
MeasuredGraphics.
MeasuredGraphics is done using the methods of the
Graphic class. These are shown in Figure 69. Sample instance
declarations are shown last in this section.
class Graphic a where measureGraphicK :: a -> GCtx -> Cont (K i o) MeasuredGraphics measureGraphicListK :: [a] -> GCtx -> Cont (K i o) MeasuredGraphics -- Default method for lists: measureGraphicListK xs gctx cont = ... -- converts xs one element at a time and appliesComposedM-- to the resulting list.Figure 69. The methods of the
Graphicclass.
CompiledGraphics
(Figure 70), containing
bounding rectangles and drawing commands for all the parts.
This step is taken by a pure function:
compileMG :: MeasuredGraphics
-> (CompiledGraphics, LayoutRequest)
Figure 70. The type
CompiledGraphics.
Expose events are received,
the drawing commands of the parts whose bounding rectangles
intersect with the damaged rectangles can efficiently be extracted
and output.
Notice that the drawing commands are kept in the form of
XCommands in the CompiledGraphicss. This means that they can
be output as they are. No temporary data structures need
to be created when responding to an Expose event. This
fact, in combination with the use of bounding rectangles
allows Expose events to be handled very
efficiently. This is noticeable in applications like
WWWBrowser and Alfa.MeasuredGraphics and
inserted in the old MeasuredGraphics at the appropriate place. (Paths
are preserved when a Drawing is converted into a
MeasuredGraphics.) A new CompiledGraphics is then computed from the
new MeasuredGraphics. Guided by the paths of the changes and the
differences between the bounding rectangles of the corresponding
parts in the old and new CompiledGraphics, only those parts that
have actually changed, or have moved because of the changes, are
redrawn.graphicsF is that
it does not handle overlapping parts properly, not because
overlapping parts would be too difficult to handle in the
current solution, but simply because it has not been important
in the applications where graphicsF has been used so far. This
means that a drawing with overlapping parts can look different
after part of it has been redrawn in response to an
Expose event.
Finally, some sample instance declarations for the
Figure 71. Some sample instances for the
Graphic class are shown in Figure 71.
instance Graphic Gfx where
measureGraphicK (G x) = measureGraphicK x
instance Graphic FlexibleDrawing where
measureGraphicK (FlexD s fh fv drawf) gctx k =
k (LeafM (plainLayout s fh fv) gctx drawf)
-- plainLayout is defined in Section 27.6.2.
instance Graphic Char where
measureGraphicK c = measureString [c]
measureGraphicListK = measureString
instance Graphic a => Graphic [a] where
measureGraphicK = measureGraphicListK
instance Graphic Int where -- and similarly for other basic types
measureGraphicK i = measureString (show i)
measureString s gctx@(GC gc fs) k =
let r@(Rect _ size) = string_rect fs s
d = font_descent fs
a = font_ascent fs
p1 = Point 0 a -- left end of base line reference point
p2 = Point (xcoord size) a -- right end of base line ref point
drawit (Rect p (Point _ h)) = [DrawString (p+(Point 0 (h-d))) s]
in k (LeafM (refpLayout size True True [p1,p2]) gctx drawit)
-- refpLayout is defined in Section 27.6.2.
Graphic class.
graphicsFgraphicsF recomputes the layout of the complete drawing. None
of the old layout computations are utilised in this step. This
may put an upper limit on how big objects can be handled with
reasonable response times in a structure editor. A better
solution would be to reuse layout information for parts that are
not affected by a change. This is done in the ordinary fudget
layout system (see Chapter 23).
Large drawings consist of many DrawCommands. Outputting
these one at a time in low-level messages turned out to entail a
considerable overhead. For example, redrawing the window after a
page scroll in the editor Alfa (Chapter 33) in a typical
situation could take 1 second. In an attempt to improve this, we
added a new constructor to the XCommand type:
It allows many commands to be passed in one low-level message, thus allowing all thedata XCommand = ... | XDoCommands [XCommands] ...
DrawCommands needed to redraw a window
to be passed in one message from graphicsF to the top level of
the fudget hierarchy. The message passing overhead thus becomes
negligible. Also, caches and other filters (see Chapter 24)
that previously had to examine every DrawCommand now only
examine one XDoCommands message (they do not look
inside). This reduced the above mentioned redrawing time from 1
second to about 0.1 second, which makes a big difference from
the user's point of view.alignP,
which allows you to compose text with base line alignment, andalignP :: Placer
paragraphP,
which does line breaking.paragraphP :: Placer
To implement these, two extensions of the layout system were needed. Although they should still be considered to be in an experimental stage, we describe them below.
We also present the idea of conditional placers and spacers, which could be implemented without any extensions. These can be used, for example, to select between different layouts depending on the size of an object.
alignP, the layout requests (see Chapter 23)
were extended to contain, in addition to the nominal size
and the stretchiness, a list of reference points:
data LayoutRequest
= Layout { minsize :: Size,
fixedh, fixedv :: Bool,
refpoints :: [Point] }Graphic instance for strings (see the function
measureString in Figure 71).
alignP places the argument
boxes so that the last reference point in one box coincides with the
first reference point in the next box. This gives us base line
alignment when composing text.
Unlike most other placers, alignP does not stretch the argument
boxes. In fact, we have not included a mechanism for specifying how
reference points are affected by stretching, so you may get odd
layout if a box containing reference points is first stretched by
one placer and then aligned with another box containing reference
points by alignP.
We have also found use for some spacers that manipulate reference points:
The spacerrefMiddleS, refEdgesS, noRefsS :: Spacer moveRefsS :: Point -> Spacer
refMiddleS replaces the reference points of a
box with two reference points placed on the middle of the left
and right edges. refEdgesS takes the first and last
reference points and moves them horizontally to the left and
right edges, respectively. noRefsS removes the reference
points from a box. moveRefsS displaces the reference
points of a box by a given vector.
The placers and spacers we have presented do not make use of more than two reference points, so it perhaps seems more appropriate to have a pair (instead of a list) of reference points in the layout requests. One can also consider more elaborate use of reference points, for example, different placers might use different sets of reference points. To take a concrete example, when putting equations together horizontally in a comma separated list, you probably want to do base line alignment, but when placing equations in a vertical list, you may want them to appear with the = symbols on the same vertical line. Also, you may want the layout system to choose between horizontal and vertical placement depending on the available space, so the equations must contain reference points for both possibilities, and the placers must be able to choose between them.
To display text with automatic line breaking, we would like the requested height to depend on the actual width. The line breaking should be redone when the width of the window is changed.
In the original fudget layout system, there was no way for a fudget to ask for a size where the requested height depends on the available width. A fudget could still achieve this behaviour: whenever notified of a size change, it could output a new request with the same width as in the notification but with a new height. Care of course had be taken to avoid generating infinite sequences of notifications and requests and other unpleasant effects. This solution was used in an early version of the web browser described in Chapter 32.
As part of the work on support for structured graphics, we
developed a better solution to the line breaking problem. We
extended the layout requests with a function that answers the
question ``if you can be this wide, how tall do you want to
be?''. For symmetry, there is also a function that allows the
requested width to depend on the actual height (otherwise
flipP would not work). The two functions are called wAdj
and hAdj, respectively.
data LayoutRequest
= Layout { minsize :: Size,
fixedh, fixedv :: Bool,
refpoints :: [Point],
wAdj, hAdj :: Int -> Size}wAdj/hAdj functions, the layout
requests still contain the usual nominal size. This saves us
from having to rewrite all placers and spacers. Also, the usual
nominal size is still used rather than the wAdj/
hAdj functions on the top level in normal shell windows, while
the wAdj function is used in vScrollF (see
Section 10.7) , where the width is constrained but the height
can vary freely. (Not surprisingly, hAdj is used in
hScrollF.)
Changing the data type LayoutRequest meant that all
occurrences of the constructor Layout in the Fudget library
had to be adjusted. The functions plainLayout and
refpLayout were introduced to simplify these adjustments:
plainLayout s fh fv = refpLayout s fh fv [] refpLayout s fh fv rps = Layout s fh fv (const s) (const s) rps
The first two allow you to choose between two placers/spacers depending on the size of the resulting box, i.e., if placer1 and placer2 yield boxes of size1 and size2, respectively, thenifSizeP :: (Size->Size->Bool) -> Placer -> Placer -> Placer ifSizeS :: (Size->Size->Bool) -> Spacer -> Spacer -> Spacer stretchCaseS :: ((Bool,Bool)->Spacer) -> Spacer alignFixedS :: Alignment -> Alignment -> Spacer
ifSizeP p placer1 placer2 uses
placer1 if p size1 size2 is True,
and placer2 otherwise. ifSizeS
works analogously for spacers.
stretchCaseS allows you to write
spacers that depend on the horizontal and vertical stretchiness of
the argument box. alignFixedS is an application of
stretchCaseS. It
can be used to allow stretchable graphical objects to be stretched
while objects of fixed size are aligned. As an example, when
buttonF
was generalised from displaying strings to arbitrary graphics, we
switched from unconditionally centering the label with
centerS to
conditionally centering it with alignFixedS aCenter aCenter. This
means that text labels will be centered as before, while graphical
labels may be stretched.
Drawing and the
fudgets graphicsF and hyperGraphicsF. In this
chapter, we will present a set of combinators that can be used
for building syntax-oriented editors. Such editors present a
graphical view of a structured value in an abstract syntax, for
example a program in a programming language. The editors let the
user manipulate the (graphical view of) the program in various
controlled ways.
One problem the programmer must deal with, when developing syntax-oriented editors, is how the values of the abstract syntax should be represented, and how they should be connected to the graphical objects. We will present a solution where the operations on the abstract syntax is defined closely with the corresponding operations on the graphical objects, to avoid inconsistencies between the abstract syntax and its graphical view.
As a concrete example, consider a grammar for a tiny expression language with arithmetic operations on numbers.
Such an abstract syntax is straightforward to represent in Haskell using one datatype for each non-terminal in the grammar, and where each alternative corresponds to a data constructor.
Expr ::= Integer | Expr Op Expr Op ::= + | -| × | /
data Expr = Number Integer
| Operation Expr Op Expr
data Op = Add
| Subtract
| Multiply
| DivideGraphic instances for each type,
which means that they can be used as leaves in the type
Drawing (confer Section 27.4). The drawing can be decorated
with labels containing functions for building the abstract syntax
when needed, and manipulation functions describing how the user
can modify different parts of the abstract syntax. However, all
labels in a Drawing must have the same type, which
presents a complication when we want to use different datatypes
for different non-terminals. In contrast, the combinators in this
chapter allow editors of different type, representing different
non-terminals, to be combined.
The inspiration of the combinators comes from a certain style of
parsing combinators that is part of the functional folklore (the
earliest publication we know of is [Röj95a]). If
P a is the type of parsers which returns a value of type
a, the combinators that are interesting in this context
are
ap :: P (a -> b) -> P a -> P b, which combines two parsers
sequentially. It also acts as lifted function application, in
that the function returned by the first parser is applied to
the value returned by the second, yielding a value that the
combination returns.map :: (a -> b) -> P a -> P b, which applies a function to
the value that a parser returns.ap combinator is left associative (just like function
application), and map has higher precedence than
ap. This allow a concise style when writing parsers. For
example, if pExpr is an expression parser, and pOp
is an operation parser,
parses an expression followed by an operation and another expression, and returns the appropriateOperation `map` pExpr `ap` pOp `ap` pExpr :: P Expr
Expr value
using the Operation constructor.
The next section presents the basic combinators for building editors. Section 28.2 shows how the combinators can be used to build an editor for arithmetic expressions. Section 28.3 discusses how non-local editing operations, like variable renaming, can be handled. The implementation of the combinators is outlined in Section 28.4.
SOM combinatorsSOM i
o h a (Syntax Oriented Manipulation),
which represents a value (or piece of abstract syntax)
of type a, that can be manipulated through input/output of
values of type i and o. The parameter h is
used to pass inherited attributes. The parameter a
can also be used for passing synthesised attributes, if needed.
A SOM expression not only represents a (structured) value,
but also contains information about how different parts of this
value might be manipulated, and how the value should be
graphically displayed.
Figure 72. The
The combinators that operate on
somF :: h -> SOM i o h a -> F (Either i (SOM i o h a))
(Either o a)
leaf :: Graphic g => g -> a -> SOM i o h a
ap :: SOM i o h (a -> b) -> SOM i o h a -> SOM i o h b
map :: (a -> b) -> SOM i o h a -> SOM i o h b
select :: (h -> a -> o)
-> (h -> a -> i -> Maybe (SOM i o h a))
-> SOM i o h a
-> SOM i o h a
attr :: (h -> a -> (h',a')) -> SOM i o h' a
-> SOM i o h a'
SOM combinators.SOM expressions are
shown in Figure 72. The display and manipulation
of SOM expressions are controlled by somF. The
fudget somF h s will initially display the
SOM expression s, given an attribute h to
inherit. This expression can at any time be replaced by sending
a new SOM expression to the fudget. The fudget can also
output the value that the manipulated expression
represents. This happens when a new expression is sent to the
fudget, or when a selected part of it is replaced. The message
types i and o in somF are used for the
manipulation of selected subexpressions.
Primitive SOM expressions are built with the function
leaf. The arguments to leaf are a graphical object
to display, and the value it represents. This combinator is used,
together with ap and map, to compose SOM
expressions in the same style as parsers.
To manipulate a SOM expression, the user must first
select a subexpression. A SOM expression might contain
some nodes that are not possible to manipulate (for example,
syntactic decorations like keywords), and some that are. The
programmer declares that it should be possible to select and
manipulate a node by using the select combinator. The
composition select fo fi
s makes the SOM expression s
selectable. When the user clicks inside the graphical
representation of s, but not inside any inner selectable
node, the composition is selected and highlighted. As a result,
the output function fo is applied to the inherited
attribute and the current value. The result is output from
the fudget somF that contains the composition, and is
typically a set of editing operations that are applicable to
the selected node. Initially, the current value is merely the
value that s represents, but this might change if some
part of s is replaced. If some input (typically an
editing operation picked by the user) is sent to the fudget
while s is selected, the input function fi
is applied to the inherited attribute, the current value and
the input, yielding a new expression which replaces
select fo fi s. The input
function also has a choice of returning Nothing, in case
the input could not be handled. This is used to delegate input
to selectable ancestors, and is covered in
Section 28.3.
The combinator attr allows the inherited attribute and
the current value to be modified simultaneously. In the
composition f `attr` s, f is
applied to the inherited attribute and the current value that
s represents. The result of f is the attribute
that s will inherit, and the current value of the
composition.
leaf, ap and map, we can turn
structured values into SOM expressions. As an example, let
us consider the expression language from the introduction. We
will define the functions edExpr and edOp that
turn arithmetic expressions and operators into SOM
expressions. Since we do not need any inherited attributes for the
moment, and the type of input and output will always be the same,
we define a type synonym for the kind of SOM expressions that we
will form.The expression editortype ArithSOM a = SOM Choice [Choice] () a edExpr :: Expr -> ArithSOM Expr edOp :: Op -> ArithSOM Op
edExpr is used in exprF
to form the fudget that presents the editor.
exprF :: Expr -> F (Either Choice (ArithSOM Expr))
(Either [Choice] Expr)
exprF e = somF () (edExpr e)exprF outputs a
list of choices that is presented in a menu. These choices
represent the operations that are available on the
subexpression. If a choice is picked, it will be sent back to
the editor. exprF also outputs the arithmetic
expression for evaluation in the main fudget. A screen dump
of the program is shown in Figure 73.
Figure 73. An arithmetic expression manipulator. The user has selected the subexpression
2 × 3, which can be replaced by5,7, or0 + 0.
main = fudlogue $
loopF (shellF "Choose" (smallPickListF show >+<
(displayF >=^< (show . evalExpr))) >==<
shellF "Expression" (scrollF (exprF (Number 0)))
)
evalExpr :: Expr -> Integer
evalExpr (Number i) = i
evalExpr (Operation e1 b e2) = evalOp b (evalExpr e1)
(evalExpr e2)When we defineevalOp :: Op -> (Integer -> Integer -> Integer) evalOp Add = (+) evalOp Subtract = (-) evalOp Multiply = (*) evalOp Divide = \x y -> if y == 0 then 0 else x `div` y
edExpr and edOp, we use a
programming style which resembles the one we presented for
parsing combinators in the introduction:
edExpr e = selExpr $ case e of
Number i -> Number `map`
leaf i i
Operation e1 b e2 -> Operation `map`
edExpr e1 `ap`
edOp b `ap`
edExpr e2edOp. Each
subexpression can be selected and manipulated by
selExpr, which is defined later.
The definition of edOp is similar.
edOp b = selOp $ leaf (showOp b) b
We define the typeshowOp Add = "+" showOp Subtract = "-" showOp Multiply = "×" showOp Divide = "/"
Choice to contain expressions that
can replace the selected subexpression. Since subexpressions
can be of both type Expr and Op, we use a union
type for the output.
data Choice = ReplaceExpr Expr
| ReplaceOp Op0 + 0. The interface is not at all the most
convenient one could imagine, but it allows a patient user to
enter an arbitrary expression (the + can be replaced
with any of the other operators, as we will see below). This
part of the editor could of course be elaborated as desired.
selExpr :: ArithSOM Expr -> ArithSOM Expr
selExpr = select outf inf
where
outf _ e = map ReplaceExpr
[Number (evalExpr e-1),
Number (evalExpr e+1),
Operation (Number 0) Add (Number 0)]
inf _ _ = map edExpr . stripExprIf the user picks one of the choices, it will be propagated to the selected node, the expression is extracted from the type union, and a replacementstripExpr (ReplaceExpr e) = Just e stripExpr _ = Nothing
SOM expression is
formed. However, the type system cannot prevent programming
errors that result in an operator being sent to
selExpr. To get a more robust program, the function
stripExpr ignores the input in this case and returns
Nothing.
