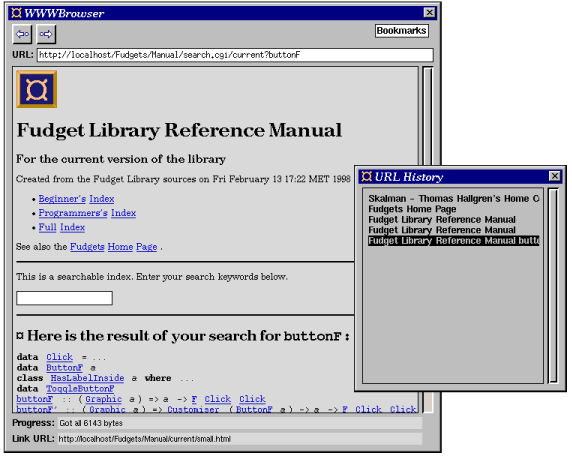
 |
Figure 85. WWWbrowser, a simple web browser implemented using fudgets in 1994. It supports inlined images and forms.
In this section we will take a look at how such an application can be implemented on top of the Fudget library, in Haskell. An actual implementation, called WWWBrowser, was done mainly during the summer 1994. Some updates and improvements were made in the summer 1997. A window snapshot is shown in Figure 85.
Figure 85. WWWbrowser, a simple web browser implemented using fudgets in 1994. It supports inlined images and forms.
The 1994 version of WWWBrowser had the following features:
Drawing
(see Section 27.4), using a function of the type
Html -> Drawing ... (roughly).
The old tailor made fudget kernels were thrown
out. The fudget library placer tableP was be used to add
support for tables (the table cell attributes rowspan and
colspan were not supported yet).URL and Html. The key operations on these types are:
Documents are fetched from their location on the web by the fudgetdata URL = ... data Html = ... parseURL :: String -> Maybe URL showURL :: URL -> String joinURL :: URL -> URL -> URL parseHtml :: String -> Either ErrorInfo Html drawHtmlDoc :: URL -> Html -> HtmlDrawing type HtmlDrawing = Drawing ... -- details in Section 32.3
urlFetchF,
The fudgeturlFetchF :: F HttpRequest HttpResponse -- details in Section 32.2 data HttpRequest = HttpReq { reqURL::URL, ... } data HttpResponse = HttpResp { respBody::String, ... }
urlFetchF handles several protocol besides the
HTTP protocol, but since HTTP is the primary protocol on the
WWW, it was the one that was implemented first. The fudgets
for other protocols were then implemented with the same interface.
Documents are displayed by the fudget htmlDisplayF,
which displays HTML documents received on the input, and outputs requests for new documents when the user clicks on links in the document being displayed.htmlDisplayF :: F (URL,Html) HttpRequest
Not all documents on the WWW are HTML documents. Other types of documents (for example plain text, gopher pages, ftp directory listings and Usenet news articles) are handled by converting them to HTML:
The functiontoHtml :: (URL, HttpResponse) -> (URL,Html)
toHtml uses parseHtml and other
parsers.
Using the components presented above we can create a simple web browser by something like
But in addition to the HTML display, WWWBrowser provides back/forward buttons, an URL-entry field, a history window, a bookmarks menu, a document source window and a progress report field. The structure of the main fudget is shown in Figure 86. The layout is specified using name layout (see Section 11.2).simpleWebBrowser = loopF (htmlDisplayF >==< mapF toHtml >==< urlFetchF)
wwwBrowserF = httpMsgDispF >==< loopThroughRightF urlFetchF' mainGuiF >==< menusF where mainGuiF = urlInputF >*< srcDispF >*< (urlHistoryF >*< htmlDisplayF) >=^< toHtml httpMsgDispF = nameF "MsgDisp" $ "Progress:" `labLeftOfF` displayF urlFetchF' = post >^=< urlFetchF >=^< stripEither where post msg = ... urlInputF = ... parseURL ... stringInputF ... showURL ... srcDispF = ... urlHistoryF = ...Figure 86.
wwwBrowserF-- the main fudget in WWWBrowser.
urlFetchF is implemented as a parallel
composition of fudgets handling the different protocols. This is
shown in Figure 87. The function distr extracts
the protocol field from the request URL and sends the request to
the appropriate subfudget.
urlFetchF :: F HttpRequest HttpResponse urlFetchF = snd >^=< listF fetchers >=^< distr where fetchers = [("file",fileFetchF>=^<reqURL), -- local files and ftp ("http",httpFetchF), -- http and gopher requests ("news",newsFetchF>=^<reqURL), ("telnet",telnetStarterF>=^<reqURL) ] distr req@(HttpReq {reqURL=url}) = (fetcher,req) where fetcher = ...Figure 87. The fudget
urlFetchF.