When an operator is selected, we present a choice of the four arithmetic operators.
selOp :: ArithSOM Op -> ArithSOM Op
selOp = select outf inf
where
outf _ _ = map ReplaceOp [Add,Subtract,Multiply,Divide]
inf _ _ = map edOp . stripOpstripOp (ReplaceOp b) = Just b stripOp _ = Nothing
SOM
subexpression, and arbitrary replacements can be specified for
that expression. If a manipulation would imply a change in
other parts of the expression, we are forced to replace the
complete expression globally, by sending a new SOM
expression to somF. There are situations where we want
the possibility to specify replacements that are somewhere in
between the local and global alternatives. Suppose that we want
to add variables to our arithmetic expressions. We would then
like to provide an operation for changing the name of a
variable, by selecting one occurrence (possibly the binding
occurrence), and give a new name to it. This is an operation
that affects the whole subtree that starts with the binding of
the variable.
This effect can be achieved by using the possibility to
delegate input as follows. Recall that the input function (the
second parameter of select) can return Nothing
for input that cannot be handled. Instead of discarding the
input, somF will delegate it to the closest selectable
ancestor, and apply its input function. This delegation
propagates towards the root of the SOM expression, until
a select node is found that accepts the input.
In the case of variable manipulation, delegation can be used to propagate input to the node where the variable is bound. We will do this in the following section, where we present a variant of the expression manipulator in Section 28.2, extended with variables.
Expr with constructors for
variables and let expressions.
data Expr =
...
| Var Name
| Let Name Expr Expr
type Name = StringSOM expression, we assume
the presence of an environment where we can lookup the
value of variables.We will use the inherited attribute for propagating the environment. The type of SOM expressions we will use are instances oftype Env = [(Name,Integer)]
ArithEnvSOM.We introduce the additional combinatorstype ArithEnvSOM a = SOM Choice [Choice] Env a
drLeft or
drRight to prepend or append a graphical decoration to
an expression.These are used for drawing keywords, as we will see in the case of let expressions.drLeft :: Graphic g => g -> SOM i o h a -> SOM i o h a drRight :: Graphic g => SOM i o h a -> g -> SOM i o h a
The associativity of ap, drLeft and
drRight are set so that we avoid parentheses, at least in
this application.
Haskell does not declare any fixity forinfixl 3 `ap` infixr 8 `drLeft` infixl 8 `drRight`
map, which
means that it gets a default declaration.But the type ofinfixl 9 `map`
map suggests that it should be
right associative. If it were, and had the same precedence
level as drLeft, we could skip the parentheses in
expressions like f `map` (d `drLeft`
s). If local fixity declarations were allowed in
Haskell, we could fix the fixity.Local fixity declarations are not allowed in Haskell, so we giveedExpr e = let infixr 8 `map` in ...
map a new name with the desired fixity.infixr 8 `mapp`
Withmapp :: (a -> b) -> SOM i o h a -> SOM i o h b mapp = map
mapp, we can construct SOM expressions in
the style shown in in Figure 74. The function
edExpr :: Expr -> ArithEnvSOM Expr edExpr e = case e of Number i -> selExpr $ Number `mapp` leaf i i Operation e1 b e2 -> selExpr $ Operation `mapp` edExpr e1 `ap` edOp b `ap` edExpr e2 Var n -> selVar n $ Var `mapp` leaf n n Let n e1 e2 -> selLet $ extendEnv `attr` Let `mapp` "let" `drLeft` edName n `ap` "=" `drLeft` (dropEnv `attr` edExpr e1) `ap` "in" `drLeft` edExpr e2 extendEnv :: Env -> Expr -> (Env,Expr) extendEnv = \env e@(Let n e1 _) -> ((n,evalExpr env e1):env,e) dropEnv :: Env -> Expr -> (Env,Expr) dropEnv = \env e -> (tail env,e)Figure 74. The function
edExprextended for variables.
extendEnv will be applied to the
current let expression, from which it will extract
sufficient information to extend the environment that the
body should inherit. To avoid that the right-hand side in
the let expression also inherits the extended environment,
we use the function dropEnv to pop the added
binding. (If we want to allow recursive declarations, we
omit dropEnv.)
Note that we have also used different selection functions for
different kinds of expressions. Variables are handled by
selVar, let expressions by selLet, and the
others by selExpr.
The binding occurrence of a variable is handled by Figure 75. The editor for variable names.
edName (Figure 75), and selecting such a name
results in a choice of renaming it. For simplicity, we pick
an arbitrary new name that is not present in the
environment by using freshVar.
The input function in
edName :: Name -> ArithEnvSOM Name
edName n = selName $ leaf n n
selName :: ArithEnvSOM Name -> ArithEnvSOM Name
selName = select outf inf
where outf env n = [renameCommand n env]
inf _ _ _ = Nothing
renameCommand :: Name -> Env -> Choice
renameCommand old env = Rename old (freshVar env)
freshVar :: Env -> Name
freshVar env = head (map (:[]) ['a'..] \\ map fst env)selName ignores all input,
which instead is delegated to selLet.
We have extended the manipulation type with a command for renaming a variable.
data Choice = ... | Rename Name Name
The selection functions are defined in
Figure 76. Figure 76. The selection functions for expressions.
The functions for let expressions and variables
are variants of the original
selExpr :: ArithEnvSOM Expr -> ArithEnvSOM Expr
selExpr = selExpr' (const []) exprInf
selLet :: ArithEnvSOM Expr -> ArithEnvSOM Expr
selLet = selExpr' (const []) letinf
where letinf env (Let n e1 e2) (Rename n' new) | n == n'
= Just (edExpr (Let new (rename n new e1)
(rename n new e2)))
letinf env e i = exprInf env e i
selVar :: Name -> ArithEnvSOM Expr -> ArithEnvSOM Expr
selVar n = selExpr' (\env -> [renameCommand n env]) exprInf
selExpr' :: (Env -> [Choice])
-> (Env -> Expr -> Choice
-> Maybe (ArithEnvSOM Expr))
-> ArithEnvSOM Expr
-> ArithEnvSOM Expr
selExpr' xchoices inf = select outf inf
where outf env e = xchoices env ++
map ReplaceExpr
([ Number (v+1)
, Number (v-1)
, Operation n0 Add n0
, Let (freshVar env) n0 n0 ]
++ map (Var . fst) env
)
where v = evalExpr env e
n0 = Number 0
exprInf :: Env -> Expr -> Choice -> Maybe (ArithEnvSOM Expr)
exprInf env _ = map edExpr . stripExpr
selExpr from
Section 28.2. We define a parameterised version (
selExpr'), which lets us add choices and specify the input
function. Note that we have added choices for all variables
in scope.
The standard selection function (selExpr) does not
have any additional choices, whereas the selection function
for let expressions (selLet) defines an extended
input function which handles the renaming command. For a
renaming command to match, the old variable must equal the
bound variable. Otherwise, input is meant for some outer
let expression. We assume a function rename, where
rename old new e substitutes
new for old in e.
When selecting a variable, we extend the expression
selection menu with a renaming choice. Variable renaming
can then take place at any occurrence of a variable. Note
that we do not handle renaming in the input function, it is
the same as in selExpr.
The rest of the program is almost the same as in the first
example, except that we pass the empty environment as an
initial inherited attribute in exprF. The program is
seen in action in Figure 77.
exprF :: Expr -> F (Either Choice (ArithEnvSOM Expr))
(Either [Choice] Expr)
exprF e = somF emptyEnv (edExpr e)
emptyEnv :: Env
emptyEnv = []
Figure 77. Manipulating variables. There are additional choices for the variables in the environment. Since a variable is selected, there is also a choice of renaming it.
SOM combinatorsSOM as a
datatype with constructors corresponding to the combinators
leaf, select, map and ap. Since
the types of the arguments to map and ap have
variables that do not show up in the result type, we use the
possibility to specify local existential quantification using
variables beginning with ? in the datatype
declaration. Again, existential quantification in datatypes
proves to be a useful extension to Haskell (see also
Section 27.4.2).
data SOM i o h a =
Select (h -> a -> o)
(h -> a -> i -> Maybe (SOM i o h a))
(SOM i o h a)
| Map (?b -> a) (SOM i o h ?b)
| Ap (SOM i o h (?b -> a)) (SOM i o h ?b)
| Attr (h -> ?a -> (?h,a)) (SOM i o ?h ?a)
| Leaf Dr a
| Decor (Dr -> Dr) (SOM i o h a)The first argument to theselect = Select ap = Ap attr = Attr instance Functor (SOM i o h) where map = Map
Leaf constructor is a
drawing:The label typetype Dr = Drawing SOMPointer Gfx
SOMPointer, which is defined later, is
used to identify what part of a SOM expression the
user has selected. The type Gfx is used to store
arbitrary graphical objects in the leaves (Section 27.4.2). In the definition of leaf,
we turn these graphics into drawings by means of g
(which was defined in Section 27.4.2).The final constructor inleaf :: Graphic g => g -> a -> SOM i o h a leaf d a = Leaf (g d) a
SOM is Decor, and can
be used to define layout or add additional graphics on a part
of a SOM expression. Its first argument is a function
which will be applied to a drawing that is constructed from its
second argument. The combinators drLeft and
drRight uses this constructor:The fudgetdrLeft d n = Decor (\d' -> hboxD [g d,d']) n drRight n d = Decor (\d' -> hboxD [d',g d]) n
somF is built around a
hyperGraphicsF, which outputs a SelectionPtr whenever
the user selects a subexpression.Adata Dir = Le | Ri type SelectionPtr = [Dir]
SelectionPtr is a list of turns to take whenever an
Ap node is encountered in the SOM tree, and
points out a select node. Using the function
somOutput in Figure 78, somF can get the
output choices of a selected node. If
somOutput :: h -> SOM i o h a -> SelectionPtr -> o somOutput h n p = case n of Select outf _ n -> case p of [] -> outf h (somValue h n) _ -> somOutput h n p Ap f n -> case p of Le:p -> somOutput h f p Ri:p -> somOutput h n p Map _ n -> somOutput h n p Attr f n -> somOutput (fst (apAttr f h n)) n p Decor _ n -> somOutput h n pFigure 78. The function
somOutput.
somF receives an input choice for the selected
node, the function somInput (Figure 79) is
applied to the input and the selection pointer, to
get the modified SOM tree.
somInput :: h -> SOM i o h a -> i -> SelectionPtr -> Maybe (SelectionPtr,SOM i o h a) somInput h n i p = case n of Select o inf n -> case p of [] -> myInput _ -> mapSOM (Select o inf) (somInput h n i p) ++ myInput where myInput = map (\n->([],n)) (inf h (somValue h n) i) Ap f n -> case p of [] -> Nothing Le:p -> map (mapPair ((Le:),(`ap` n))) (somInput h f i p) Ri:p -> map (mapPair ((Ri:),(f `ap`))) (somInput h n i p) Map f n -> mapSOM (Map f) (somInput h n i p) Attr f n -> mapSOM (Attr f) (somInput (fst (apAttr f h n)) n i p) Leaf dr a -> Nothing Decor f n -> mapSOM (Decor f) (somInput h n i p) where mapSOM = map . apSnd mapPair f g (x,y) = (f x,g y)Figure 79. The function
somInput.
somInput also returns the pointer to the node whose
input function accepted the input, which is used by
somF to update the correct part of the drawing. If all input
functions ignore the input, somInput returns
Nothing.
The functions Figure 80. The functions somOutput and somInput use the
function somValue, to get the current value of a
SOM expression, and the function apAttr, to apply
attribute functions (Figure 80).
The recursive definition in
somValue :: h -> SOM i o h a -> a
somValue h n = case n of
Select _ _ n -> somValue h n
Ap n1 n2 -> (somValue h n1) (somValue h n2)
Map f n -> f (somValue h n)
Leaf _ a -> a
Attr f n -> snd (apAttr f h n)
Decor _ n -> somValue h n
apAttr :: (h -> a -> (h',a'))
-> h
-> SOM i o h' a
-> (h',a')
apAttr f h n = h'a' where h'a' = f h (somValue (fst h'a') n)somValue and
apAttr.apAttr mirrors the fact
that attributes and values can have cyclic dependencies.
The implementation of somF is shown in Figure 81,
and as mentioned previously, it is built around
hyperGraphicsF. The auxiliary functions tohg,
out, updateDr, and replaceDr are routing
functions that are typical when programming with
loopThroughRightF. The function out is used when
outputting messages from somF, and updateDr and
replaceDr are used when updating part of or the whole
of the drawing in the hyperGraphicsF. (Compare with
the type of hyperGraphicsF in Section 27.4.)
The controlling stream processor ctrl has an internal
state which consists of the SOM expression being
edited (n), and a pointer to the selected node (
p). If there is no selected node, p is
Nothing. An incoming message to ctrl is either a
click from the hyperGraphicsF, indicating a new
selection by the user (handled by click), an input
choice (handled by input) or a new SOM
expression (handled by replace).
In click, the
old selection cursor is removed, and a new node is
selected.
In Figure 81. The function input, it is checked that there is a
selection, and that a replacement node can be obtained from
somInput. In this case, the appropriate subdrawing is
replaced, and selected.
somF :: h -> SOM i o h a -> F (Either i (SOM i o h a))
(Either o a)
somF h n = loopThroughRightF
(absF (ctrl n Nothing))
(hyperGraphicsF (unselectedSomDr n))
where
tohg = putSP . Left
out = putSP . Right
updateDr = tohg . Left . unselectedSomDr
replaceDr = tohg . Right
unselectedSomDr = somDrawing []
ctrl n p = getSP $ click `either` (input `either` replace)
where
same = ctrl n p
click p' = maybe id (deselect n) p $
selectO n p' $
ctrl n (Just p')
input i = flip (maybe same) p $ \jp ->
flip (maybe same) (somInput h n i jp) $ \(rp,n') ->
replaceDr (rp,somDrawing rp n') $
selectO n' jp $
out (Right (somValue h n')) $
ctrl n' p
replace n' = updateDr n' $
ctrl n' Nothing
-- Select subnode and send its output.
selectO n p = select n p . out (Left (somOutput h n p))
-- Draw cursor
select = setselect cursor
-- Remove cursor
deselect = setselect id
setselect cu n p = replaceDr (p,cu (somDrawing p n))
-- The cursor is a frame around the node
cursor d = placedD overlayP (boxD [d,(g (frame' 1))])
-- Extract selected subdrawing
somDrawing :: SelectionPtr -> SOM i o h a -> DrsomF.
To promote quick development of prototype programs, a programmer might prefer to concentrate on the functionality, and ignore the GUI design (at least to start with). Since this method can make life easier for the programmer, and to put it in contrast with HCI, we call it PCI (Programmer Computer Interaction) oriented.
With the PCI method, the GUI must be generated automatically
somehow. The basic idea is simple, and can be seen as the GUI
variant of the Read and Show classes in Haskell,
which allow values of any type to be converted to and from
strings, using the functions read and show:
Part of the convenience with these classes is that instances can be derived automatically by the compiler for newly defined datatypes. By usingread :: Read a => String -> a show :: Show a => a -> String
read and show, it is easy to
store data on files, or exchange it over a network (as is done in
Chapter 26).
In this section, we will define the class FormElement,
which plays a similar role to Read and Show, but for
GUIs. Form elements are combined into forms, which can be
regarded as simple graphical editors that allow a fixed number of
values to be edited. They are often used in dialog windows to
modify various parameters in a GUI application.
Assuming that all the necessary instances of FormElement
are available, we show how forms can be generated automatically,
entirely based on the type of the value that the form should
present.
FormElement classA candidate type for form elements for a type a is a fudget with the type a both on input and output.
The form element class has a method which specifies such a fudget.type FormF t = F t t
We have used the standard trick of adding a special methodclass FormElement t where form :: FormF t formList :: FormF [t] instance (FormElement t) => FormElement [t] where form = formList
formList which handles lists, so that we can get an
instance for strings (this is discussed in
Section 40.2).
We can now define instances for the basic types integers, booleans, and strings.
We also need instances for structured types. The fundamental structured types are product and sum.instance FormElement Int where form = intInputF instance FormElement Bool where form = toggleButtonF " " instance FormElement Char where formList = stringInputF
instance (FormElement t,
FormElement u) =>
FormElement (Either t u)
where form = vBoxF (form >+< form)
instance (FormElement t,
FormElement u) =>
FormElement (t,u)
where form = hBoxF (form >·< form) The combinator >·< puts two fudgets in parallel, just like
>+< and >*<, but input and output are pairs.
(>·<) :: F a1 b1 -> F a2 b2 -> F (a1, a2) (b1, b2)
f >·< g = pairSP >^^=< (f >+< g) >=^^< splitSP
pairSP :: SP (Either a b) (a,b)
pairSP = merge Nothing Nothing where
merge ma mb =
(case (ma,mb) of
(Just a,Just b) -> put (a,b)
_ -> id) $
get $ \y -> case y of
Left a -> merge (Just a) mb
Right b -> merge ma (Just b)f >·< g is split, the first
component is fed into f, and the second component is fed
into g. The combined fudget will not output anything
until both f and g has output something. After
this has occurred, a message from one of the subfudgets f
or g is paired with the last message from the other
subfudget and emitted.
We are ready for a small example. The figure shows a form which can handle input which either is an integer, or a pair of a string and a boolean.
An extended example connects the input and output of the form with fudgets to demonstrate the message traffic:myForm :: FormF (Either Int (String,Bool)) myForm = border (labLeftOfF "Form" form)
main = fudlogue $
shellF "Form" $
labLeftOfF "Output" (displayF >=^< show)
>==< myForm
>==< labLeftOfF "Input" (read >^=< stringInputF)
Figure 82. First, the user has entered the string "Hello" and activated the toggle button. Then, the user entered a number in the integer form element. The last picture is a simulation of how the form can be controlled by the program, in this case by entering a value in the Input field. The value sets the form and is propagated to the output.
Either. It would be
desirable to highlight the part that is valid (or to dim the other
part).
This generation can also be performed for user defined datatypes by using polytypic programming [JJ97], based on the instances for products and sums. Polytypic programming allows us to define how instances should be derived, based on the structure of the user-defined datatype. For more complicated (for example recursive) types, it might be a better idea to base the form elements on the fudgets for structured graphics in Chapter 27.
After the functionality is there, the programmer's attention might
turn to the look of the forms, and we need a way to tune
them. An approach that immediately comes to mind is to add an
extra attribute parameter to the form method.
class FormElement a t where
form :: a -> FormF tFormElement a t, we
can construct a form for a type t, given an attribute value
of type a. A problem with this approach is that currently,
only one parameter may be specified in a class declaration in
Haskell. Multi-parameter classes are allowed in Mark Jones' Gofer
[Jon91], which also allows instance declarations for
compound types like String. With these features, we could
define instances as follows.
instance (FormElement a t,
FormElement b u) => FormElement (a,b) (Either t u)
where form (a,b) = vBoxF (form a >+< form b)
instance (FormElement a t,
FormElement b u) => FormElement (a,b) (t,u)
where form (a,b) = hBoxF (form a >·< form b)
instance Graphic a => FormElement a String
where form a = labLeftOfF a $ stripInputSP >^^=< stringF
instance Graphic a => FormElement a Int
where form a = labLeftOfF a $ stripInputSP >^^=< intF
instance Graphic a => FormElement a Bool
where form a = toggleButtonF a There are many aspects of GUI fudgets that one might want to
modify, e.g. the font or the foreground or background colours for
displayF. The simple GUI fudgets have some hopefully
reasonable default values for these aspects, but sooner or later,
we will want to change them.
In early versions of the Fudget library, the GUI fudgets had
several extra parameters to make them general and adaptable to different
needs. For example, the type of displayF was something
like:
Having to specify all these extra parameters all the time made it hard to write even the simplest program: when creating a program from scratch, it was next to impossible to write even a single line of code without consulting the manual. When we wrote programs on overhead slides or on the blackboard, we always left out the extra parameters, to make the code more readable.displayF :: FontName -> ColorName -> ColorName -> F String a
A simple way to improve on this situation would be to introduce two versions of each GUI fudget: one standard version, without the extra parameters, and one customisable version, with a lot of extra parameters:
This would make it easy to use the standard version, and the blackboard examples would be valid programs. But the customisable version (displayF :: F String a displayF' :: FontName -> ColorName -> ColorName -> F String a displayF = displayF' defaultFont defaultBgColor defaultFgColor
displayF') would still be hard to use: even if you
just wanted to change one parameter, you would have to specify all
of them and you would have to remember the order of the
parameters. So, we went a step further.
First, we wanted be able to change one parameter without having to
explicitly give values for all the other ones. A simple way of
doing this would be to have a data type with constructors for each
parameter that has a default value. In the case of
displayF, it might be
data DisplayFParams = Font FontName
| ForegroundColor ColorName
| BackgroundColor ColorNameWe no longer have to remember the order of the parameter, and, whenever we are happy with the default values, we just leave out that parameter from the list, and all is fine.displayF' :: [DisplayFParams] -> F String a
However, suppose we want to do the same trick with the button fudget. We want to be able to customise font and colours for foreground and background, like the display fudget, and in addition we want to specify a ``hot-key'' that could be used instead of clicking the button:displayF = displayF' []
data ButtonFParams = Font FontName
| ForegroundColor ColorName
| BackgroundColor ColorName
| HotKey (ModState,Key)ButtonFFont, ButtonFForegroundColor etc.), which
is just as tedious.
Let us return to the display fudget example, and show how to make it customisable. First, we define classes for the customisable parameters:
Then, we define a new type for the parameter list oftype Customiser a = a -> a class HasFont a where setFont :: FontName -> Customiser a class HasForegroundColor a where setForegroundColor :: ColorName -> Customiser a class HasBackgroundColor a where setBackgroundColor :: ColorName -> Customiser a
displayF:and add the instance declarationsnewtype DisplayF = Pars [DisplayFParams]
The type ofinstance HasFont DisplayF where setFont p (Pars ps) = Pars (Font p:ps) instance HasForegroundColor DisplayF where setForegroundColor p (Pars ps) = Pars (ForegroundColor p:ps) instance HasBackgroundColor DisplayF where setBackgroundColor p (Pars ps) = Pars (BackgroundColor p:ps)
displayF will beWe put these declarations inside the module definingdisplayF :: Customiser DisplayF -> F String a
displayF, making DisplayF abstract. When we later use
displayF, the only thing we need to know about
DisplayF is its instances, which tell us that we can set font
and colours. For example:
myDisplayF = displayF (setFont "fixed" .
setBackgroundColor "green")buttonF customisable in the same way, we define
the additional class:The button module definesclass HasKeyEquiv a where setKeyEquiv :: (ModState,Key) -> Customiser a
and makes it abstract, as well as defining instances for font, colours and hot-keys. Note that the instance declarations for font and colours will look exactly the same as for the display parameters! (We can reuse the constructor namenewtype ButtonF = Pars [ButtonFParams]
Pars as long as we define only one customisable
fudget in each module.) In the Fudget library
implementation, we have used cpp macros to simplify the
implementation of customisable fudgets and avoid code
duplication.
We can now customise both the display fudget and the button fudget, if we want:
myFudget = displayF setMyFont >+< buttonF (setMyFont.setMyKey) "Quit"
where setMyFont = setFont "fixed"
setMyKey = setKeyEquiv ([Meta],"q")standard, which does not modify anything:standard :: Customiser a standard p = p standardDisplayF = displayF standard
standard. We use short and natural names for the standard
versions of GUI fudgets, without customisation argument. So we
haveand so on. This way, a programmer can start using the toolkit without having to worry about the customisation concept. Later, when the need for customisation arises, just add an apostrophe and the parameter. One could also have the reverse convention and use apostrophes on the standard versions, something that sounds attractive since apostrophes usually stand for omitted things (in this case the customiser). But then a programmer must learn which fudgets are customisable (and thus need an apostrophe), even if she is not interested in customisation.buttonF :: String -> F Click Click buttonF = buttonF' standard buttonF' :: Customiser ButtonF -> String -> F Click Click buttonF' = ... displayF :: F String a displayF = displayF' standard displayF' :: Customiser DisplayF -> F String a displayF' = ...
As an example, the button and the display fudgets can be dynamically customised:type CF p a b = F (Either (Customiser p) a) b
buttonF'' :: Customiser ButtonF->String->CF ButtonF Click Click displayF'' :: Customiser DisplayF -> CF DisplayF String a
setFont
function.In the X Windows system, customisation is done via a resource database, where the application can lookup values of various parameters. The database is untyped, that is, all values are strings, so no static type checking can be performed. With our customiser solution, parameters are type checked. In addition, the compiler can check that the parameters you specify are supported by the fudget in question, whereas parameters stored in the resource database are silently ignored if the are not supported.
Disadvantages with this method, as compared to such languages, are that
buttonF and buttonF')
We used lists of parameters in the implementation of customisers:
An alternative would be to use record types instead:newtype DisplayF = Pars [DisplayFParams] data DisplayFParams = ...
data DisplayF = Pars { font::FontName,
foregroundColor, backgroundColor :: ColorName }
instance HasFont DisplayF where setFont f p = p { font=f }
...The Gofer implementation of the process scheduler is implemented in C as part of Gofer's runtime system. A feature of the scheduler is that it attempts to keep the message queues short by giving higher priority to processes that read from channels with many waiting messages.
A limitation in the Gofer implementation of Gadgets resulted in that for each channel, at most one process can be waiting for arriving messages, and channels must be explicitly claimed by a process before trying to read from them.
The functional scheduler that we will describe is not as advanced as the original one, but it is simpler and does not have the above mentioned limitation. Before describing the functional scheduler, we give an overview of the process primitives as they appear in the original Gofer version.
Process s
represents processes which have an internal state of type
s. Communication between processes is asynchronous, and
mediated by typed wires.The communication along wires is directed, one end is input only (type Wire a = (In a,Out a) data In a = In Int data Out a = Out Int
In a), the other is output only (
Out a). If a process only knows the input (output) end
of a wire, it can only read from (write to) it. Note that the
wire ends are merely represented by integer identifiers,
although the types carry extra information about the message
type.
Wires are created by the primitive primWire.
(Just as with stream processors, the sequential behaviour of a process is programmed in a continuation passing style). To transmit something along a wire, one usesprimWire :: (Wire a -> Process s) -> Process s
primTx.A process can wait for input from many wires simultaneously, by using guarded processes. A guarded process (which we denoteprimTx :: Out o -> o -> Process s -> Process s
AGuarded s) is a process continuation that is
waiting for input from one wire, and is formed by
primFrom.Given a list of guarded processes, we can wait for input to any of them byprimFrom :: In m -> (m -> Process s) -> AGuarded s
primRx.Now, why are there two primitives for receiving input, when there is only one for transmitting output? The reason is that although we could combinetype Guarded s = [AGuarded s] primRx :: Guarded s -> Process s
primFrom and primRx,the combination forces us to wait for messages of the same type. The introduction of guarded processes hides the message types and allows a process to select input from wires of different type.-- not general enough! primRxFrom :: [(In m, (m -> Process s))] -> Process s -> Process s primRxFrom = primRx . map (uncurry primFrom)
Processes need not live forever, they can die by calling
primTerminate.
Last but not least, a process can spawn a new process.primTerminate :: Process s
Thus,primSpawn :: Process s' -> s' -> Process s -> Process s
primSpawn p s0 c will
spawn the new process p, giving it initial state
s0, and continue with c.
Gadget Gofer also uses primitives for claiming and disowning wires, and requires that a wire should be claimed by a process before attempting to receive from it. Since the functional scheduler does not have this restriction, we ignore them in the following. The presentation will also ignore
primRx actually takes an additional debugging
argument, and
nci and nco, which are not connected to anything.The mouse and keyboard can be configured by transmitting mouse or keyboard commands, respectively, whereas the screen commands are used for drawing. The events report key presses, mouse clicks, mouse movements, and exposure events.keyboard :: In KeyboardCmnd -> Out KeyboardEvnt -> Process s mouse :: In MouseCmnd -> Out MouseEvnt -> Process s screen :: In [ScreenCmnd] -> Out ScreenEvnt -> Process s
These three primitives are started once inside the Gadget window system. For example, the keyboard process is started with
After this, the keyboard events are read fromwire $ \smk -> wire $ \ksm -> spawn (keyboard (ip smk) (op ksm))
op smk,
and the keyboard is configured by writing to ip ksm.
To execute a process with a given initial state, Gadget Gofer
provides the primitive primLaunch.
primLaunch :: Process s -> s -> IO ()
readState and
setState.In Gadget Gofer, the typereadState :: (s -> Process s) -> Process s setState :: s -> Process s -> Process s
Process s is a synonym for a
function from s to s, that is, a state transformer.The implementation oftype Process s = s -> s
readState and showState is
then straightforward.readState c = \s -> c s s setState s c = \_ -> c s
In the functional version, processes cannot have the simple
function type s -> s any more, since we
must be explicit about the effects that processes can
have. Instead, we will define the process type in steps, where
we start with a stream-processor type that handles messages
related to the keyboard, mouse and screen. On top of the
stream-processor type, we define a state monad (SPms)
with operations for manipulating a state in addition to the I/O
operations of the stream processor. The state is used by the
scheduler, and is used to define a simple process type
Process0, which amounts to the Gadget processes except that
they do not have any local state. Having done this, we define
the full Gadget processes on top. The steps are summarised in
the following table.
ProcessGadget processes with state Process0Processes without state SPmsStream-processor state monads SPPlain stream processors
SPms:A computation of typetype SPms i o s a = (a -> (s -> SP i o)) -> (s -> SP i o)
SPms i o s
a can input messages of type i, output messages
of type o, manipulate a state of type s, and
return a value of type a through the following
operations:getSPms :: SPms i o s i putSPms :: o -> SPms i o s () loadSPms :: SPms i o s s storeSPms :: s -> SPms i o s () getSPms = \k s -> getSP $ \i -> k i s putSPms o = \k s -> putSP o $ k () s loadSPms = \k s -> k s s storeSPms s = \k _ -> k () s
Process0. The state of the
stream processor is used by the scheduler for bookkeeping.
type Process0 i o = SPms i o (SchedulerState i o) ()
data SchedulerState i o = SS{ freeWire :: Wno
, messageQs :: MessageQueues
, ready :: [Process0 i o]
, guarded :: [Guarded0 i o]
, input :: [i -> Process0 i o]
}Wno).What follows are definitions of the primitives for creating wires and processes, and communication over wires. We suffix the primitives with anewtype Wno = Wno Int newtype In a = In Wno newtype Out a = Out Wno
0 to indicate that they operate
on processes without local state.
A new wire is allocated with primWire0, which increments
the field freeWire in the state, and hands a fresh wire
to the continuation.
primWire0 :: (Wire a -> Process0 i o) -> Process0 i o
primWire0 c =
do ps@(SS{ freeWire = w@(Wno i) }) <- loadSPms
storeSPms ps{ freeWire = Wno (i+1) }
c (In w, Out w)
messageQs)
is a mapping from wire numbers to queues of not yet delivered
messages.The typestype MessageQueues = IntMap (Queue Msg)
IntMap and Queue implement integer
maps and Okasaki's queues [Oka95] come from HBC's
library, and have the following signatures:module Queue where empty :: Queue a snoc :: a -> Queue a -> Queue a tail :: Queue a -> Queue a head :: Queue a -> a null :: Queue a -> Bool
The operations are standard, exceptmodule IntMap where empty :: IntMap a modify :: (a -> a) -> a -> Int -> IntMap a -> IntMap a delete :: Int -> IntMap a -> IntMap a lookup :: Int -> IntMap a -> Maybe a
modify, which
deserves an explanation. The expression modify f
a i m applies the function f
to the entry i in m if it exists. Otherwise, it
inserts the value a at i.
Each message is paired with the wire number. Since different wires can have different type, messages can also be of different type. We use an existential type (an extension to Haskell provided by HBC) to hide the message type when putting messages in the queue.
Constructing values of typedata Msg = Msg ?a
Msg is easy, but when
de-constructing them, we cannot assume anything about the type of
the argument. We return to this problem later.
Sending a value on a wire amounts to queueing the wire number together with the value.
primTx0 :: Out a -> a -> Process0 i o -> Process0 i o
primTx0 (Out wno) msg p =
if wno == ncWno then p
else
do ps@(SS{ messageQs, ready }) <- loadSPms
storeSPms ps{ messageQs = addMsg wno (Msg msg) messageQs
, ready = p:ready}
scheduler
addMsg :: Wno -> Msg -> MessageQueues -> MessageQueues
addMsg wno m = modify (snoc m) (snoc m Queue.empty) wnoready holds a list of processes that are ready
to run. When spawning off a new process, we put it on the ready
list.
primSpawn0 :: Process0 i o -> Process0 i o -> Process0 i o
primSpawn0 p' p =
do ps@(SS{ ready }) <- loadSPms
storeSPms ps{ ready = p':ready }
p
guarded. The elements are lists of stateless
guarded processes (AGuarded0 i o).A guarded process is a wire number and a function which takes a message as a parameter. The actual type of the message is hidden indata AGuarded0 i o = AGuarded0 Wno (?a -> Process0 i o)
AGuarded0, so that we can form a list of guarded
processes regardless of what message type they are waiting
for.A guarded stateless process is formed withtype Guarded0 i o = [AGuarded0 i o]
primFrom0.The functionprimFrom0 :: In m -> (m -> Process0 i o) -> AGuarded0 i o primFrom0 (In wno) f = AGuarded0 wno f
primRx0 will wait for a message to arrive to
any of the guarded processes in the first parameter. It adds the
guarded processes to the state, and then jump to the
scheduler to find another process to execute.
primRx0 :: Guarded0 i o -> Process0 i o -> Process0 i o
primRx0 g def =
do ps@(SS{ guarded }) <- loadSPms
storeSPms ps{ guarded = g:guarded }
scheduler
scheduler :: Process0 i o scheduler = do ps@(SS{ freeWire, messageQs, ready, guarded, input }) <- loadSPms let (messageQs',guarded',moreReady) = match messageQs guarded let run p ready' input' = do storeSPms ps{ messageQs = messageQs' , ready = ready' , guarded = guarded' , input = input' } p case (moreReady++ready) of [] -> if null input then nullSPms else do i <- getSPms case [ih i | ih <- input] of p:ready' -> run p ready' [] p:ready' -> run p ready' input match :: MessageQueues -> [Guarded0 i o] -> (MessageQueues,[Guarded0 i o],[Process0 i o]) match m [] = (m,[],[]) match m (g:f) = case match1 m g of Nothing -> (m',g:f',r) where (m',f',r) = match m f Just (m1,p) -> (m2,f',p:r) where (m2,f',r) = match m1 f match1 :: MessageQueues -> Guarded0 i o -> Maybe (MessageQueues,Process0 i o) match1 m [] = Nothing match1 m ((AGuarded0 (Wno w) f):gs) = case IntMap.lookup w m of Nothing -> match1 m gs Just mq -> case Queue.head mq of Msg msg -> Just (m',cast f msg) -- ! type cast ! where mq' = Queue.tail mq m' = if Queue.null mq' then delete w m else modify Queue.tail undefined w m cast :: a -> b -- Not defined in Haskell.Figure 83. The scheduler.