The implementation of the individual protocol fudget kernels are written in continuation style. For the http protocol, the following operations are performed:
The FTP protocol can also handle several requests per connection, and since you are required to log in before you can transfer files, it is even more beneficial to reuse connections.
The FTP protocol differs in that it uses a control connection for sending commands that initiate file transfers and a separate data connection for each file transfer. The data connection is normally initiated by the server, to a socket specified by the client. In the fudget implementation, these two connections are handled by two separate, but cooperating, fudgets.
is an element tagged as a top-level heading, and it has a nested element marked to be displayed with a typewriter font.<H1>The fudget <TT>htmlDisplayF</TT></H1>
There is a distinction between block-level elements and text-level elements. The former mark up text blocks that are to be treated as complete paragraphs. They are thus composed vertically. Heading elements are examples of block-level elements. The latter mark up arbitrary sequences of characters within a paragraph. Block-level elements can contain text-level elements (as in the example above), but not vice versa.
WWWBrowser makes use of the distinction between block-level and
text-level elements. This makes it easier to do the layout.
The function parseHtml builds a syntax tree which on the
top level is a sequence of block-level elements. Plain text
occuring on the top level, outside any block-level element,
is understood as occuring inside an implicit paragraph ( <P>) element. So, for example,
is parsed into the same syntax tree as as<H1>The fudget <TT>htmlDisplayF</TT></H1> The implementation of...
With this approach, the function<H1>The fudget <TT>htmlDisplayF</TT></H1> <P>The implementation of...</P>
drawHtmlDoc can simply recurse down the syntax tree, composing
the drawings of block-level elements using verticalP and
text-level elements using paragraphP.
Web pages contain not only text, but also images and form
elements. In WWWBrowser, these are implemented by embedding
fudgets in the drawing. We introduce the type ActiveDrawing for drawings containing active components and
define the type HtmlDrawing introduced above as
wheretype HtmlDrawing = ActiveDrawing HtmlLabel Gfx HtmlInput HtmlOutput type ActiveDrawing lbl leaf i o = Drawing lbl (Either (F i o) leaf)
HtmlInput and HtmlOutput are the message types
used by the fudgets implementing images and forms. Elements with
special functionality are marked with a label of type HtmlLabel. Currently, hyperlinks, link targets, forms and
image maps are labelled.
To display ActiveDrawings, a generalisation of graphicsF (see Section 27.5.1) has been defined:
activeGraphicsF ::
F (Either (GfxCommand (ActiveDrawing lbl leaf i o)) (Int,i))
(Either GfxEvent (Int,o))htmlDisplayF uses activeGraphicsF to display
HTML documents. It also containsHttpRequest when the submit button of a form is pressed.imageFetchF (described below)
that the image fudgets communicate with to obtain the images
they should display. htmlDisplayF uses the fudget imageFetchF for this:
The requests handled byimageFetchF :: F ImageReq (ImageReq,ImageResp) type ImageReq = (URL,Maybe Size) type ImageResp = (Size,PixmapId)
imageFetchF contain the URL of
an image to fetch and an optional desired size to which the
image should be scaled. The responses contain the actual size
(after scaling) and a pixmap identifier.
Since documents may contain many images and the time it takes
to fetch an image often is dominated by network latency
rather than bandwidth limitations, it makes sense to fetch
several images in parallel. The fudget parServerF,
is a generic fudget for creating servers that can handle several requests in parallel. If serverF is a fudget that handles requests sequentially with a 1-1 correspondence between requests and responses, then the fudgetparServerF :: Int -> F req resp -> F req resp
parServerF n serverF handles up to n requests in
parallel.
Clients of parServerF must have some way of
telling which response belongs to which request, since the
order in which the responses are delivered is not guaranteed to
correspond to the order in which the requests are received. The fudget
imageFetchF accomplishes this by including the requests
in the responses.
We also want to avoid fetching the same image twice. This is solved by using a caching fudget,
cacheF :: Eq req => F req (req,resp) ->
F (client,req) (client,(req,resp))htmlDisplayF,
since it is common for the same image to occur in several places
in the same HTML document.)
In WWWBrowser, a composition like this is used to fetch images:
The implementation ofcacheF (parServerF 5 imageFetchF)
parServerF is shown in
Figure 88. The implementation of cacheF is shown
in Figure 89.
parServerF :: Int -> F req resp -> F req resp parServerF n serverF = loopThroughRightF (absF ctrlSP0) serversF where serversF = listF [(i,serverF) | i<-ns] -- n parallel servers ns = [1..n] -- server numbers ctrlSP0 = ctrlSP ns -- The argument to ctrlSP is a list of currently free servers ctrlSP servers = case servers of -- If all servers are busy, wait for a response. [] -> getLeftSP $ fromServer -- If there is a free server: s:servers' -> getSP $ either fromServer fromClient where fromClient req = -- When a requests is received, send it to the -- first server in the free list and continue -- with the remaning servers still in the free list. putSP (Left (s,req)) $ ctrlSP servers' where fromServer (n,resp) = -- When a response is received from a server -- output it and add the server to the free list. putSP (Right resp) $ ctrlSP (n:servers)Figure 88. The fudget
parServerF.
cacheF :: Eq req => F req (req,resp) -> F (client,req) (client,(req,resp)) cacheF serverF = loopThroughRightF (absF (cacheSP [] [])) serverF cacheSP cache pending = getSP $ either answerFromServerSP requestFromClientSP where requestFromClientSP (n,req) = -- A request from client n. assoc oldSP newSP cache req where oldSP ans = -- The answer was found in the cache. putSP (Right (n,(req,ans))) $ cacheSP cache pending newSP = -- A new request, send it to the server, and -- add the client to the pending list. if req `elem` map snd pending then cont else putSP (Left req) cont where cont = cacheSP cache ((n,req):pending) answerFromServerSP ans@(req,_) = -- The server delivered an answer to request req, -- save it in the cache, -- forward it to waiting clients and remove them from -- the pending list. putsSP [Right (n,ans) | (n,_)<-ready] $ cacheSP (ans:cache) pending' where (ready,pending') = part ((==req).snd) pendingFigure 89. The fudget cacheF.
urlFetchF does not output anything
until it has received the complete document.urlFetchF was changed to output chunks as they
are received, you would have to concatenate all the pieces
before you apply the function parseHtml to it.htmlDisplayF is implemented with graphicsF. When graphicsF receives a new drawing to
display, it computes its size and adjusts the window size
accordingly before it draws anything in the window. This means
that it needs the complete drawing before it can display
anything.urlFetchF output a response containing the
document as a lazy list of characters as soon as it begins
receiving it from the server. This would allow you to apply the
parser and the drawing function immediately and send the
resulting drawing to graphicsF. The parser parseHtml and drawing function drawHtmlDoc must be
carefully constructed to be lazy enough to produce some output
even when only an initial fragment of the input is available.
You would also have to change graphicsF so that it does not
start by computing the size of the drawing. It should instead
lazily compute drawing commands (see Section 27.2) to send
to the window system. The size of the window should be adjusted
regularly according to where the drawing commands generated so
far have drawn.
The above solution seems to require the introduction of some mechanism for indeterministic choice, since while the drawing commands for the document are being computed and output, the program should to continue to react to other input.
However, the trend in I/O systems for functional languages goes towards making I/O operations more explicit. Even the Fudget library has abandoned the representation of streams as lazy lists in favour of a simpler deterministic implementation. Using a lazy list for input as above is thus a step in the opposite direction. However, to program indeterministic systems on a high level of abstraction, streams as lazy lists seem to be useful.
One can of course think of ways of achieving incremental display without doing input in the form of lazy lists.
urlFetchF output chunks of characters as
they become available. parseHtml would then be SP String Html instead of String -> Html. However, we will not achieve incremental
display if we continue to output the syntax tree of whole
document in one message. We would instead have to output a
sequence of document fragments.htmlDisplayF would be document
fragments instead of complete document. We are thus moving one step in
the direction of an HTML editor instead of a simple display.The conclusion we draw from this is that the current I/O system in Haskell does not integrate well with laziness.