The function match applies all guarded processes for
which there are matching messages. It returns the remaining
unmatched messages and guarded processes, together with a list
of new ready processes.
Recall that each element in the field guarded is itself
a list, which comes from a call to primRx. The function
match1 looks for a matching message for one of the
elements in such a list, possibly returning a new message
queue and a ready process. A matching message must have the
same wire number as the guarded process. It seems like this
cannot be expressed in the type system, so we are forced to
use a type cast (see the function match1 in
Figure 83).
The stateless processes can do stream-processor input/output
by means of get0 and put0. The output part is easy:
put0 :: o -> Process0 i o -> Process0 i o
put0 o p =
do putSPms (Right o)
p
getSPms, since that would block other threads as
well. Instead, the continuation is put on the input list in
the scheduler state, and jump to the scheduler. Note that more
than one process may call get0. As we have already
seen, the scheduler will ensure that all of them will receive
the next message that the stream processor inputs.
get0 :: (i -> Process0 i o) -> Process0 i o
get0 i =
do ps@(SS{ input }) <- loadSPms
storeSPms ps{ input = i:input }
scheduler
primTerminate0 simply jumps to the scheduler.To launch a process, the process state must be initialised. This is done inprimTerminate0 :: Process0 i o primTerminate0 = scheduler
primLaunch0.
primLaunch0 :: Process0 i o -> Process0 i o
primLaunch0 p =
do storeSPms SS{ freeWire = startWno
, messageQs = IntMap.empty
, ready = []
, guarded = []
, input = []
}
pGProcess0.The typestype GProcess0 = Process0 GEvent GCommand
GEvent and GCommand will be defined in
Section 31.2.4.GProcess0:A stateful process is a process-valued function which takes a stateless process continuation (parameterised over its input state), and an input state as parameters. It can modify the state before applying it to the continuation, and also use the stateless process primitives.newtype Process s = P ((s -> GProcess0) -> s -> GProcess0)
The state parameter is accessed by setState and
readState.
We now need to lift the primitive operations of typeunp (P p) = p setState :: s -> Process s -> Process s setState a p = P $ \c s -> unp p c a readState :: (s -> Process s) -> Process s readState p = P $ \c s -> unp (p s) c s
GProcess0 to Process. We use two auxiliary functions,
depending on whether the continuation takes an argument or
not. (This ``duplication of code'' is a price we pay for not
working with monads: in monadic style, all operations return a
value, which might be () if it is uninteresting. In
CPS, operations without a result take continuations without an
argument, which can be seen as a slight optimisation, but adds
to the complexity of CPS programming.)
liftP0arg :: ((a -> GProcess0) -> GProcess0)
-> (a -> Process s) -> Process s
liftP0arg p0 p = P $ \c s -> p0 (\a->unp (p a) c s)
liftP0c :: (GProcess0 -> GProcess0)
-> Process s -> Process s
liftP0c p0 p = P $ \c s -> p0 (unp p c s)The operations for creating a wire and transmitting a message are straightforward to lift.liftP0 :: GProcess0 -> Process s liftP0 p0 = P $ \c s -> p0
We will also need an auxiliary function to ``downgrade'' a stateful process to a function from state to a stateless process.primWire :: (Wire a -> Process s) -> Process s primWire = liftP0arg primWire0 primTx :: Out o -> o -> Process s -> Process s primTx o m = liftP0c $ primTx0 o m
When liftingdown :: Process s -> (s -> GProcess0) down (P p) s = p (\s' -> primTerminate0) s
primFrom, we must ensure that the
guarded processes get access to the state. Guarded stateful processes
are therefore guarded stateless processes parameterised over the state.Intype AGuarded s = s -> AGuarded0 GEvent GCommand type Guarded s = [AGuarded s] primFrom :: In m -> (m -> Process s) -> AGuarded s primFrom i p = \s -> primFrom0 i (\m -> down (p m) s)
primRx, we apply the state to each guarded process,
revealing the stateless guarded processes that primRx0
accepts.The remaining primitive operations are straightforward to lift.primRx :: Guarded s -> Process s primRx gs = P $ \c s -> primRx0 [g s | g <- gs]
primTerminate :: Process s primTerminate = P $ \c s -> primTerminate0 primSpawn :: Process a -> a -> Process s -> Process s primSpawn p' s p = liftP0c (primSpawn0 (down p' s)) p primLaunch :: Process s -> s -> GProcess0 primLaunch p s = primLaunch0 (down p s)
mouse, screen and
keyboard. We use the stream-processor input/output to
mediate the events and commands from/to the mouse, keyboard
and screen.Each device is controlled by two processes: the output handler, which injects commands received on a wire into the typedata GEvent = ME MouseEvnt | KE KeyboardEvnt | SE ScreenEvnt data GCommand = MC MouseCmnd | KC KeyboardCmnd | SC [ScreenCmnd]
GCommand and outputs them, and the input
handler, which inputs events, extracts those specific for the
device and transmit them on a wire. These two handlers run in
parallel. This is captured with the deviceHandler.
deviceHandler :: (c -> GCommand) -> (GEvent -> Maybe e)
-> In c -> Out e -> Process s
deviceHandler inj extract cw ew =
liftP0 $ primSpawn0 ohandler ihandler
where ohandler = primRx0 [primFrom0 cw $ \cmd ->
put0 (inj cmd) ohandler]
ihandler = get0 $ \i ->
case extract i of
Just evt -> primTx0 ew evt $
ihandler
Nothing -> ihandler
keyboard :: In KeyboardCmnd -> Out KeyboardEvnt -> Process s
keyboard = deviceHandler KC (\i -> case i of KE e -> Just e
_ -> Nothing)
mouse :: In MouseCmnd -> Out MouseEvnt -> Process s
mouse = deviceHandler MC (\i -> case i of ME e -> Just e
_ -> Nothing)
screen :: In [ScreenCmnd] -> Out ScreenEvnt -> Process s
screen = deviceHandler SC (\i -> case i of SE e -> Just e
_ -> Nothing)GEvent
messages. This is done in the fudget gadgetF, of type
Note that the high-level streams ofgadgetF :: Gadget -> F a b
gadgetF are
unused. It would be nice to use them for communication between
gadget processes and the rest of the fudget program, but this
is not possible in a type-safe way. The reason is that such a
communication could be used to exchange wires between
different instances of gadgetF. Each gadgetF has
its own scheduler, and mixing wires between schedulers is not
type safe. Figure 84. Example of wire queue length profiles,
provided by the Gadgets-in-Fudgets implementation. Each profile
represents one wire, its height is proportional to the length of
the queue of messages waiting to be delivered. The picture is a
snapshot of the computation; by pressing the button, a new
snapshot is taken. The time axis is the one growing into the
graph.
A disappointment is that we are not able to safely type check
all parts of the scheduler. Nevertheless, we believe that the
Haskell implementation is ``more'' type safe than the original
scheduler, which was written in C.

The functional scheduler also has a serious performance problem for certain processes. If a process dynamically creates wires, sends messages to them, and then forgets them, the wire queues cannot be garbage collected. The functional scheduler can never know if a process drops its reference to a wire.
A remedy for these problems is to use lazy state threads [LJ94] and their imperative variables for representing the queues.
To give you some idea of what the potential of the fudget library is, and to discuss various practical programming considerations, this part presents, in varying detail, some applications we have implemented using Fudgets.
In this section we will take a look at how such an application can be
implemented on top of the Fudget library, in Haskell. An actual
implementation, called WWWBrowser, was done mainly during the summer
1994. Some updates and improvements were made in the summer 1997. A
window snapshot is shown in Figure 85. Figure 85. WWWbrowser, a simple web browser implemented using
fudgets in 1994. It supports inlined images and forms.
The 1994 version of WWWBrowser had the following features:
Drawing
(see Section 27.4), using a function of the type
Html -> Drawing ... (roughly).
The old tailor made fudget kernels were thrown
out. The fudget library placer tableP was be used to add
support for tables (the table cell attributes rowspan and
colspan were not supported yet).URL and
Html. The key operations on these types are:
Documents are fetched from their location on the web by the fudgetdata URL = ... data Html = ... parseURL :: String -> Maybe URL showURL :: URL -> String joinURL :: URL -> URL -> URL parseHtml :: String -> Either ErrorInfo Html drawHtmlDoc :: URL -> Html -> HtmlDrawing type HtmlDrawing = Drawing ... -- details in Section 32.3
urlFetchF,
The fudgeturlFetchF :: F HttpRequest HttpResponse -- details in Section 32.2 data HttpRequest = HttpReq { reqURL::URL, ... } data HttpResponse = HttpResp { respBody::String, ... }
urlFetchF handles several protocol besides the
HTTP protocol, but since HTTP is the primary protocol on the
WWW, it was the one that was implemented first. The fudgets
for other protocols were then implemented with the same interface.
Documents are displayed by the fudget htmlDisplayF,
which displays HTML documents received on the input, and outputs requests for new documents when the user clicks on links in the document being displayed.htmlDisplayF :: F (URL,Html) HttpRequest
Not all documents on the WWW are HTML documents. Other types of documents (for example plain text, gopher pages, ftp directory listings and Usenet news articles) are handled by converting them to HTML:
The functiontoHtml :: (URL, HttpResponse) -> (URL,Html)
toHtml uses parseHtml and other
parsers.
Using the components presented above we can create a simple web browser by something like
But in addition to the HTML display, WWWBrowser provides back/forward buttons, an URL-entry field, a history window, a bookmarks menu, a document source window and a progress report field. The structure of the main fudget is shown in Figure 86. The layout is specified using name layout (see Section 11.2).simpleWebBrowser = loopF (htmlDisplayF >==< mapF toHtml >==< urlFetchF)
wwwBrowserF = httpMsgDispF >==< loopThroughRightF urlFetchF' mainGuiF >==< menusF where mainGuiF = urlInputF >*< srcDispF >*< (urlHistoryF >*< htmlDisplayF) >=^< toHtml httpMsgDispF = nameF "MsgDisp" $ "Progress:" `labLeftOfF` displayF urlFetchF' = post >^=< urlFetchF >=^< stripEither where post msg = ... urlInputF = ... parseURL ... stringInputF ... showURL ... srcDispF = ... urlHistoryF = ...Figure 86.
wwwBrowserF-- the main fudget in WWWBrowser.
urlFetchF is implemented as a parallel
composition of fudgets handling the different protocols. This is
shown in Figure 87. The function distr extracts
the protocol field from the request URL and sends the request to
the appropriate subfudget. The implementation of the individual protocol fudget kernels are written in continuation style. For the http protocol, the following operations are performed:
urlFetchF :: F HttpRequest HttpResponse urlFetchF = snd >^=< listF fetchers >=^< distr where fetchers = [("file",fileFetchF>=^<reqURL), -- local files and ftp ("http",httpFetchF), -- http and gopher requests ("news",newsFetchF>=^<reqURL), ("telnet",telnetStarterF>=^<reqURL) ] distr req@(HttpReq {reqURL=url}) = (fetcher,req) where fetcher = ...Figure 87. The fudget
urlFetchF.
The FTP protocol can also handle several requests per connection, and since you are required to log in before you can transfer files, it is even more beneficial to reuse connections.
The FTP protocol differs in that it uses a control connection for sending commands that initiate file transfers and a separate data connection for each file transfer. The data connection is normally initiated by the server, to a socket specified by the client. In the fudget implementation, these two connections are handled by two separate, but cooperating, fudgets.
is an element tagged as a top-level heading, and it has a nested element marked to be displayed with a typewriter font.<H1>The fudget <TT>htmlDisplayF</TT></H1>
There is a distinction between block-level elements and text-level elements. The former mark up text blocks that are to be treated as complete paragraphs. They are thus composed vertically. Heading elements are examples of block-level elements. The latter mark up arbitrary sequences of characters within a paragraph. Block-level elements can contain text-level elements (as in the example above), but not vice versa.
WWWBrowser makes use of the distinction between block-level and
text-level elements. This makes it easier to do the layout.
The function parseHtml builds a syntax tree which on the
top level is a sequence of block-level elements. Plain text
occuring on the top level, outside any block-level element,
is understood as occuring inside an implicit paragraph (
<P>) element. So, for example,
is parsed into the same syntax tree as as<H1>The fudget <TT>htmlDisplayF</TT></H1> The implementation of...
With this approach, the function<H1>The fudget <TT>htmlDisplayF</TT></H1> <P>The implementation of...</P>
drawHtmlDoc can simply recurse down the syntax tree, composing
the drawings of block-level elements using verticalP and
text-level elements using paragraphP.
Web pages contain not only text, but also images and form
elements. In WWWBrowser, these are implemented by embedding
fudgets in the drawing. We introduce the type
ActiveDrawing for drawings containing active components and
define the type HtmlDrawing introduced above as
wheretype HtmlDrawing = ActiveDrawing HtmlLabel Gfx HtmlInput HtmlOutput type ActiveDrawing lbl leaf i o = Drawing lbl (Either (F i o) leaf)
HtmlInput and HtmlOutput are the message types
used by the fudgets implementing images and forms. Elements with
special functionality are marked with a label of type
HtmlLabel. Currently, hyperlinks, link targets, forms and
image maps are labelled.
To display ActiveDrawings, a generalisation of
graphicsF (see Section 27.5.1) has been defined:
activeGraphicsF ::
F (Either (GfxCommand (ActiveDrawing lbl leaf i o)) (Int,i))
(Either GfxEvent (Int,o))htmlDisplayF uses activeGraphicsF to display
HTML documents. It also containsHttpRequest when the submit button of a form is pressed.imageFetchF (described below)
that the image fudgets communicate with to obtain the images
they should display.
htmlDisplayF uses the fudget imageFetchF for this:
The requests handled byimageFetchF :: F ImageReq (ImageReq,ImageResp) type ImageReq = (URL,Maybe Size) type ImageResp = (Size,PixmapId)
imageFetchF contain the URL of
an image to fetch and an optional desired size to which the
image should be scaled. The responses contain the actual size
(after scaling) and a pixmap identifier.
Since documents may contain many images and the time it takes
to fetch an image often is dominated by network latency
rather than bandwidth limitations, it makes sense to fetch
several images in parallel. The fudget parServerF,
is a generic fudget for creating servers that can handle several requests in parallel. If serverF is a fudget that handles requests sequentially with a 1-1 correspondence between requests and responses, then the fudgetparServerF :: Int -> F req resp -> F req resp
parServerF
n serverF handles up to n requests in
parallel.
Clients of parServerF must have some way of
telling which response belongs to which request, since the
order in which the responses are delivered is not guaranteed to
correspond to the order in which the requests are received. The fudget
imageFetchF accomplishes this by including the requests
in the responses.
We also want to avoid fetching the same image twice. This is solved by using a caching fudget,
cacheF :: Eq req => F req (req,resp) ->
F (client,req) (client,(req,resp))htmlDisplayF,
since it is common for the same image to occur in several places
in the same HTML document.)
In WWWBrowser, a composition like this is used to fetch images:
The implementation ofcacheF (parServerF 5 imageFetchF)
parServerF is shown in
Figure 88. The implementation of cacheF is shown
in Figure 89.
parServerF :: Int -> F req resp -> F req resp parServerF n serverF = loopThroughRightF (absF ctrlSP0) serversF where serversF = listF [(i,serverF) | i<-ns] -- n parallel servers ns = [1..n] -- server numbers ctrlSP0 = ctrlSP ns -- The argument to ctrlSP is a list of currently free servers ctrlSP servers = case servers of -- If all servers are busy, wait for a response. [] -> getLeftSP $ fromServer -- If there is a free server: s:servers' -> getSP $ either fromServer fromClient where fromClient req = -- When a requests is received, send it to the -- first server in the free list and continue -- with the remaning servers still in the free list. putSP (Left (s,req)) $ ctrlSP servers' where fromServer (n,resp) = -- When a response is received from a server -- output it and add the server to the free list. putSP (Right resp) $ ctrlSP (n:servers)Figure 88. The fudget
parServerF.
cacheF :: Eq req => F req (req,resp) -> F (client,req) (client,(req,resp)) cacheF serverF = loopThroughRightF (absF (cacheSP [] [])) serverF cacheSP cache pending = getSP $ either answerFromServerSP requestFromClientSP where requestFromClientSP (n,req) = -- A request from client n. assoc oldSP newSP cache req where oldSP ans = -- The answer was found in the cache. putSP (Right (n,(req,ans))) $ cacheSP cache pending newSP = -- A new request, send it to the server, and -- add the client to the pending list. if req `elem` map snd pending then cont else putSP (Left req) cont where cont = cacheSP cache ((n,req):pending) answerFromServerSP ans@(req,_) = -- The server delivered an answer to request req, -- save it in the cache, -- forward it to waiting clients and remove them from -- the pending list. putsSP [Right (n,ans) | (n,_)<-ready] $ cacheSP (ans:cache) pending' where (ready,pending') = part ((==req).snd) pendingFigure 89. The fudget cacheF.
urlFetchF does not output anything
until it has received the complete document.urlFetchF was changed to output chunks as they
are received, you would have to concatenate all the pieces
before you apply the function parseHtml to it.htmlDisplayF is implemented with
graphicsF. When graphicsF receives a new drawing to
display, it computes its size and adjusts the window size
accordingly before it draws anything in the window. This means
that it needs the complete drawing before it can display
anything.urlFetchF output a response containing the
document as a lazy list of characters as soon as it begins
receiving it from the server. This would allow you to apply the
parser and the drawing function immediately and send the
resulting drawing to graphicsF. The parser
parseHtml and drawing function drawHtmlDoc must be
carefully constructed to be lazy enough to produce some output
even when only an initial fragment of the input is available.
You would also have to change graphicsF so that it does not
start by computing the size of the drawing. It should instead
lazily compute drawing commands (see Section 27.2) to send
to the window system. The size of the window should be adjusted
regularly according to where the drawing commands generated so
far have drawn.
The above solution seems to require the introduction of some mechanism for indeterministic choice, since while the drawing commands for the document are being computed and output, the program should to continue to react to other input.
However, the trend in I/O systems for functional languages goes towards making I/O operations more explicit. Even the Fudget library has abandoned the representation of streams as lazy lists in favour of a simpler deterministic implementation. Using a lazy list for input as above is thus a step in the opposite direction. However, to program indeterministic systems on a high level of abstraction, streams as lazy lists seem to be useful.
One can of course think of ways of achieving incremental display without doing input in the form of lazy lists.
urlFetchF output chunks of characters as
they become available.
parseHtml would then be SP String Html instead of
String -> Html. However, we will not achieve incremental
display if we continue to output the syntax tree of whole
document in one message. We would instead have to output a
sequence of document fragments.htmlDisplayF would be document
fragments instead of complete document. We are thus moving one step in
the direction of an HTML editor instead of a simple display.The conclusion we draw from this is that the current I/O system in Haskell does not integrate well with laziness.
Alternatively, you can view Alfa as a syntax-directed editor for a small purely functional programming language with a type system that provides dependent types. The editor immediately checks that programs you enter are syntactically correct and type correct.
Alfa is largely inspired by Window-Alf [AGNvS94], implemented by Lena Magnusson and Johan Nordlander, and has a similar user interface.
The plan is that Alfa should improve on Window-Alf by
Figure 90. Window dump of Alfa, illustrating the construction of a simple proof in natural deduction style.
Whereas Window-Alf was implemented in Standard ML (proof engine) and C++ & Interviews (user interface), Alfa is implemented entirely in Haskell, using Fudgets for the user interface. At the time of writing, the source code consists of about 8000 lines, distributed as follows:
Figure 91. The smiley indicates whether there is a syntactic error in the input.
More detailed and up-to-date information on Alfa is available on the WWW [Hal97].
In the current version, the user interface shows
Figure 92. The user interface of Humake.
dependencyF. It traverses the modules to extract the
module-dependency graph and builds a representation of it. It
also maintains a data structure representing the status of the
compilation process. This structure is chosen so that when a
compilation completes, or a module is updated, a new compilation
can be started as quickly as possible.
The source is about 1200 lines long.
Figure 93. Implementation of Humake.
main = fudlogue $ shellF "Humake" humakeF
humakeF =
loopLeftF ((moduleInfoF>+<parallelCompileF) >==< dependencyF)
>==< editorInterfaceF
--- GUI fudgets:
statusDisplayF = ... --the bottom part of the window
moduleInfoF = ... -- the module list, module info and the update buttons
--- Non-GUI fudgets:
parallelCompileF =
filterRightSP >^^=< (statusDisplayF>+<idF) >==<
loopThroughRightF (absF ctrlSP) (parServerF hosts compileF)
where
ctrlSP = ...
parServerF :: [id] -> (id->F req resp) -> F req resp
parServerF ids serverF = ... -- essentially as in Figure 88
compileF :: String -> F CompilerReq CompilerResp
compileF host = ... -- a compilation server
editorInterfaceF :: F a String
editorInterfaceF = ... -- outputs the name of a file when it is saved
Figure 94. Space Invaders -- a typical interactive real-time game.
In this game, an army of invaders from outer space is approaching the earth. The player must shoot them all down before they reach the surface. Some points are added to the player's score for each invader that is shot down. The player controls a gun, which can be moved horizontally at the bottom of the screen (the surface of the earth) and which can fire vertically. The invaders initially move from left to right. When the right-most invader reaches the right edge of the screen all invaders first move downwards a small distance, then move horizontally again until the left-most invader reaches the left edge, and so on.
spaceF: the space fudget. This is the black background in
which all the other objects move around.gunF: the gun.torpedoF: the torpedoes fired by the gun.invaderF: a number of invadersscoreF, which displays the current score and a
high-score. gunF and torpedoF use timers internally to control
the speed of their motion. To coordinate the motion of the
invaders, they are controlled by a common timer which is located
in a windowless fudget called tempoF. There is also an abstract
fudget called shoutSP, which broadcasts timer alarms and other
input to all invaders.
Section 35.2 illustrates how the fudgets are interconnected. The
information flow is as follows: the space fudget outputs mouse
and keyboard events to Figure 95. The processes and their interconnection in
the Space-Invaders implementation.gunF. (This allows the user to place the
mouse pointer anywhere in the window to control the gun.) The
gun responds to these events by starting or stopping its movement, or
by firing a torpedo. When the gun is fired, it outputs its
current position to the torpedo fudget. The torpedo then starts
moving upwards from that position. When it hits something, it
outputs its current position to the invaders. Each invader then
checks if the hit is within the area it occupies on the screen
and, if so, it removes its window and dies. 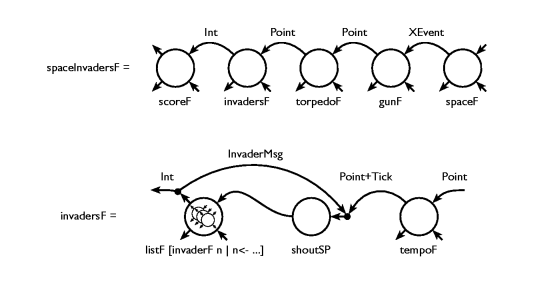
Below, we take a closer look at invaderF. The other fudgets are
just variations on a theme, so we will not discuss them further.
The fudget invaderF maintains an internal state consisting of the
following parts: the current position (a Point), the current
direction (left or right), if it is time to turn (i.e., move
downward at the next timer alarm, and then change directions).
The invaders speak the following language:
When an invader hears adata InvaderMsg = Tick | Turn | Hit Point | Death (Int,Int)
Tick, it moves one step in the current
direction. It also checks if it has reached an edge, in which
case it outputs Turn, which is received by all invaders. When an
invader hears a Turn it remembers that it is time to turn at the
next Tick. When a torpedo has hit something at position
p, all
invaders receive Hit p, and check if p is within their screen
area. If so, it outputs Death n, where n is the
identity of the invader. This identity is recorded by shoutSP,
so that it does not have to shout
to dead invaders. It is also used to determine how many points
to add to the score.
The fact that all objects are implemented as group fudgets means that each object has its own X window. To move an object you move its window. No drawing commands need to be output.
How does the torpedo know if it has hit something? The torpedo
is a window which moves behind all other windows. This means
that it becomes obscured when it hits something. The X server
sends a VisibilityNotify event when this happens. This causes
the torpedo to stop and send its current position to the
invaders. (Nice hack, isn't it? But isn't there a timing problem?
And what if the torpedo is obscured by some other application
window? We leave it to the reader to ponder over this.)
We have measured the CPU time consumption of the Space-Invaders
implementation described above running on a Sparcstation IPX in
a situation where 55 invaders move twice per second, the gun and
the torpedo move every 30ms. The average CPU load was
approximately 60%. 10% of this was consumed by the X server. As
a comparison, the program xinvaders, a C program implemented
directly on top of Xlib, consumes less than 5% CPU time in a
similar situation.
As usual, programming on a higher abstraction level results in a less efficient solution. Part of the inefficiency comes from the use of Haskell and the Fudget system. The load on the X server comes from the fact that the moving objects are represented as windows. Not surprisingly, moving a window is a more expensive operation than just drawing an image of the same size. But using techniques outlined in the next section, it is possible to rewrite the Fudget program to draw in a single window, like the C program, and still keep the same nice program structure, i.e., one process per moving object.
Above, we compared the efficiency of a high-level implementation (using the Fudget system) of the game with a low-level implementation. It would also be interesting to compare other user interface toolkits, e.g. Motif and Interviews, to the Fudget system.
The CPU time consumption figures above do not say much about
the real-time behaviour of the two implementations. The fact is
that the C program meets the real-time deadlines, but the Fudget
program does not. As a response to a Tick from tempoF, all 55
invaders should move one step. Computing and outputting 55
MoveWindow commands unfortunately takes longer than 30ms,
which means that the MoveWindow commands for the gun and the
torpedo will be output too late, resulting in a jerky
motion. This problem can be solved in at least two different
ways: manually, by not moving all 55 invaders at the same time
and thus not blocking output from other fudgets for longer than
30ms; automatically (from the point of view of the application
programmer), by introducing parallel evaluation and some kind of
fair, indeterministic merge of the output from different
fudgets. The latter solution is of course the more general one,
and we hope to improve the Fudget system in this direction.
The behaviour of a single fudget is usually implemented as a
sequential program by using the stream-processor operators
putSP, getSP and nullSP.
To increase the efficiency of our space
invaders implementation, we can instead structure the program as
one fudget whose behaviour is described by some composition of
stream processors. This increases the efficiency in two ways:
fudlogue (Section 22.2.2) will be somewhat
cheaper, and that the load on the X server is reduced (since windows
will not be moved).listF (tagged parallel
composition) and a separate stream processor shoutSP. Some
overhead can be avoided by using untagged parallel composition
of stream processors instead:
This also makes it easy to write stream processors that dynamically split into two or more parallel processes. One of the processes in a parallel composition can terminate without leaving any overhead behind, since-*- :: SP a b -> SP a b -> SP a b
Doing the same with processes represented as fudgets would not give you the same efficiency advantage since the low-level streams remain tagged even in untagged parallel compositions. Thus when one process in a parallel composition terminates, some tagging overhead will remain.nullSP -*- sp == sp -*- nullSP == sp
The fact that parallel compositions can reduce to nullSP
gives us an opportunity to make use of the sequential
composition operator seqSP (Section 16.4) in an
interesting way. Suppose that all that is needed to start a new level
in the game is the creation of a new army of invaders. Then the
behaviour of the game could be programmed in the following way:
When the last invader in the invader army dies, the parallel composition will be reduced toplayGameSP = playLevelSP 1 playLevelSP level = startNewLevelSP level `seqSP` playLevelSP (level+1) startNewLevelSP level = invaderArmySP level invaderArmySP level = ... -- creates a parallel composition of invaders
nullSP, which causes
seqSP to invoke the next level.
A screen dump of FunGraph is shown in Figure 96. Basically, FunGraph is a free-form spread sheet with types, where the user can place and connect objects such as cells, sliders and graphs at will. The objects have input connectors on top, and output connectors below.
FunGraph was developed before the fudget Figure 96. A screen dump of the program FunGraph. Two sliders controls
amplitude and frequency of a sine function defined in a
cell. This function is then visualised in a graph. The bubble
window (implemented by The cell also shows the visual effect of one of the filter
fudgets in the library, which is called the graphicsF of
Section 27.5.1 was implemented. Instead, graphics where
implemented with fine grained fudgets, so to speak. Each object is
implemented with a number of fudgets. So each pin is a
separate fudget, for example. The objects reside in a
dynListF placed in a group window which controlled the wires. All
messages from the output pins of the objects are routed by the
group window's kernel and looped back into the dynListF, so
that the values seem to follow the wires. 
bubbleRootPopupF) shows the type
of the pin that the user points at for the moment, which
happens to be the left input pin of the graph object. It has
the type Num -> Num, which is the type of the functions
that the graph object can display.
shapeGroupMgr. The cell is currently being selected, which is
indicated by a yellow, glowing border around it. This effect
is achieved by wrapping a shaped window whose border tightly
follows the fudgets inside it (in this case three pin fudgets
and one stringF). The border of the shaped window is
yellow, and its width is set to zero when the object is
deselected, or a couple of pixels as is the case with our
cell. The shapeGroupMgr ensures that the shape of the
yellow-border window tightly follows the contour of the
wrapped fudgets by analysing the ConfigureWindow
commands that they output.
Figure 97. The user interface of the protocol prototyping tool.
The two games use the same underlying combinators for implementing the board. The first is a button that can display changing graphics:
boardButtonF :: (ColorGen bgcolor, Graphic gfx) =>
bgcolor -> Size -> F gfx Click
boardButtonF bg size =
buttonF'' (setBgColor bg) (g (blankD size)) >=^< Left . setLabel . g
buttonF'' is the dynamically customisable (see
Section 30.3) version of buttonF and
setLabel is a customiser that changes the button
label.
The second combinator is boardF,
which, given the size of the board and a function from the coordinates of a square to a fudget implementing that square, creates a parallel composition of square fudgets with the appropriate layout. The square fudgets are addressed with their coordinates.type Coord = (Int,Int) boardF :: Coord -> (Coord -> F a b) -> F (Coord,a) (Coord,b) boardF (w,h) squareF = placerF (matrixP w) $ listF [((x,y),sqF (x,y)) | y<-[0..h-1],x<-[0..w-1]]
Figure 98. The Explode game.
Figure 99. The Othello game.
In the Explode game, two players take turns placing stones, or atoms, in the squares of a board. A player can not place atoms in a square that already contains atoms from the opponent. When a square is full, that is, contains as many atoms as it has neighbours, it explodes, sending one atom to each neighbour. All atoms of the invaded square change color to the invading atom's color. Invaded squares may become full and explode in turn. When the board has settled, a new move can be entered. When the board starts to get full of atoms, placing a new atom may cause an infinite chain reaction. When this happens, the game is over and the player who caused it is the winner.
Comments:
main = fudlogue (shellF "Explode" explodeBoardF) explodeBoardF = loopF (absF routeSP >==< boardF boardSize boardSize atomsSquareF) where routeSP = concatMapAccumlSP route White route side (src,msg) = case msg of ClickedWhileEmpty -> (otherSide side, [(src,side)]) ClickedWithColor side' -> if side'==side then (otherSide side, [(src,side)]) else (side, []) -- illegal move Explode dsts side' -> (side, [(dst,side')|dst<-dsts]) atomsSquareF :: Coord -> F AtomColor (SquareEvent Coord) atomsSquareF (x,y) = loopThroughRightF (absF ctrlSP) atomsButtonF where ctrlSP = concatMapAccumlSP ctrl (0,Nothing) ctrl s@(oldcnt,oldside) msg = case msg of Left Click -> (s,[Right (case oldside of Just side -> ClickedWithColor side Nothing -> ClickedWhileEmpty)]) Right side -> let cnt=oldcnt+1 in if cnt>=size then become (cnt-size) side (explodemsgs side) else become cnt side [] become cnt side msgs = ((cnt,optside),Left (cnt,side):msgs) where optside = if cnt==0 then Nothing else Just side size = length neighbours explodemsgs = (:[]) . Right . Explode neighbours neighbours = filter inside2d [(x-1,y),(x+1,y),(x,y-1),(x,y+1)] inside2d (x,y) = inside x && inside y inside x = 0<=x && x<boardSize atomsButtonF :: F (NumberOfAtoms,AtomColor) Click atomsButtonF = boardButtonF bgColor sqsize >=^< drawAtoms drawAtoms (count,color) = ... -- 20 linesFigure 100. Fudgets implementation of the Explode game.
routeSP allow
all square fudgets to communicate with each other. However, each
square knows its coordinates and send messages only to its
neighbours. The actual communication structure is thus not
directly reflected in the program structure.routeSP also acts as a referee. It keeps track of whose
turn it is, to be able to discard illegal moves.
This is also where you would put a test for
explosions involving all squares (which should end the
game). Otherwise, all the work is done by the squares
themselves.SquareEvent:
data SquareEvent dest
= ClickedWhileEmpty
| ClickedWithColor AtomColor
| Explode [dest] AtomColorClickedWhileEmpty "I was clicked and I was
empty". routeSP then replies with an atom of the appropriate
color (depending on whose turn it is).ClickedWithColor color: "I was clicked and my color
was color". If the color matches with color of the current
player, routeSP replies with an atom of that color, otherwise
the message is ignored (some indication of an illegal move
could be produced).Explode square color: "I explode and
invade square with color". routeSP
forwards the message to the square at square. 2-4 messages of
this kind are sent when a square explodes.atomsButtonF.drawAtoms in atomsButtonF
produces the appropriate graphical image for a square, using
the types FlexibleDrawing and Drawing described in
Chapter 27.In the Fudgets solution, the squares are in effect connected to all other squares, whereas in the Gadgets solution, each square process is connected through wires only to its neighbours. As noted in [NR95], combining fudgets to achieve exactly this connectivity would be difficult, and it would probably also be difficult to add new processes to such a solution.
As described above, in the current Fudgets solution, each square fudget knows its coordinates and computes the coordinates of its neighbours. It would of course be possible to parameterise the square fudgets by an abstract representation of the neighbours instead,
and letatomsSquareF :: [address] -> F AtomColor (SquareEvent address)
routeSP compute the concrete addresses of the
neighbours. This perhaps makes the communication pattern more
visible in the program text and prevents errors in the
implementation of atomsSquareF from breaking the pattern.
Since the Gadgets system uses indeterministic process scheduling, it is necessary to explicitly keep track of when an explosion is in progress and when the board is stable, since moves are allowed to be entered only when the board is stable. The implementation of Fudgets is deterministic and internal communication has priority over external communication, so user input is automatically queued until an explosion has subsided.
In the implementation of the Explode game, we used a distributed
solution: the work of computing the effects of the users' moves is
handled almost entirely by the square fudgets. In the
implementation of Othello, we have taken the opposite approach:
the board fudget only displays the board and receives user
input. The checking of the validity of a move and computation of
its effect is handled by a stream processor attached in the
typical way with the loopThroughRightF combinator (see
Section 18.2). The structure of the program is:
The functionmain = fudlogue (shellF "Othello" ottoF) ottoF = displayF >==< loopThroughRightF (absF newGameSP) ottoBoardF >==< buttonF "New Game" ottoBoardF :: F BoardReq Coord ottoBoardF = ... newGameSP = playSP (reptree moves startpos) playSP :: GameTree -> SP (Either Coord Click) (Either BoardReq String) playSP current_position = ...
reptree (lazily) computes a game tree which has
startpos as the root node and where the children of a node
are obtained by applying the function moves to it.
The stream processor playSP checks the current position for
whose turn it is to play, and then either waits for the user to
enter a move or computes a good move for the computer using
standard alfa-beta game-tree search.
We can distinguish two kinds of efficiency:
In the following section, we will discuss, in the context of the Fudgets system, how we obtain reasonable execution efficiency. We have not tried to quantify programmer efficiency in a way that permits further comparison or judgement.
Two tiny programs:
The Fudgets counter example from Section 9.4: 13s The Motif counter example from Figure 112: 14s Some small programs:
The Fudget calculator from Section 9.8 with 15 buttons: 13s The Fudgets calculator Cla with 28 buttons: 16s The calculator xcalc with 40 buttons, from X Windows distribution: 18s Some larger programs:
The Fudgets WWW browser from Chapter 32: 22s Mosaic 2.6: 75s Netscape 3.0: 137s Netscape 4.04j2: 313s Figure 101. Comparing the startup times of some programs when running via a 16.8kbps modem connection.
When it comes to event processing, we naturally wanted to to minimise the number of events that has to be handled by the functional program. Fortunately, the X Windows system can do a lot of event processing for the application. By setting event masks and button grabs appropriately, you can often eliminate all insignificant events, i.e., all events that are sent to the application program carry some meaningful information. In simpler window systems, the application has to deal with every little mouse move and button/key presses/releases by itself.
XGrabButton() in
the Xlib manual) with an event mask that selects button
presses/releases and enter/leave window events (each GUI
element is a window), can be used to select exactly these events,
with only one small exception: if the mouse pointer enters the
button area, the mouse button is pressed, the pointer leaves
the button area and the mouse button is released, the program
will receive an insignificant button release event. The
important thing is that no unnecessary motion events will be
received.We also tried a third representation,
which was slightly less efficient than the continuation-based representation.data SP i o = StepSP [o] (i->SP i o)
In the discussion below, we assume the continuation-based representation (although some of the ideas can be carried over to other representations).
loopThroughRight (Section 18.2) is a general way to
adapt an existing stream processor for use in a new
context. Another simple and common way to adapt a stream
processor is by mapping a function on the elements of the
input or output stream:
For example, tagged parallel composition of fudgets, >+<, can be defined likesp -==- mapSP g mapSP f -==- sp
wherefud1 >+< fud2 = mapSP post -==- (fud1 -+- fud2) -==- mapSP pre
pre and post are the appropriate re-tagging
functions. However, if implemented directly, such a
definition has a rather high overhead.
By transforming >+< to a form not involving -==-,
-+- and mapSP, but instead recursion and
pattern matching on the stream-processor constructors, a
more efficient solution can be obtained.
Programs transformations of this kind are tedious to do by
hand, but it could still be worthwhile if the resulting code
is to be included in a library. The above described
transformation has been done by hand in the Fudget library. We
measured the effect on a communication intensive fudget
program containing a parallel composition of 50 fudgets (the
Space Invaders program described in
Chapter 35). The transformation reduced the CPU
time consumption by over 35%. Encouraged by this result, we
also transformed some more combinators (for example
>^=< and >=^< discussed in
Section 13.1) in the same way.
It would of course be nicer to have these transformations
done automatically, especially when they are needed in
application programs. The kind of automatic transformation
that would be useful here is deforestation
[Wad90], which eliminates
intermediate data structures (applications of PutSP
and GetSP in this case) by using certain unfold/fold
transformations.
The manual work required in this solution is located in the library. The application programmer need not be aware of it. The automatic work required is inlining (unfold) by the compiler. It actually works even without inlining, but the efficiency gain is not as big.
The expressions we wish to optimise are of the kind
illustrated above: a stream-processor combinator applied to
mapSP f, for some f.
The trick is to make mapSP a constructor
in the stream-processor data type:
data SP a b = PutSP b (SP a b)
| GetSP (a -> SP a b)
| MapSP (a -> b)
| NullSP Now that MapSP is a constructor, the implementation of
serial composition (as shown in Figure 45) can be
extended to handle the case when one or both arguments are
applications of MapSP in a more efficient way. This
means that an expression like
can evaluate toMapSP f -==- MapSP g
With inlining, this step can be taken by the compiler and the compositionMapSP (f . g)
f . g can then be optimised
further. Without inlining, we have at least eliminated a use
of -==-, and thereby reduced the number of
generated applications of the PutSP and GetSP
constructors.
We have not tested the above ideas in the Fudget library.
The first test measures the efficiency of serial composition
and compares the operators >==<, >^^=<
and -==-. We measured the time it took to send
around 5000 messages through a serial composition of a
varying number of identity fudgets (or identity stream
processors). The program used is shown in
Figure 102. It was compiled with HBC and run on a
Pentium Pro 200Mhz under NetBSD 1.2 [Neta]. The
results are shown in Figure 103. We can
see that the time grows roughly linearly with the length of
the composition and that serial composition of fudgets is
much more expensive than serial composition of stream
processors.
The last table in Figure 103 shows the
performance of the function composition Figure 102. A program to measure the efficiency of
serial composition. map id . map id . ... . map id Figure 103. The efficiency of serial
composition.map id .
... . map id. It is more efficient than the other
serial compositions.
import Fudgets
main = fudlogue mainF
mainF = nullF >==< tstF >==< concatSP >^^=< stdinF
tstF = case argReadKey "comb" 1 of
1 -> nest (idF>==<) idF depth
2 -> nest (idSP>^^=<) idF depth
3 -> absF (nest (idSP -==-) idSP depth)
nest f z 0 = z
nest f z n = f (nest f z (n-1))
depth = argReadKey "depth" 0
time ./Internal <testinput1 -S -h8M - -depth n
-comb 1 (idF >==< idF >==< ... >==< idF):
n User time GCs GC time Max heap Max stack
0 0.080u 0 0.00
50 4.173u 40 0.10 62432 836
100 8.475u 80 0.25 95840 1410
200 18.418u 163 0.95 159884 3042
400 44.521u 334 3.35 288020 3768 -comb 2 (idSP >^^=< idSP >^^=< ... >^^=< idF):
n User time GCs GC time Max heap Max stack
0 0.100u 0 0.00
50 0.755u 8 0.01 35712 210
100 1.452u 15 0.03 42270 272
200 2.869u 30 0.08 53504 642
400 5.706u 59 0.18 76976 1218 -comb 3 (idSP -==- idSP
-==- ... -==- idSP):
n User time GCs GC time Max heap Max stack
0 0.076u 0 0.00
50 0.411u 4 0.01 32524 171
100 0.812u 7 0.00 35840 348
200 1.574u 15 0.04 41956 651
400 3.047u 30 0.07 54924 1260
n User time GCs GC time Max heap Max stack
0 0.000u 0 0.00
50 0.094u 2 0.00 3956 98
100 0.203u 4 0.00 5616 275
200 0.434u 8 0.00 9712 566
400 0.906u 16 0.01 17616 473
The second test measures the efficiency of parallel
composition. We measured the time it took to send about 70000
messages through one of the fudgets in a parallel
composition of identity fudgets. The program used is shown in
Figure 104. The parallel compositions were created
by listF,
which internally constructs a balanced binary tree of parallel compositions and a table for translating the addresses of the fudgets to positions in the tree. The results are shown in Figure 105. The depth of the tree, and hence the time it takes to send a message to a particular fudget in tree grows logarithmically with the size of the parallel composition. However, since all that is known about the address type is that it is an instance of thelistF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c)
Eq
class, the table lookup has to be implemented as a linear
search and hence the lookup time varies linearly with the
position in the list. From the results we see that the time of
the table lookup soon becomes the dominating factor.
This suggests that it would be a good idea to
provide alternative combinators to listF, which require
the address type to be an instance of the Ord class, or
even the Ix class, to reduce the time complexity of the
table lookup time to logarithmic or constant, respectively.
Figure 104. A program to measure the efficiency of parallel composition.
k=1
n 2log n time GCs GC time max heap 1 0 1.352u 11 0.02 29908 32 5 2.179u 18 0.03 34924 256 8 2.457u 22 0.07 66744 2048 11 2.989u 27 0.31 317776 n=256
k 2log n time GCs GC time max heap 64 8 4.640u 33 0.11 127 8 7.001u 44 0.12 128 8 6.801u 44 0.16 256 8 11.126u 67 0.24 87880 Figure 105. The efficiency of parallel composition of fudgets.
Through experiences with other languages, we have also realised that some languages features not currently supported by Haskell would be useful to have.
As a simple example, say that you are going to use the function
show a lot and want to introduce a shorter name, s
say. Because of the monomorphism restriction, you can not write
There are two solutions: you can provide a type signatures = show
or you can eta-expand the definitions :: Show a => a -> String s = show
In the Fudget library, we have used the eta expansion trick whenever possible, since the inclusion of explicit type signatures just entail extra maintenance work when the library is changed. For example, when a type is renamed or a function is made more general, an arbitrary number of type signatures may need to be updated.s x = show x
Unfortunately, the eta expansion trick can not always be used,
because not all overloaded values are functions. For example,
fudgets are not functions, so in case you want to introduce a
short name for displayF, you have to use a type
signature:
Even more unfortunately, there are cases when it is not possible to express the type signature. This occurs when the definition is local to another definition which is polymorphic. It can happen that the local type depends on type variables in the outer definition, but Haskell has no mechanism for expressing such types explicitly. Although these cases turn out to be rare in practice, it is a principal flaw of the language.dF :: (Graphic a) => F a b dF = displayF
String an instance of a class. This
is due to the combination of two facts:String is not a data type, but a synonym for [Char].Char, and for lists in general, but you can not make
a particular instance for [Char]. (See [JJM97] for a
discussion of class system design choices.)Graphic, ColorGen and
FontGen presented in Chapter 27, and
FormElement in Section 29.2. At one point during the
development, we avoided the problem by defining a data type that
was used instead of strings,
but since this required the use of the constructornewtype Name = Name String
Name in a lot of places, we later resorted to the same
hack that is used for the Haskell classes Show and Read,
i.e., we added
extra methods for dealing with lists to the classes. This allow the
methods for strings to be defined in the instance declarations for
Char.
This means that instead of getting an instance for String, you
get instances for Char, String, [String],
[[String]] and so on. For
our classes it was not too difficult to invent a meaning for the
extra instances: Char was treated as one-character strings. For the
Graphic class, (nested) lists of strings are drawn by drawing all
the strings using some layout chosen by the layout system. For the
ColorGen and FontGen classes, lists were taken to mean spare
alternatives: you can write, e.g., ["midnightblue","black"] to
provide one nice color and a safe fallback color. Empty lists can
give run-time errors, but are also likely to cause typing problems
(making the overloading unresolvable) which are discovered at
compile time.We have found existential types useful in several contexts: the implementation of Gadgets in Fudgets (Chapter 31), the combinators for syntax-oriented manipulation (Chapter 28) and the datatypes for graphics (Chapter 27).
Since existential types are not part of the Haskell standard, we
have tried to keep their use away from core machinery of the
Fudget library. Instead we use them on the side to provide a nice
feature as an additional bonus. This has affected how we used them
in the graphics data types. For example, since leaves of drawing
usually are of type Gfx, we could have used existential
quantification directly in the Drawing type,
eliminating the need for the typedata Drawing lbl = Graphic leaf => AtomicD leaf | ...
Gfx. We could also have
defined the GCSpec type as
allowing you to write for exampledata GCSpec = (ColorGen c, FontGen f) => SoftGC [GCAttributes c f] | HardGC GCtx
instead ofSoftGC [GCForeground "red"]
SoftGC [GCForeground (colorSpec "red")]
>+< and
the list combinator listF:
The former allows the composed fudgets to have different types, but composing a large number of fudgets make addressing the individual fudgets clumsy: you use compositions of the constructors>+< :: F a b -> F c d -> F (Either a c) (Either b d) listF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c)
Left and Right.
The latter makes it easy to compose many fudgets, but they must all have the same type.
The use of dependent types would allows us to define a combinator that
combines the advantages of >+< and listF. In type
theory [NPS90], there are two forms of dependent types:
dependent products (function types), and dependent sums
(pairs). The second form is the one we need here. It allows us to
construct pairs, where the type of the second component
depends on the value of the first component.
Using a Haskell-like notation, we write
for the pair type where the first component is of type a and the second component is of type(t::a, b t)
b t, where t is
the value of the first component. Note that b is a function
returning a type.
By viewing t as a tag, we can form lists of tagged values
of different type, and define a variant of listF with the
following type:
dListF :: Eq a => [(t::a, F (i t) (o t))] -> F (t::a, i t) (t::a, o t)
Sequential composition is useful for structuring textual user interfaces, where the interaction can be seen as a dialogue between the computer and the user, that is, a linear sequence of input and output actions. In the following we give a brief overview of combinators for sequential composition of effects. More developed reviews can be found in Noble's and Gordon's theses [Nob95][Gor92].
Events and output a stream of
Commands. The type of the components is:The idea is that a component consumes an initial segment of the input stream and returns some commands to be output and the remainder of the input stream. It may also use and modify some global state information.type Dlg state = state -> [Event] -> ([Command], state, [Event])
Sequential composition is defined as
join :: Dlg state -> Dlg state -> Dlg state
join dlg1 dlg2 state1 events1 = (cmds1++cmds2,state3,events3)
where
(cmds1,state2,events2) = dlg1 state1 events1
(cmds2,state3,events3) = dlg2 state2 events2
put :: Command -> Dlg state put cmd state events = ([cmd],state,events) get :: (Event -> Dlg state) -> Dlg state get edlg state (event:events) = edlg state event events
The type of the sequential composition operator istype Interaction a b = a -> [Event] -> ([Command], b, [Event])
and the definition is the same as forsq :: Interaction a b -> Interaction b c -> Interaction a c
join above. (Neither
the type of join nor the type of sq is the most
general type of this function.) Monads for I/O build on a type IO a--which
represents I/O effects that return a value of type a,
when carried out--and the bind operation
>>=, which is used for sequential composition. The bind
operation also binds the return value of the first I/O operation to
a variable so that it can be used in further operations in the
sequence:
The bind operation comes with an identity, called>>= :: IO a -> (a -> IO b) -> IO b
return, which simply returns a value without any I/O.
Thereturn :: a -> IO a
IO type can be seen as a function that transforms
the world regarded as a state, and also returns a value:
type IO a = WorldState -> (a,WorldState)
Object, to capture dynamic evolution of dialogues:
The typedata Object t s = O t (Cond s) ([Object t s] -> Dlg s) type Cond s = s -> [Event] -> Bool
Object t s represents a potential
dialogue. An object value O t c k
has a tag t, and a condition predicate c, which
signals if the continuation dialogue k is applicable in
the current state of the program. Among other things, the
conditions predicates were used to test if the user had clicked
within the area that a button occupied. If the predicate
c is true, k is applied to a list of active objects to
get a dialogue. This is done by the function treeCase,
which takes a list of active objects as an argument, and
schedules the first object with a true condition predicate:
The continuation k can do some I/O, and then again callstreeCase :: [Object t s] -> Dlg t s
treeCase, with a manipulated list of active objects, thus
allowing a new set of possible dialogues. In the manipulation,
the tags are used as pointers into the list.
Noble implemented process scheduling and channel communication in the runtime system of Gofer [Jon91], and added primitives for communication with X Windows. A feature of Gadgets is that it only uses the most basic drawing operations in the Xlib interface in one single X window. On top of this, Noble has implemented a functional window system, complete with a window manager.
The gadget in Figure 106 implements the up/down
counter, except that it uses a bar graph to display the
value. Figure 106. The Gadget up/down counter.
The counter gadget uses the following library gadgets:

main = go [(counter,"Up/Down")]
counter :: Gadget
counter =
wire $ \w ->
let b1 = button' (picture uparrow) (op w) (+1)
b2 = button' (picture downarrow) (op w) (+(-1))
g = bargraph [ip w] in
wrap' (border 20) (b1 <|> g <|> b2)
Gadgets uses the same mechanism for default parameters as described in Chapter 15, sobutton' :: Change ButtonAttributes -> Out a -> a -> Gadget bargraph :: [In (Int -> Int)] -> Gadget wrap' :: Change WrapAttributes -> Gadget -> Gadget
button' and
wrap' are customisable versions of button and
wrap. The button gadget button o a will
send the value a on the wire output end o,
whenever it is clicked. The gadget bargraph is
waits for input functions on any of the wire input ends in
is, and when such a function arrives, it is used to
update the level of the bar graph. Note how the wire w
is used to connect the two buttons to the bar graph. The
layout of the three gadgets is specified to be vertical using
the operator <|>. The example shows how the
specifications of layout (by gadget combinators) and dataflow
(by wires) are separated in Gadgets. Finally, the wrap'
gadget puts some space around the three gadgets.
The button parameter picture is used to specify up
and down arrows:
The typeuparrow, downarrow :: DrawFun
DrawFun roughly corresponds to the
FlexibleDrawings in Section 27.3.The separation between user interface and application code can be explained by studying the type of a couple of common GUI element, namely push buttons and labels:
The monadic expressionbutton :: Picture -> a -> DC -> IO (Button a, DisplayHandle) label :: String -> DC -> IO (Label, DisplayHandle)
button p v
d creates a button which will show the picture p. The
button's value is v, and d is an environment, or
display context which carries default values (Haggis uses
this for customisation, instead of the default parameter
mechanism in Fudgets and Gadgets). The monadic expression
returns an application handle of type Button, and
a display handle. The GUI element label does also
return a display handle, but its application handle has a
different type. The display handles are pointers to the GUI
elements, and can be combined with other display handles with
layout combinators, for example hbox:The application handles can be used to modify various aspects of the GUI elements, depending on their type:hbox :: [DisplayHandle] -> DisplayHandle
The most important feature of the button handle is the possibility to wait for it to be clicked:setButtonLabel :: Button a -> Picture -> IO () disableButton :: Button a -> IO () enableButton :: Button a -> IO () setLabel :: Label -> String -> IO ()
WhengetButtonClick :: Button a -> IO a
getButtonClick b is called in a process,
it will be suspended until the user clicks b, and then
the button's value is returned. Internally, this uses a
trigger (which can be seen as value carrying condition
variable), one of several synchronisation abstractions that
Haggis provides on top of Concurrent Haskell's value carrying
semaphore type MVar.
The type Picture corresponds somewhat to the
Drawing type in Section 27.4, and permits advanced
structured graphics to be defined. Haggis pictures are
described further in [FJ95].
In Figure 107, we see a version of the the up/down
counter in Haggis. Figure 107. The Haggis up/down counter.
The function
counter :: DC -> IO ((Label, Button (Int->Int)), DisplayHandle)
counter env =
label (show start) env >>= \(lab,ldh) ->
button (text "Up") (+1) env >>= \(inc,idh) ->
button (text "Down") (+(-1)) env >>= \(dec,ddh) ->
combineButtons [inc,dec] >>= \btn ->
return ((lab,btn), hbox [ldh, idh, ddh])
start = 0
main =
wopen ["*name: Counter"] counter >>= \((lab,btn),_) ->
let count n = getButtonClick btn >>= \f ->
let n' = f n in
setLabel lab (show n') >>
count n'
in
count startcounter defines the user interface. It
returns a display handle, and handles to the label and a
combination of the two buttons, created by
This combination has the desirable property that a call tocombineButtons :: [Button a] -> IO (Button a)
getButtonClick waits for any of the push buttons
to be clicked.
In main, the counter function is passed to wopen,
wopen :: [String] -> (DC -> IO (a,DisplayHandle))
-> IO (a,Window)wopen can contain default values for the
display context. The example indicates that the format for
these values are similar to the resource data base in X
[SG86]. In the example, it is used to set the window
title. The application handles in counter are returned
as they are from wopen, which also returns a window
handle which can be used to manipulate the shell window.
The rest of main defines the application behaviour of
the program by defining a loop which waits for button clicks,
and then updates the label. In this example, the loop comes
right after the initialisation of the interface in the main
process, but in general, control loops are spawned as separate
processes.
Events from the X server and control messages between widgets are distributed in streams (coded as CML event values) through the window hierarchy, where each window has at least one CML thread taking care of the events. Drawing is done by calling imperative drawing procedures. High-level events are reported either imperatively or by message passing: when a button is pressed, a callback routine is called, or a message is output on a CML channel.
TkGofer was further developed and improved in [CVM97], by using Gofer's expressive class system to provide a typed means of specifying parameters for the widgets, similar to the dynamically customisable fudgets in Section 30.3. The result is that most dynamic aspects of the Tk widgets can be controlled in a type-safe way. For example, the button widget has type
and since the typebutton :: [Conf Button] -> Window -> GUI Button
Button is instance of both
HasText and HasCommand, its label and callback
function can be configured with the following members:
An up/down counter written with Gofer's do-notation (syntactic sugar for monads) is found in Figure 108.text :: HasText a => String -> Conf a command :: HasCommand a => GUI () -> Conf a
counter :: IO () counter = start $ do w <- window [title "Up/Down Counter"] e <- entry [initValue 0, readOnly True] w let my_button t f = button [text t, command (modifyEntry e f)] w u <- my_button "Up" (+1) d <- my_button "Down" (+(-1)) pack (u ^-^ e ^-^ d) modifyEntry :: Entry Int -> (Int -> Int) -> GUI () modifyEntry e f = do x <- getValue e setValue e (f x)Figure 108. The TkGofer counter.
I/O in Clean is carried out using the world-as-value paradigm [Ach96], which means that an abstract value, representing the state of the world (or parts of it), is passed around as an extra parameter in the program. The type system is extended with a mechanism to guarantee that the world parameters are passed in a single-threaded way throughout the program. It is this parameter threading that specifies the order in which I/O operations are performed; no explicit sequencing combinator is used in the world-as-value style. However, Clean programs have a syntactic abbreviation for nested let expressions, which is used when specifying sequences statements. Using this style, the monadic definition
f =
do x1 <- c1
x2 <- c2
...
return e
f
# (x1,s) = c1 s
(x2,s) = c2 s
...
= (e,s)IO monad in Section 41.1.3. A
disadvantage is that state and error handling becomes
explicit, something which clutters the programs. On the other
hand, different kinds of state parameters can be
handled--possibly simultaneously--without the need of
defining new combinators.
A Clean version of the up/down counter is shown in
Figure 109. The first lines in Figure 109. Up/down counter in Clean.initcounter
show the use of the nested-let sugar, and allocate unique
identifiers to be used in the data structure dialog,
which specifies the GUI. This data structure also relates the
callback function upd to the push buttons, and the
initial local state.
:: NoState = NoState
Start :: *World -> *World
Start world = startIO NoState NoState [initcounter] [] world
where
initcounter ps
# (windowid, ps) = accPIO openId ps
(displayid, ps) = accPIO openId ps
(_,ps) = openDialog NoState (dialog windowid displayid) ps
= ps
where
dialog windowId displayId
= Dialog "Counter"
{ newLS = init
, newDef = EditControl (toString init) dwidth dheight
[ ControlPos (Center,zero)
, ControlId displayId
, ControlSelectState Unable
]
:+: ButtonControl "-"
[ ControlPos (Center,zero)
, ControlFunction (upd (-1))
]
:+: ButtonControl "+"
[ ControlFunction (upd 1)
]
}
[ WindowClose (noLS closeProcess)
, WindowId windowId
]
where
dwidth = 200
dheight = 1
init = 0
upd :: Int (Int,PSt .l .p) -> (Int,PSt .l .p)
upd dx (n,ps) =
(n1,appPIO (setWindow
windowId
[setControlTexts [(displayId,toString n1)]]) ps)
where n1 = n+dx
Pictures are described in the PostScript model
[Ado90] for graphics. A picture can made sensitive
to input by associating it with a handler. The handler is
called if an input event, such as a mouse button press, occurs
while the mouse pointer is over the screen area covered by the
picture. The handler returns a value of type IO ()
and can thus have arbitrary I/O effects, including changing a
mutable variable that the picture depends on.
Pidgets is based on an imperative approach to dynamically changing
graphical objects. Monads are used to provide a purely
functional interface to the imperative machinery. Mutable
variables are made part of the I/O monad. A new monad
Expr is defined for expressions (that is, values whose
interdependencies are described by a directed acyclic graph)
that can depend on the values of mutable variables.
In part, the purpose of Pidgets is similar to that of the fudget
graphicsF discussed in Chapter 27. An interesting
experiment would be to see how Pidgets could be used to
implement combinators for syntax directed editors.
The reactivity is achieved by combinators that allow a behaviour to be replaced by another at the occurrence of an event. There are also combinators for building complex behaviours and events from simpler ones. The behaviour combinators can be seen as parallel composition of processes, allowing a number of behaviours to act concurrently.
The primary goal for Fran is to specify multimedia and animation, which it does in an elegant and declarative way. It might be possible to use Fran for building complete GUI toolkits as well.
Frame, which is
used to construct top-level windows. The constructor method
UpDown creates two button objects and a label object,
and adds so called action listeners (high-level event
handlers) to the buttons, as anonymous classes. These play the
role of callbacks, and modify the counter variable and the
display.
The last lines in the constructor method defines the layout
and adds the buttons to the frame. Figure 110. Up/down counter in Java.
public class UpDown extends Frame {
private int count = 0;
public UpDown() {
final Label display = new Label();
display.setText(""+count);
Button up = new Button("Up");
up.addActionListener(
new ActionListener() {
public void actionPerformed(ActionEvent e) {
display.setText(""+ ++count);
}
});
Button down = new Button("Down");
down.addActionListener(
new ActionListener() {
public void actionPerformed(ActionEvent e) {
display.setText(""+ --count);
}
});
setLayout(new FlowLayout());
add(up);
add(display);
add(down);
}
public static void main(String args[]) {
UpDown a = new UpDown();
a.setTitle("Up/Down Counter");
a.pack();
a.show();
}
}
PizzaButton and a PizzaLabel. The PizzaButton
is a Button where we define the action as a callback
function directly in the constructor:
class PizzaButton extends Button {
public PizzaButton(String s, final () -> void action) {
super(s);
addActionListener(
new ActionListener() {
public void actionPerformed(ActionEvent e) {
action();
}
});
}
}PizzaLabel is a polymorphic Label with methods
for getting or setting the value, and applying a function to
it.
class PizzaLabel<T> extends Label {
private T value;
public PizzaLabel(T i) { super("" + i);
value = i; }
public T get() { return value; }
public void set(T i) { value = i;
setText("" + i); }
public void modify((T) -> T f) { set(f(value)); }
}
public class UpDown extends Frame { public UpDown() { PizzaLabel<int> display = new PizzaLabel(0); Button up = new PizzaButton("Up", fun() -> void { display.modify(fun(int x)->int { return x+1; }); }); Button down = new PizzaButton("Down", fun() -> void { display.modify(fun(int x)->int { return x-1; }); }); setLayout(new FlowLayout()); add(up); add(display); add(down); } public static void main(String args[]) { UpDown a = new UpDown(); a.setTitle("Up/Down Counter"); a.pack(); a.show(); } }Figure 111. The Pizza up/down counter.
The program starts with creating a shell widget called
#include <stdio.h> #include <X11/Intrinsic.h> #include <X11/StringDefs.h> #include <Xm/Xm.h> #include <Xm/Label.h> #include <Xm/PushB.h> #include <Xm/RowColumn.h> static int count = 0; static void SetDisplay(Widget display, int i) { char s[10]; Arg wargs[1]; int n = 0; sprintf(s, "%d", i); XtSetArg(wargs[n], XmNlabelString, XmStringCreate(s, XmSTRING_DEFAULT_CHARSET)); n++; XtSetValues(display, wargs, n); } static void increment(Widget b, Widget display, XtPointer call_data) { count++; SetDisplay(display, count); } int main(int argc, char *argv[]) { Widget top, row, display, button; top = XtInitialize("counter", "Counter", NULL, 0, &argc, argv); row = XtCreateManagedWidget("row", xmRowColumnWidgetClass, top, NULL, 0); display= XtCreateManagedWidget("display", xmLabelWidgetClass, row, NULL, 0); button = XtCreateManagedWidget("button", xmPushButtonWidgetClass, row, NULL, 0); SetDisplay(display, count); XtAddCallback(button, XmNactivateCallback, (XtCallbackProc)increment, (XtPointer)display); XtRealizeWidget(top); XtMainLoop(); /* does not return */ }Figure 112. The up/down counter in C and Motif.
top, which will be the root of the widget tree. The rest
of the tree is created with repeated calls of
XtCreateManagedWidget, where the arguments specify what
kind of widget to create, and where to put it in the tree. The
widgets are:row, a layout widget which put all its children in
a row or in a column.display, which shows a string which will be the count.button, a button that the user can press. Whenever
this happens, an associated callback routine is called.increment is registered as a
callback routine for the button widget. increment
increments the counter and updates the display widget.With the stream processors defined here, we abstract away from the streams. We define a number of combinators for stream processors, but no operations on the streams themselves. We have considered a number of different implementations of stream processors, some of which are deterministic and work in a pure, sequential functional language without any extensions, and some of which take advantage of parallel evaluation and indeterministic choice (Chapter 20).
We have also presented a library of combinators for constructing
applications with graphical user interfaces
(Part II) and typed network communication
(Chapter 26). Together with a range of applications,
the library has demonstrated that the stream-processor/fudget
concept is scalable; it can be used to program not only toy
examples, but more complex applications, like WWW-browsers
(Chapter 32) and syntax-oriented proof editors
(Chapter 33). A key combinator here is loopThroughRightSP
(Section 18.2), which allows existing stream
processors/fudgets to be reused in a style that resembles
inheritance in object-oriented programming.
The library also demonstrates that pure functional programming languages are suitable for these tasks, something which was not clear when this work started. Although GUI fudget programs do a fair amount of I/O, response times can be kept sufficiently low (Section 27.5.3).
Since we represent I/O effects by data constructors sent as messages, we have been able to write higher order functions that manipulate I/O effects of fudgets (Chapter 24), which provide a possibility for modifying the behaviour of existing fudgets. A caching mechanism (Section 24.1) and a click-to-type input model (Section 24.2) has been implemented with this method.
The default parameter mechanism (Chapter 15 and 30) demonstrates how Haskell's class system and higher order functions can be combined to simulate a missing language feature. Later, two other GUI libraries, Gadgets (Section 41.3.1) and TkGofer (Section 41.4), have adopted this mechanism.
The fudget graphicsF in Chapter 27 shows that the task of
displaying and manipulating graphics can be handled efficiently in
a purely functional way. It has been used both in the web browser
in Chapter 32, and in the proof editor Alfa in
Chapter 33. On top of graphicsF, we have also implemented
a set of combinators that allow syntax-oriented editors to be
built in a high-level style, resembling combinator parsers
(Chapter 28). Our experience with these combinators is
limited sofar, but we believe that they can be employed in a
future version of Alfa.
Although most stream processors we have shown are programmed in a
CPS style, other styles can be used. Simple stream processors can
be programmed by using concatMapAccumlSP and a state
transition function. A monadic style can also be used, as is
demonstrated in Chapter 31.
As the related work shows in Chapter 41, a number of elegant libraries and interfaces have emerged for GUI programming in pure functional languages during the last years. Is it possible to evaluate and compare all these libraries and the Fudget library? This has been done to some extent in the review in [Nob95]. We will not give any further comparison here, but simply point out some distinguishing features of fudgets and stream processors in general:
The fudget concept has been implemented on top of a number of GUI toolkits [Nob95][Tay96][RS93][CVM97], something which also gives evidence that fudgets are easy to implement.
somF in (Section 28.4, Figure 81), which has a
stream processor handling three output and three input
streams. An extreme example is the top-level fudget of Alfa
(Chapter 33), whose controlling stream processor defines 15
routing functions, to handle five levels deep messages of
Either type. By using routing functions defined in one
place, adding new subfudgets to the top-level fudget has become a
manageable task. It still requires a bit too much of mechanical
work and there is a need for some new set of combinators or
some other solution to simplify this programming task further.
One could argue that the combinator plumbing of messages imposes a degree of structure on programs which could be healthy. Having explicit identifiers for streams spread over a program results easily in a goto-like spaghetti. The functional language FP by John Backus [Bac78] is entirely based on the use of combinators instead of named variables.
As shown in the Chapter 25, the migration mechanism can be applied to fudgets and used to implement drag-and-drop of GUI fudgets.
How important was lazy evaluation in Fudgets library and programming? Could Fudgets be implemented in ML?When the work on Fudgets started, Haskell used the stream-based I/O model and stream processes were represented as list functions. Nowadays, the continuation-based representation of stream processors is used and Haskell has switched to a monadic I/O system, both of which would work in a strict language. So, lazy evaluation is no longer essential.
A problem with stream-based I/O is the danger of getting ``out of synch'' and reading one result too many or too few. Did this happen to you in practice?For a while, when we used the list based representation and that representation was visible to the programmer, the programmer had to be aware of the ``fudget law'', that is, the one-to-one correspondence between input and output messages (see Section 20.4.1). We sometimes made mistakes. When the stream processor type was made abstract, the fudget law became built-in and the programmer was relieved from thinking of it. Also, we started doing low level I/O through functions like
doStreamIOK (Section 21.4), which effectively
removed all problems of this kind.Haskell has moved from stream-style I/O to monad-style I/O. Your operations are CPS-style, but they could equally be monad style. Did you make that choice consciously? Why?The monadic programming style had not become popular when we introduced the CPS style combinators, so we did not make a conscious choice between CPS style and monadic style.
Did you come across any situations where Haskell's type system prevented you doing the Right Thing?Yes. For example, the type
XCommand is supposed be
an interface to X Windows, but we have added various ``pseudo
commands'' that are handled within the Haskell program and never
output to the window system. It would have been nice to define
the proper commands as a subtype of all commands. Making this
distinction in Haskell would require an extra level of tagging,
which we felt was not justified. Analogously, the type
XEvent contains some ``pseudo events''.
When using the implementation from the Fudget library,p :: SP (Either a b) (Either a b) p = idSP -+- idSP
p
is nothing but the identity stream processor for type
Either a b. But if we were to use
indeterministic stream processors, we cannot be sure that
message order would be maintained through p. If we first
send Left a immediately followed by Right
b to p, why should there be a guarantee that it
will output these messages in the same order?
Naturally, the Fudget library does not have a lot of identity
stream processors in parallel. Fudgets, on the other side, are
abundant in the library, and they very often sit in
parallel. One example where implicit assumptions exist about
message order output from parallel fudgets is in the radio group
fudget radioF. Another, more explicit, assumption was
made in the implementation of the Explode game in
Section 38.1.1. In Explode, it is crucial that the
internal communication after a explosion has priority over
external communication. This is what the continuation-based
implementation of stream processors gives.
In order to reason formally about indeterministic stream processors, we present the stream-processor calculus (SP-calculus).
For the reader who has used stream processors in the Fudget library, these operators should be familiar. The operator ! correspond to
x (Variable) s ! t (Put) x ? s (Get) s <· t (Feed) s << t (Serial composition) s +t(Parallel composition) l s (Loop)
putSP, and ? can be
seen as a combination of abstraction and getSP: x ? s is
the same as getSP (\x -> s). The feed operator in
s <· t feeds the message t to the stream processor s
(similar to startupSP, which feeds a list of messages to a
stream processor). Serial composition corresponds to
-==-, and parallel composition and loop are untagged,
corresponding to -*- and loopSP.
s +t=== t +s(Commutativity of +)(s +t)+u=== s +(t+u)(Associativity of +)(s << t) << u === s << (t << u) (Associativity of <<) s << (t ! u) === (s <· t) << u (Internal communication in <<) (s +t) <· u=== (s <· u) +(t <· u)(Distributivity of <· over +)(s ! t) <· u === s ! (t <· u) (Output from <·) (s ! t) << u === s ! (t << u) (Output from <<) (x ? s) <· t === s[t/x] (Substitution)
We can derive a symmetric rule by using the commutativity of
(s ! t) +u--> s ! (t +u)((Output from +))
+, but when it comes to the loop, we need two rules.As an example of these rules, consider the stream processor (s ! t)
l (s ! t) --> s ! l (t <· s) (Internal input to l) (l s) <· t --> l (s <· t) (External input to l)
+ (u ! v), which can react to s ! (t + (u ! v)), but also
to u ! ((s ! t) + v), using commutativity. Similarly, the loop
(l (s ! t)) <· u can react to both s ! l (t <· s) <· u
and l (s ! t <· u).The substitution rule for the SP-calculus correspond to the beta-rule of \-calculus. However the eta-rule, which would correspond to x ? (s <· x) === s, does not hold in general, something that we will see after having defined equivalence of stream processors.
[[x]] = x (Variable) [[\x.M]] = x ? [[M]] (Abstraction) [[M N]] = [[M]] <· [[N]] (Application)
Having the power of \-calculus, we can define some familiar stream processors, such as the identity stream processor and the null stream processor.
fix = f ? (x ? f <· (x <· x)) <· (x ? f <· (x <· x)) id = fix <· (f ? x ? x ! f) 0 = fix <· (f ? x ? f)
s1 === s2 if and only if:
There is also an interest in having programs running for a while at one site, then moving on to other sites, while gathering information etc. Such programs are often called mobile agents. As we have seen in Chapter 25, the necessary machinery for mobile agent programming is already there in the stream-processor concept. However, we need support in the underlying language implementation so that values that are closures can be exchanged between computers.
On the home page you can find out how to download fudgets and install them, what Haskell compiler to use and where to get it, what platforms are supported. You can also browse and search the Fudget Library Reference Manual.http://www.altocumulus.org/Fudgets
The Fudget library is available in precompiled form for some of the above mentioned platforms. The library is also available in source form.
To compile the Fudget library (in case you can not use a precompiled distribution) and fudget applications, you need a Haskell compiler. The current version of the library works only with HBC [Aug97], since the library makes use of existential types, which is an extension of Haskell currently supported only by HBC, as far as we know. Earlier versions of the library work with NHC and GHC as well.
The Fudget library and HBC are available for download from
Read theftp://ftp.cs.chalmers.se/pub/haskell/chalmers
README files and, if you get the precompiled
version of the Fudget library, make sure that you get
matching versions of the compiler and the library.
Hello.hs, the command line to
compile the program is
Even if the program consists of several modules, invokinghbcxmake Hello
hbcxmake with the name of the main module is enough to
compile it. hbcxmake calls hbcmake, an
automatic make utility supplied with HBC.A more complete description of the contents of the Fudget library is provided in the reference manual, which is available on-line via
http://www.altocumulus.org/Fudgets/Manual/
fudlogue :: F a b -> IO (), shellF :: String -> F a b -> F a b, labelF :: (Graphic a) => a -> F b c, quitButtonF :: F Click a, intInputF :: F Int Int, intDispF :: F Int a, buttonF :: (Graphic a) => a -> F Click Click, >==< :: F a b -> F c a -> F c b, >+< :: F a b -> F c d -> F (Either a c) (Either b d), listF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c), loopThroughRightF :: F (Either a b) (Either c d) -> F c a -> F b d, mapF :: (a -> b) -> F a b, mapstateF :: (a -> b -> (a, [c])) -> a -> F b c, labLeftOfF :: (Graphic a) => a -> F b c -> F b c, placerF :: Placer -> F a b -> F a b, verticalP :: Placer, revP :: Placer -> Placer, matrixP :: Int -> Placer, holeF :: F a b, filledTriangleUp :: FlexibleDrawing, filledTriangleDown :: FlexibleDrawing, -*- :: SP a b -> SP a b -> SP a b
-+- :: SP a b -> SP c d -> SP (Either a c) (Either b d)
-==- :: SP a b -> SP c a -> SP c b
>+< :: F a b -> F c d -> F (Either a c) (Either b d)
>==< :: F a b -> F c a -> F c b
>=^< :: F a b -> (c -> a) -> F c b
>=^^< :: F a b -> SP c a -> F c b
>^=< :: (a -> b) -> F c a -> F c b
>^^=< :: SP a b -> F c a -> F c b
aLeft :: Alignment
aTop :: Alignment
absF :: SP a b -> F a b
argKey :: [Char] -> [Char] -> [Char]
argReadKey :: (Read a, Show a) => [Char] -> a -> a
args :: [[Char]]
atomicD :: a -> Drawing b a
bgColor :: [Char]
bindSPm :: SPm a b c -> (c -> SPm a b d) -> SPm a b d
border3dF :: Bool -> Int -> F a b -> F (Either Bool a) b
bottomS :: Spacer
boxD :: [Drawing a b] -> Drawing a b
buttonBorderF :: Int -> F a b -> F (Either Bool a) b
buttonF :: (Graphic a) => a -> F Click Click
buttonF' :: (Graphic a) => Customiser (ButtonF a) -> a -> F Click Click
buttonF'' :: (Graphic a) => Customiser (ButtonF a) -> a -> PF (ButtonF a) Click Click
buttonGroupF :: [(ModState, KeySym)] -> F (Either BMevents a) b -> F a b
bypassF :: F a a -> F a a
centerS :: Spacer
colorSpec :: (Show a, ColorGen a) => a -> ColorSpec
compS :: Spacer -> Spacer -> Spacer
concatMapAccumlSP :: (a -> b -> (a, [c])) -> a -> SP b c
concatMapF :: (a -> [b]) -> F a b
concatMapSP :: (a -> [b]) -> SP a b
concatSP :: SP [a] a
defaultFont :: FontName
deletePart :: Drawing a b -> [Int] -> Drawing a b
displayF :: (Graphic a) => F a b
displayF' :: (Graphic a) => Customiser (DisplayF a) -> F a b
drawingPart :: Drawing a b -> DPath -> Drawing a b
dynF :: F a b -> F (Either (F a b) a) b
dynListF :: F (Int, DynFMsg a b) (Int, b)
editorF :: F EditCmd EditEvt
fgD :: (Show a, ColorGen a) => a -> Drawing b c -> Drawing b c
filler :: Bool -> Bool -> Int -> FlexibleDrawing
filterLeftSP :: SP (Either a b) a
filterRightSP :: SP (Either a b) b
filterSP :: (a -> Bool) -> SP a a
flipP :: Placer -> Placer
flipS :: Spacer -> Spacer
fontD :: (Show a, FontGen a) => a -> Drawing b c -> Drawing b c
fontSpec :: (Show a, FontGen a) => a -> FontSpec
font_ascent :: FontStruct -> Int
font_descent :: FontStruct -> Int
frame' :: Size -> FlexibleDrawing
fudlogue :: F a b -> IO ()
g :: (Graphic a) => a -> Drawing b Gfx
getSP :: Cont (SP a b) a
getSPm :: SPm a b a
getSPms :: SPms a b c a
groupF :: [XCommand] -> K a b -> F c d -> F (Either a c) (Either b d)
hAlignS :: Alignment -> Spacer
hCenterS :: Spacer
hFiller :: Int -> FlexibleDrawing
hMarginS :: Distance -> Distance -> Spacer
hScrollF :: F a b -> F a b
hboxD :: [Drawing a b] -> Drawing a b
hboxD' :: Distance -> [Drawing a b] -> Drawing a b
holeF :: F a b
horizontalP :: Placer
hyperGraphicsF :: (Eq a, Graphic b) => Drawing a b -> F (Either (Drawing a b) (a, Drawing a b)) a
idF :: F a a
idLeftF :: F a b -> F (Either c a) (Either c b)
idRightF :: F a b -> F (Either a c) (Either b c)
idSP :: SP a a
inputDoneSP :: SP (InputMsg a) a
inputLeaveDoneSP :: SP (InputMsg a) a
inputLinesSP :: SP [Char] [Char]
intDispF :: F Int a
intF :: F Int (InputMsg Int)
intInputF :: F Int Int
isLeft :: Either a b -> Bool
issubset :: (Eq a) => [a] -> [a] -> Bool
labAboveF :: (Graphic a) => a -> F b c -> F b c
labLeftOfF :: (Graphic a) => a -> F b c -> F b c
labelD :: a -> Drawing a b -> Drawing a b
labelF :: (Graphic a) => a -> F b c
leftS :: Spacer
linesSP :: SP Char [Char]
listF :: (Eq a) => [(a, F b c)] -> F (a, b) (a, c)
loadSPms :: SPms a b c c
loop :: (a -> a) -> a
loopCompF :: F (Either (Either a b) (Either c d)) (Either (Either c e) (Either a f)) -> F (Either b d) (Either e f)
loopCompThroughLeftF :: F (Either a (Either b c)) (Either b (Either a d)) -> F c d
loopCompThroughRightF :: F (Either (Either a b) c) (Either (Either c d) a) -> F b d
loopF :: F a a -> F a a
loopLeftF :: F (Either a b) (Either a c) -> F b c
loopLeftSP :: SP (Either a b) (Either a c) -> SP b c
loopSP :: SP a a -> SP a a
loopThroughRightF :: F (Either a b) (Either c d) -> F c a -> F b d
loopThroughRightSP :: SP (Either a b) (Either c d) -> SP c a -> SP b d
mapAccumlSP :: (a -> b -> (a, c)) -> a -> SP b c
mapF :: (a -> b) -> F a b
mapFilterSP :: (a -> Maybe b) -> SP a b
mapLabelDrawing :: (a -> b) -> Drawing a c -> Drawing b c
mapPair :: (a -> b, c -> d) -> (a, c) -> (b, d)
mapSP :: (a -> b) -> SP a b
mapstateF :: (a -> b -> (a, [c])) -> a -> F b c
mapstateSP :: (a -> b -> (a, [c])) -> a -> SP b c
marginS :: Distance -> Spacer
matrixP :: Int -> Placer
maybeDrawingPart :: Drawing a b -> DPath -> Maybe (Drawing a b)
menuF :: (Graphic a, Graphic c) => a -> [(b, c)] -> F b b
moreF :: F [String] (InputMsg (Int, String))
moreFileF :: F String (InputMsg (Int, String))
moreFileShellF :: F String (InputMsg (Int, String))
moveDrawCommands :: (Functor a) => aDrawCommand -> Point -> aDrawCommand
nullF :: F a b
nullK :: K a b
nullSP :: SP a b
nullSPm :: SPm a b ()
nullSPms :: SPms a b c ()
origin :: Point
overlayP :: Placer
part :: (a -> Bool) -> [a] -> ([a], [a])
path :: Path -> (Direction, Path)
pickListF :: (a -> String) -> F (PickListRequest a) (InputMsg (Int, a))
placedD :: Placer -> Drawing a b -> Drawing a b
placerF :: Placer -> F a b -> F a b
popupMenuF :: (Graphic b, Eq b) => [(a, b)] -> F c d -> F (Either [(a, b)] c) (Either a d)
putSP :: a -> SP b a -> SP b a
putSPm :: a -> SPm b a ()
putSPms :: a -> SPms b a c ()
quitButtonF :: F Click a
radioGroupF :: (Graphic b, Eq a) => [(a, b)] -> a -> F a a
radioGroupF' :: (Graphic b, Eq a) => Customiser RadioGroupF -> [(a, b)] -> a -> F a a
readDirF :: F String (String, Either D_IOError [String])
readFileF :: F String (String, Either D_IOError String)
rectpos :: Rect -> Point
rectsize :: Rect -> Size
remove :: (Eq a) => a -> [a] -> [a]
replace :: (Eq a) => (a, b) -> [(a, b)] -> [(a, b)]
replaceAll :: [a] -> TextRequest a
revP :: Placer -> Placer
rightS :: Spacer
rootGCtx :: GCtx
runSP :: SP a b -> [a] -> [b]
scrollF :: F a b -> F a b
serCompLeftToRightF :: F (Either a b) (Either b c) -> F a c
serCompRightToLeftF :: F (Either a b) (Either c a) -> F b c
serCompSP :: SP a b -> SP c a -> SP c b
setBgColor :: (HasBgColorSpec b, Show a, ColorGen a) => a -> Customiser b
setLabel :: a -> Customiser (ButtonF a)
setPlacer :: Placer -> Customiser RadioGroupF
shellF :: String -> F a b -> F a b
simpleGroupF :: [WindowAttributes] -> F a b -> F a b
splitSP :: SP (a, b) (Either a b)
standard :: Customiser a
startupF :: [a] -> F a b -> F a b
startupSP :: [a] -> SP a b -> SP a b
stderrF :: F String a
stdinF :: F a String
stdoutF :: F String a
storeSPms :: a -> SPms b c a ()
stringF :: F String (InputMsg String)
stringInputF :: F String String
string_rect :: FontStruct -> [Char] -> Rect
stripEither :: Either a a -> a
stripInputSP :: SP (InputMsg a) a
stripLeft :: Either a b -> Maybe a
stripLow :: Message a b -> Maybe a
stripRight :: Either a b -> Maybe b
throughF :: F a b -> F a (Either b a)
timerF :: F (Maybe (Int, Int)) Tick
toBothF :: F a (Either a a)
toggleButtonF :: (Graphic a) => a -> F Bool Bool
topS :: Spacer
unitSPm :: a -> SPm b c a
up :: DPath -> DPath
updatePart :: Drawing a b -> DPath -> (Drawing a b -> Drawing a b) -> Drawing a b
vAlignS :: Alignment -> Spacer
vCenterS :: Spacer
vFiller :: Int -> FlexibleDrawing
vMarginS :: Distance -> Distance -> Spacer
vScrollF :: F a b -> F a b
verticalP :: Placer
wCreateGCtx :: (Show b, FontGen b, FudgetIO e, Show a, ColorGen a) => GCtx -> [GCAttributes a b] -> (GCtx -> ecd) -> ecd
waitForSP :: (a -> Maybe b) -> (b -> SP a c) -> SP a c
writeFileF :: F (String, String) (String, Either D_IOError ())
xcoord :: Point -> Int
ycoord :: Point -> Int